Clear Sky Science · es
GoLoCo-Net: red de atención contextual guiada global-local para la segmentación de imágenes médicas
Ver el interior del cuerpo con mayor claridad
Los médicos dependen cada vez más de las exploraciones por RM y TC para entender cómo se mueven y cambian nuestros órganos con el tiempo, desde el corazón que late hasta la lengua en movimiento durante el habla. Pero para transformar estas imágenes en escala de grises en mapas anatómicos claros y codificados por color, los ordenadores deben delinear con precisión cada estructura, una tarea conocida como segmentación. Este artículo presenta GoLoCo-Net, un nuevo método de inteligencia artificial que hace esos contornos más nítidos y fiables en distintos tipos de exploraciones médicas, con potencial para mejorar el diagnóstico, la planificación del tratamiento y la investigación sobre el funcionamiento del cuerpo.
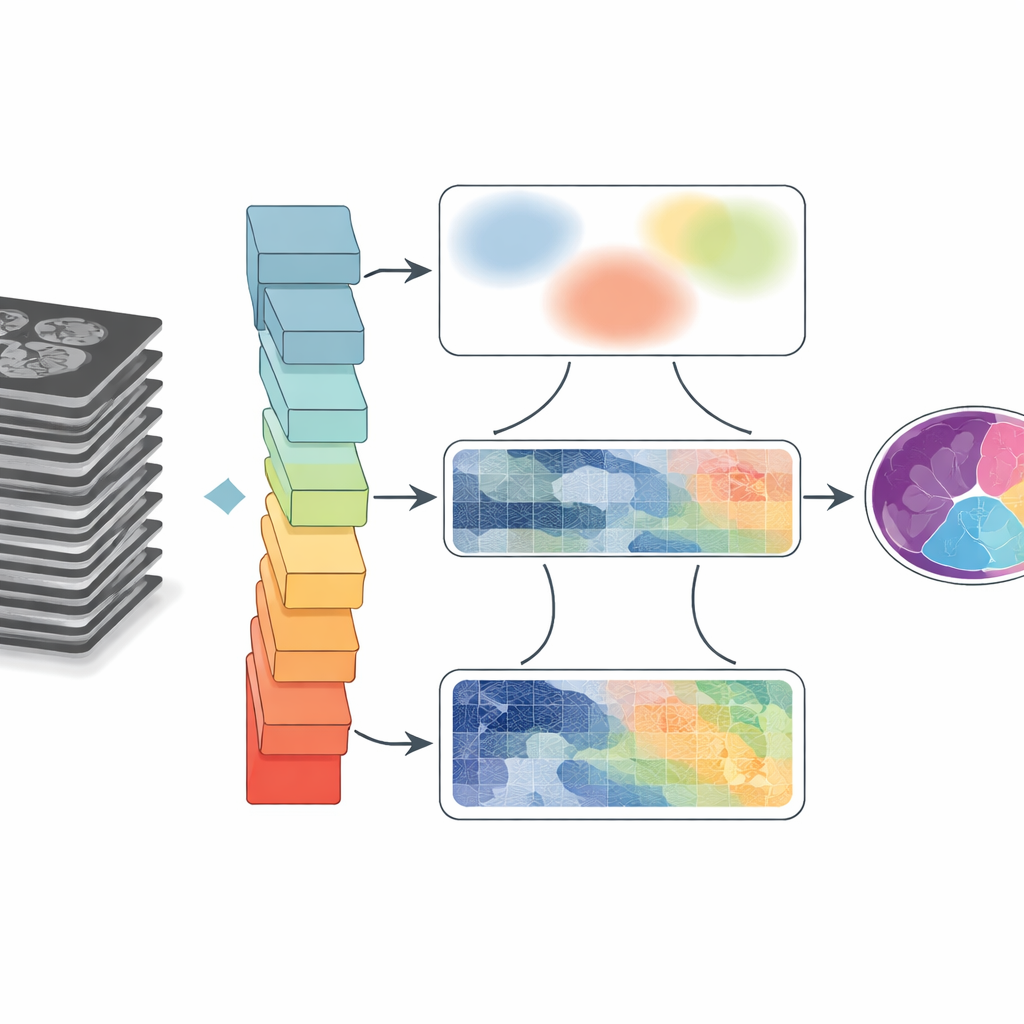
Por qué es tan difícil trazar límites en las exploraciones
Las imágenes médicas son complejas. Los órganos se tocan o se solapan, los bordes pueden verse difusos y el movimiento o las limitaciones del equipo introducen desenfoque y artefactos. Los programas tradicionales agrupan píxeles según reglas simples, que a menudo fallan cuando las estructuras son pequeñas o tienen bajo contraste. El aprendizaje profundo ha mejorado mucho el rendimiento al permitir que las redes neuronales aprendan patrones directamente de grandes conjuntos de datos. Sin embargo, los diseños habituales o bien se centran en vecindarios pequeños de píxeles, perdiendo conexiones a larga distancia, o bien se amplían para ver el panorama general pero pierden detalle fino en los límites. Este compromiso se vuelve crítico cuando los médicos necesitan formas y tamaños precisos, por ejemplo para medir las cámaras del corazón o seguir el movimiento de la lengua tras una intervención.
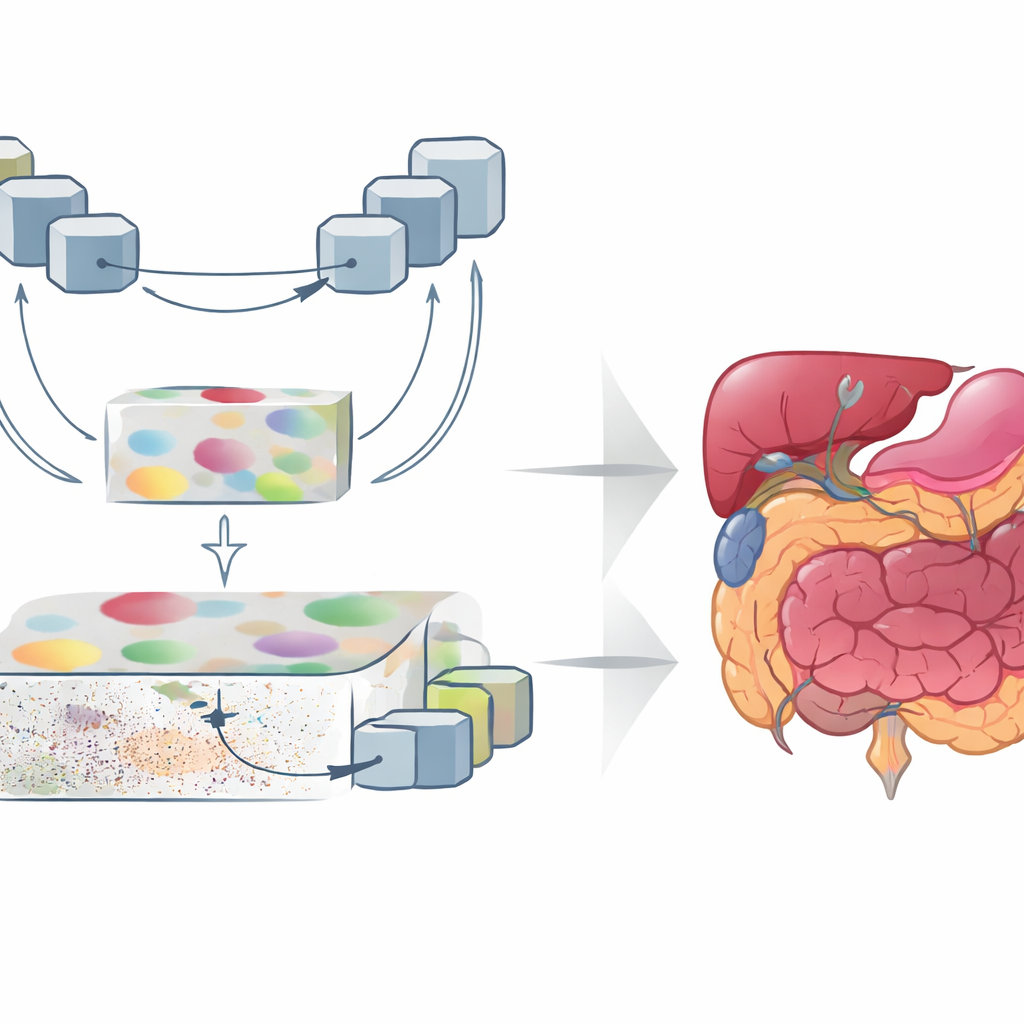
Combinar panorama general y detalle fino
GoLoCo-Net está diseñado para capturar tanto el amplio contexto de una imagen como los detalles minúsculos en sus bordes. En su núcleo se encuentra un codificador «transformador de visión» moderno que analiza la exploración completa a la vez, aprendiendo cómo se relacionan regiones distantes entre sí. Sobre esto, los autores construyen dos ramas de decodificación separadas. Una rama se centra en la comprensión de alto nivel: qué estructuras están presentes y cómo se organizan. La otra preserva la información de bajo nivel, como la textura y los límites nítidos. En lugar de limitarse a coser estas visiones, GoLoCo-Net utiliza módulos de atención cuidadosamente diseñados para que la información global pueda guiar el detalle local y, a su vez, las señales locales afinen la visión global.
Cómo modelan la vista los nuevos módulos
El primer módulo clave, llamado Realce de Características con Atención Contextual, enriquece la representación de alto nivel. Encamina las características abstractas a través de un bloque en forma de U que reduce y agranda repetidamente la representación de la imagen, permitiendo a la red mirar las estructuras a múltiples escalas. Los mecanismos de atención resaltan las regiones que importan y modulan la tendencia de los transformadores a dispersar el foco con demasiada amplitud, lo que puede difuminar los límites de los órganos. El segundo módulo, Característica Global-Guía-Local, parte del lado opuesto: toma información detallada de bordes y texturas de capas superficiales y usa una señal global de capas profundas para filtrar el ruido y el fondo. Bloques de atención adicionales enfatizan canales y regiones espaciales importantes, de modo que los órganos pequeños y las estructuras delgadas se preservan sin quedar ahogados por el desorden.
Demostrar que funciona en distintos órganos y aparatos
Para evaluar GoLoCo-Net, los investigadores lo probaron en tres conjuntos de datos muy diferentes. Uno captura el tracto vocal en movimiento durante RM del habla, donde la lengua, el velo del paladar y los tejidos circundantes se mueven rápido y son propensos a desenfoque y artefactos de imagen. El segundo contiene exploraciones cardiacas por RM usadas para medir las cámaras y el músculo del corazón. El tercero es un conjunto de TC de múltiples órganos abdominales, incluidos hígado, riñones y páncreas. En los tres, GoLoCo-Net superó a varios modelos líderes basados en convoluciones y en transformadores, logrando mayores índices de solapamiento con los contornos trazados por expertos y mejor preservación de las formas anatómicas. Se mantuvo robusto incluso cuando se añadió ruido adicional, lo que sugiere que puede manejar datos imperfectos del mundo real.
Qué significa esto para pacientes y clínicos
En términos prácticos, GoLoCo-Net ofrece una forma más fiable de convertir exploraciones crudas en mapas precisos de anatomía. Para radiólogos y cirujanos, eso puede traducirse en mediciones más limpias y consistentes de órganos y tumores. Para científicos del habla y clínicos, puede proporcionar vistas cuadro a cuadro más claras de cómo se mueven la lengua y el velo del paladar, sin trazados manuales laboriosos. Dado que los módulos clave están diseñados para integrarse en sistemas existentes, el enfoque podría adoptarse ampliamente a medida que la IA en imagen médica evolucione. La conclusión principal es simple: al enseñar a los ordenadores a equilibrar el panorama general con los detalles más finos, este trabajo nos acerca a una interpretación de imágenes médicas más rápida, precisa y robusta.
Cita: He, Y., Miquel, M.E. & Zhang, Q. GoLoCo-Net: global-local guided contextual attention network for medical images segmentation. Sci Rep 16, 12300 (2026). https://doi.org/10.1038/s41598-026-42415-0
Palabras clave: segmentación de imágenes médicas, RM, TC, aprendizaje profundo, transformador de visión