Clear Sky Science · de
GoLoCo-Net: global-local guided contextual attention network für die Segmentierung medizinischer Bilder
Den Körper klarer sehen
Ärztinnen und Ärzte verlassen sich zunehmend auf MRT- und CT-Scans, um zu verstehen, wie sich Organe im Zeitverlauf bewegen und verändern – vom schlagenden Herzen bis zur Zunge in Bewegung beim Sprechen. Damit aus diesen Graustufenbildern klare, farbkodierte Karten der Anatomie werden, müssen Computer jede Struktur präzise umreißen, eine Aufgabe, die als Segmentierung bekannt ist. Dieses Paper stellt GoLoCo-Net vor, eine neue KI-Methode, die diese Umrisse schärfer und zuverlässiger über verschiedene Arten medizinischer Scans hinweg macht und damit potenziell Diagnose, Therapieplanung und die Forschung zum Funktionieren des Körpers verbessert.
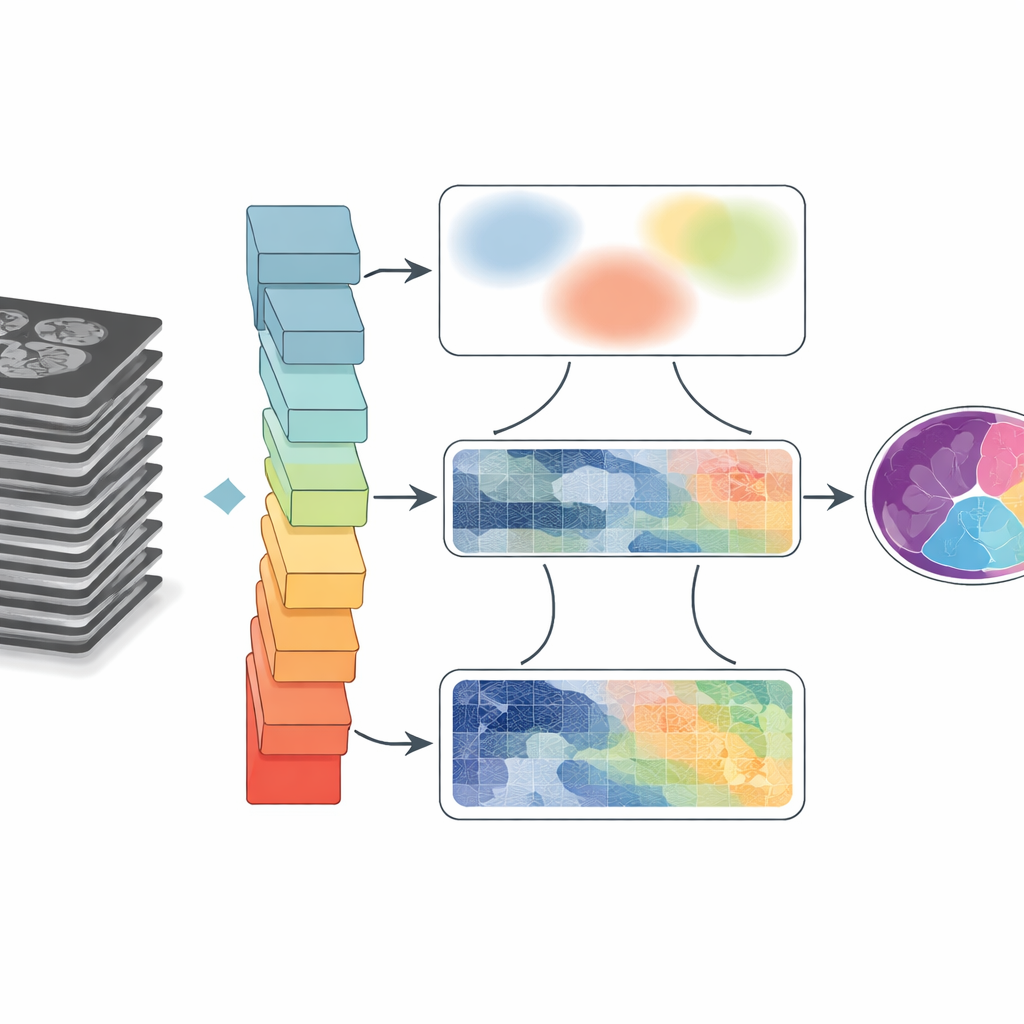
Warum das Ziehen von Grenzen in Scans so schwierig ist
Medizinische Bilder sind unordentlich. Organe berühren oder überlappen sich, Kanten können unscharf wirken, und Bewegung oder technische Einschränkungen führen zu Unschärfen und Artefakten. Traditionelle Computerprogramme gruppieren Pixel nach einfachen Regeln, die häufig versagen, wenn Strukturen klein sind oder nur geringen Kontrast aufweisen. Deep Learning hat die Leistung stark verbessert, weil neuronale Netze Muster direkt aus großen Datensätzen lernen können. Übliche Architekturen konzentrieren sich jedoch entweder auf kleine Pixelnachbarschaften und verpassen weite Zusammenhänge oder zoomen heraus, um das große Ganze zu sehen, verlieren dabei aber feinste Details an den Grenzen. Dieser Kompromiss wird kritisch, wenn Ärztinnen und Ärzte genaue Formen und Größen benötigen, etwa beim Vermessen von Herzkammern oder der Verfolgung der Zungenbewegung nach einer Operation.
Großes Ganzes und feine Details zusammenführen
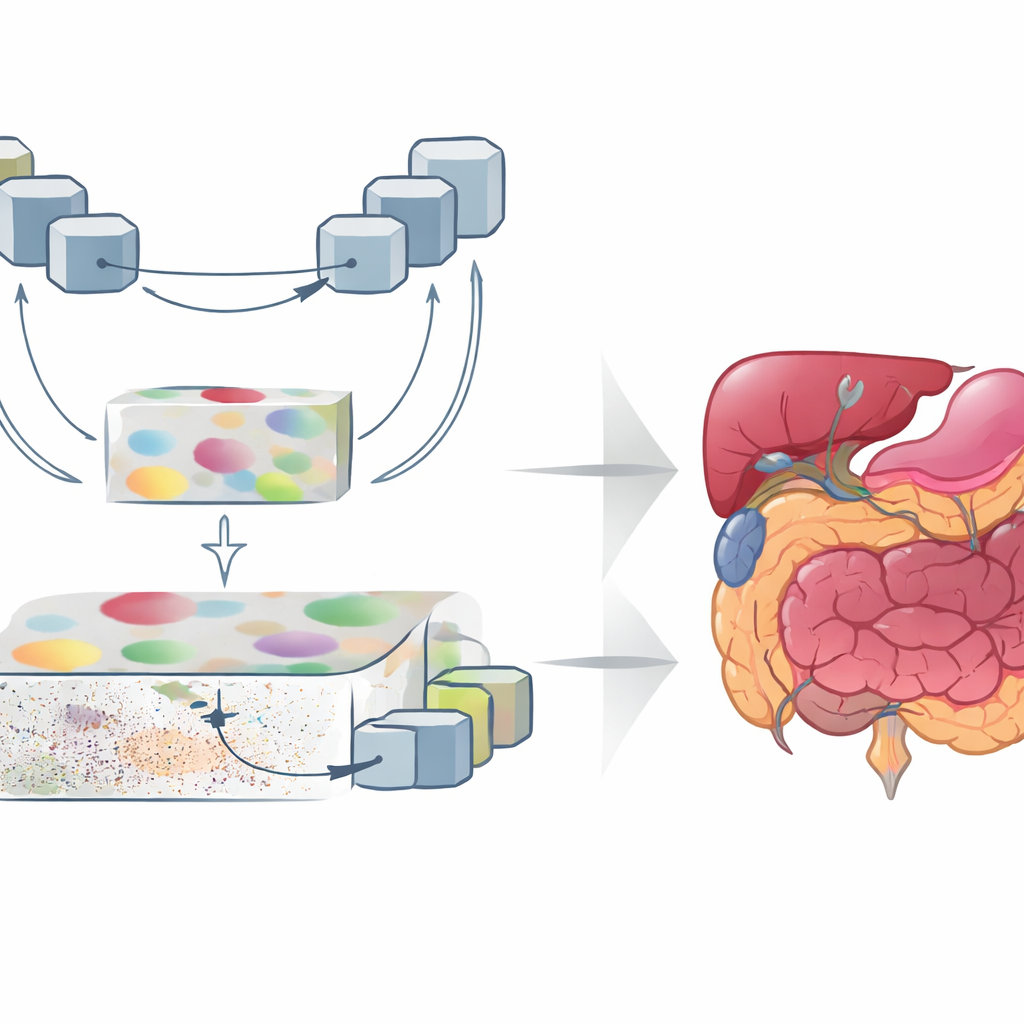
GoLoCo-Net ist so konzipiert, dass es sowohl den weiten Kontext eines Bildes als auch die winzigen Details an seinen Rändern erfasst. Im Kern steht ein moderner Vision-Transformer-Encoder, der den gesamten Scan auf einmal betrachtet und lernt, wie weit entfernte Bereiche zueinander in Beziehung stehen. Darauf aufbauend entwickeln die Autoren zwei separate Decodierungszweige. Ein Zweig fokussiert sich auf das hochrangige Verständnis: welche Strukturen vorhanden sind und wie sie angeordnet sind. Der andere bewahrt niederstufige Informationen wie Textur und scharfe Kanten. Anstatt diese Sichtweisen einfach zusammenzufügen, nutzt GoLoCo-Net sorgfältig gestaltete Attention-Module, sodass globale Informationen lokale Details leiten können und lokale Hinweise wiederum die globale Sicht schärfen.
Wie die neuen Module die Sicht formen
Das erste Schlüsselmodul, genannt Contextual Attention Feature Enhancement, bereichert die hochrangige Repräsentation. Es leitet die abstrakten Merkmale durch einen U-förmigen Block, der die Bildrepräsentation wiederholt verkleinert und vergrößert, sodass das Netzwerk Strukturen in mehreren Größenordnungen betrachten kann. Aufmerksamkeitsmechanismen heben dann die wichtigsten Bereiche hervor und dämpfen die Tendenz von Transformern, den Fokus zu breit zu streuen, was Organränder verwischen kann. Das zweite Modul, Global-Guide-Local Feature, beginnt von der gegenüberliegenden Seite: Es nimmt detaillierte Kanten- und Texturinformationen aus flachen Schichten und nutzt ein globales Signal aus tieferen Schichten, um Rauschen und Hintergrund zu filtern. Zusätzliche Attention-Blöcke betonen wichtige Kanäle und räumliche Regionen, sodass kleine Organe und dünne Strukturen erhalten bleiben, ohne von Störfaktoren überlagert zu werden.
Nachweis der Wirksamkeit über Organe und Scanner hinweg
Um GoLoCo-Net zu testen, evaluierten die Forschenden das Modell an drei sehr unterschiedlichen Datensätzen. Der erste bildet den Vokaltrakt in Bewegung bei Sprach-MRT ab, wo Zunge, Gaumensegel und umliegendes Gewebe schnell bewegen und zu Unschärfen und Bildartefakten neigen. Der zweite enthält kardiale MRT-Scans, die zur Vermessung der Herzkammern und -muskulatur dienen. Der dritte ist ein CT-Datensatz mehrerer abdominaler Organe, einschließlich Leber, Nieren und Pankreas. In allen drei Datensätzen übertraf GoLoCo-Net mehrere führende auf Convolutional Networks und Transformern basierende Modelle, erzielte höhere Überlappungswerte mit Expertenumrissen und bewahrte anatomische Formen besser. Es blieb auch bei zusätzlichem Rauschen robust, was darauf hindeutet, dass es mit unvollkommenen Realwelt-Daten umgehen kann.
Was das für Patientinnen, Patienten und Kliniker bedeutet
Praktisch bedeutet GoLoCo-Net eine zuverlässigere Methode, rohe Scans in präzise Anatomiekarten zu verwandeln. Für Radiologinnen, Radiologen und Chirurginnen und Chirurgen kann das sauberere, konsistentere Messungen von Organen und Tumoren bedeuten. Für Sprachwissenschaftlerinnen und -wissenschaftler sowie Therapeutinnen und Therapeuten liefert es klarere Einzelbild-zu-Einzelbild-Ansichten, wie sich Zunge und Gaumensegel bewegen, ohne mühsames manuelles Nachzeichnen. Da die Schlüsselmodule so gestaltet sind, dass sie sich in bestehende Systeme einfügen lassen, könnte der Ansatz weit verbreitet übernommen werden, während sich die Bildgebungs-KI weiterentwickelt. Die zentrale Botschaft ist einfach: Indem Computer gelehrt werden, das große Ganze mit feinsten Details auszubalancieren, rückt diese Arbeit uns näher an eine schnellere, genauere und robustere Interpretation medizinischer Bilder.
Zitation: He, Y., Miquel, M.E. & Zhang, Q. GoLoCo-Net: global-local guided contextual attention network for medical images segmentation. Sci Rep 16, 12300 (2026). https://doi.org/10.1038/s41598-026-42415-0
Schlüsselwörter: Segmentierung medizinischer Bilder, MRT, CT, Deep Learning, Vision Transformer