Clear Sky Science · pl
GoLoCo-Net: global-local guided contextual attention network for medical images segmentation
Lepszy wgląd wewnątrz ciała
Lekarze coraz częściej polegają na skanach MRI i CT, aby zrozumieć, jak narządy poruszają się i zmieniają w czasie — od bijącego serca po język w ruchu podczas mowy. Aby jednak przekształcić te obrazy w odcieniach szarości w wyraźne, kolorystycznie oznakowane mapy anatomiczne, komputery muszą precyzyjnie wyznaczyć kontury każdego elementu — zadanie zwane segmentacją. W artykule przedstawiono GoLoCo-Net, nową metodę sztucznej inteligencji, która sprawia, że te kontury są ostrzejsze i bardziej niezawodne w różnych typach badań obrazowych, co może poprawić diagnostykę, planowanie leczenia oraz badania nad funkcjonowaniem ciała.
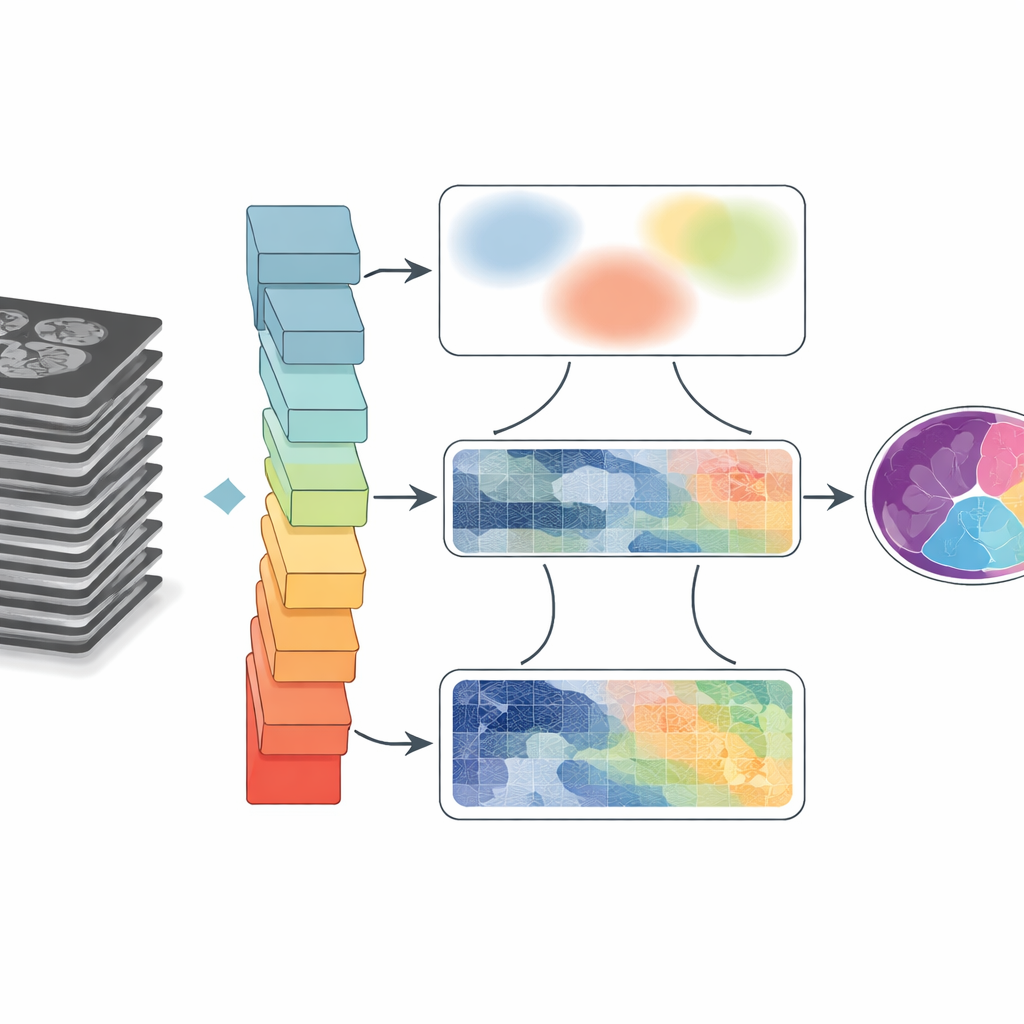
Dlaczego wyznaczanie granic na skanach jest tak trudne
Obrazy medyczne są złożone. Narządy stykają się lub nachodzą na siebie, krawędzie mogą być nieostre, a ruch lub ograniczenia sprzętowe wprowadzają rozmycia i artefakty. Tradycyjne programy grupują piksele na podstawie prostych reguł, które często zawodzą, gdy struktury są małe lub mają słaby kontrast. Uczenie głębokie znacznie poprawiło wyniki, pozwalając sieciom neuronowym uczyć się wzorców bezpośrednio z dużych zbiorów danych. Jednak typowe architektury albo koncentrują się na małych sąsiedztwach pikseli, tracąc długodystansowe powiązania, albo „oddalają się”, żeby objąć szerszy kontekst, kosztem utraty detali przy granicach. Ten kompromis staje się krytyczny, gdy lekarze potrzebują dokładnych kształtów i rozmiarów, na przykład do pomiaru komór serca czy śledzenia ruchu języka po operacji.
Łączenie całościowego obrazu i drobnych szczegółów
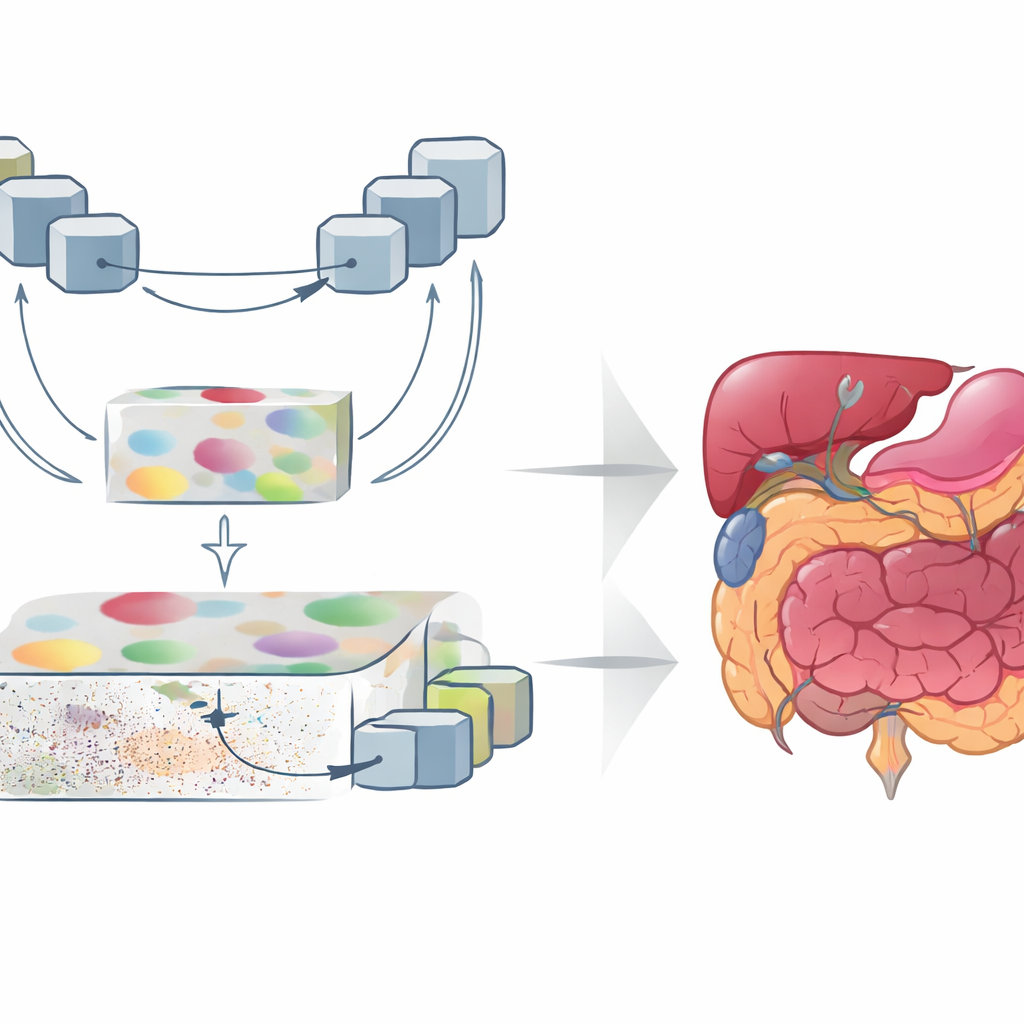
GoLoCo-Net został zaprojektowany tak, aby uchwycić zarówno szeroki kontekst obrazu, jak i drobne detale przy krawędziach. W rdzeniu znajduje się nowoczesny enkoder typu „vision transformer”, który ogląda cały skan naraz i uczy się, jak odległe obszary odnoszą się do siebie. Na jego podstawie autorzy zbudowali dwie oddzielne gałęzie dekodera. Jedna gałąź koncentruje się na zrozumieniu na wysokim poziomie: jakie struktury występują i jak są ułożone. Druga zachowuje informacje niskiego poziomu, takie jak tekstura i ostre granice. Zamiast prostego scalenia tych widoków, GoLoCo-Net wykorzystuje starannie zaprojektowane moduły uwagi, dzięki czemu informacja globalna może kierować detalami lokalnymi, a sygnały lokalne z kolei mogą wyszczuplać i uwypuklać widok globalny.
Jak nowe moduły modelują obraz
Pierwszy kluczowy moduł, nazwany Contextual Attention Feature Enhancement, wzbogaca reprezentację wysokiego poziomu. Kieruje abstrakcyjne cechy przez blok w kształcie litery U, który wielokrotnie zmniejsza i powiększa reprezentację obrazu, pozwalając sieci oglądać struktury w różnych skalach. Mechanizmy uwagi podkreślają następnie regiony mające największe znaczenie i tłumią tendencję transformerów do zbyt szerokiego rozprzestrzeniania fokusowania, co może rozmywać granice narządów. Drugi moduł, Global-Guide-Local Feature, zaczyna od przeciwnej strony: pobiera szczegółowe informacje o krawędziach i teksturze z płytkich warstw i wykorzystuje sygnał globalny z głębszych warstw do odfiltrowania szumu i tła. Dodatkowe bloki uwagi akcentują ważne kanały i obszary przestrzenne, tak aby małe narządy i cienkie struktury zachowały się bez bycia zagłuszonymi przez nieistotne elementy.
Dowody skuteczności na różnych narządach i skanerach
Aby przetestować GoLoCo-Net, badacze ocenili go na trzech bardzo różnych zestawach danych. Jeden rejestruje tor głosowy w ruchu podczas MRI mowy, gdzie język, podniebienie miękkie i otaczające tkanki poruszają się szybko i są podatne na rozmycia oraz artefakty obrazowe. Drugi zawiera obrazowanie MRI serca służące do pomiaru jam i mięśnia sercowego. Trzeci to zbiór CT obejmujący wiele narządów jamy brzusznej, w tym wątrobę, nerki i trzustkę. We wszystkich trzech przypadkach GoLoCo-Net przewyższył kilka wiodących modeli opartych na konwolucjach i transformerach, osiągając wyższe wskaźniki nakładania z konturami rysowanymi przez ekspertów oraz lepsze zachowanie kształtów anatomicznych. Pozostał odporny nawet po dodaniu dodatkowego szumu, co sugeruje, że poradzi sobie z niedoskonałymi, rzeczywistymi danymi.
Co to oznacza dla pacjentów i klinicystów
W praktyce GoLoCo-Net oferuje bardziej niezawodny sposób przekształcania surowych skanów w precyzyjne mapy anatomii. Dla radiologów i chirurgów może to oznaczać czyściejsze, bardziej spójne pomiary narządów i guzów. Dla badaczy mowy i klinicystów może to dostarczyć wyraźniejszych, klatka po klatce widoków ruchu języka i podniebienia miękkiego, bez czasochłonnego ręcznego odrysowywania. Ponieważ kluczowe moduły zaprojektowano tak, by można je było wpiąć w istniejące systemy, podejście to może być szeroko przyjęte w miarę rozwoju AI w obrazowaniu. Główny wniosek jest prosty: ucząc komputery równoważyć obraz całościowy z najdrobniejszymi szczegółami, ta praca przybliża nas do szybszej, dokładniejszej i bardziej odpornej interpretacji obrazów medycznych.
Cytowanie: He, Y., Miquel, M.E. & Zhang, Q. GoLoCo-Net: global-local guided contextual attention network for medical images segmentation. Sci Rep 16, 12300 (2026). https://doi.org/10.1038/s41598-026-42415-0
Słowa kluczowe: segmentacja obrazów medycznych, MRI, CT, uczenie głębokie, transformer w wizji