Clear Sky Science · fr
GoLoCo-Net : réseau d’attention contextuelle guidée global-local pour la segmentation d’images médicales
Voir l’intérieur du corps plus clairement
Les médecins s’appuient de plus en plus sur les images IRM et CT pour comprendre comment nos organes se déplacent et évoluent dans le temps, du cœur battant à la langue en mouvement lors de la parole. Mais pour transformer ces images en niveaux de gris en cartes anatomiques claires et codées par couleur, les ordinateurs doivent délimiter précisément chaque structure, une tâche appelée segmentation. Cet article présente GoLoCo-Net, une nouvelle méthode d’intelligence artificielle qui rend ces contours plus nets et plus fiables sur différents types d’examens médicaux, améliorant potentiellement le diagnostic, la planification des traitements et la recherche sur le fonctionnement du corps.
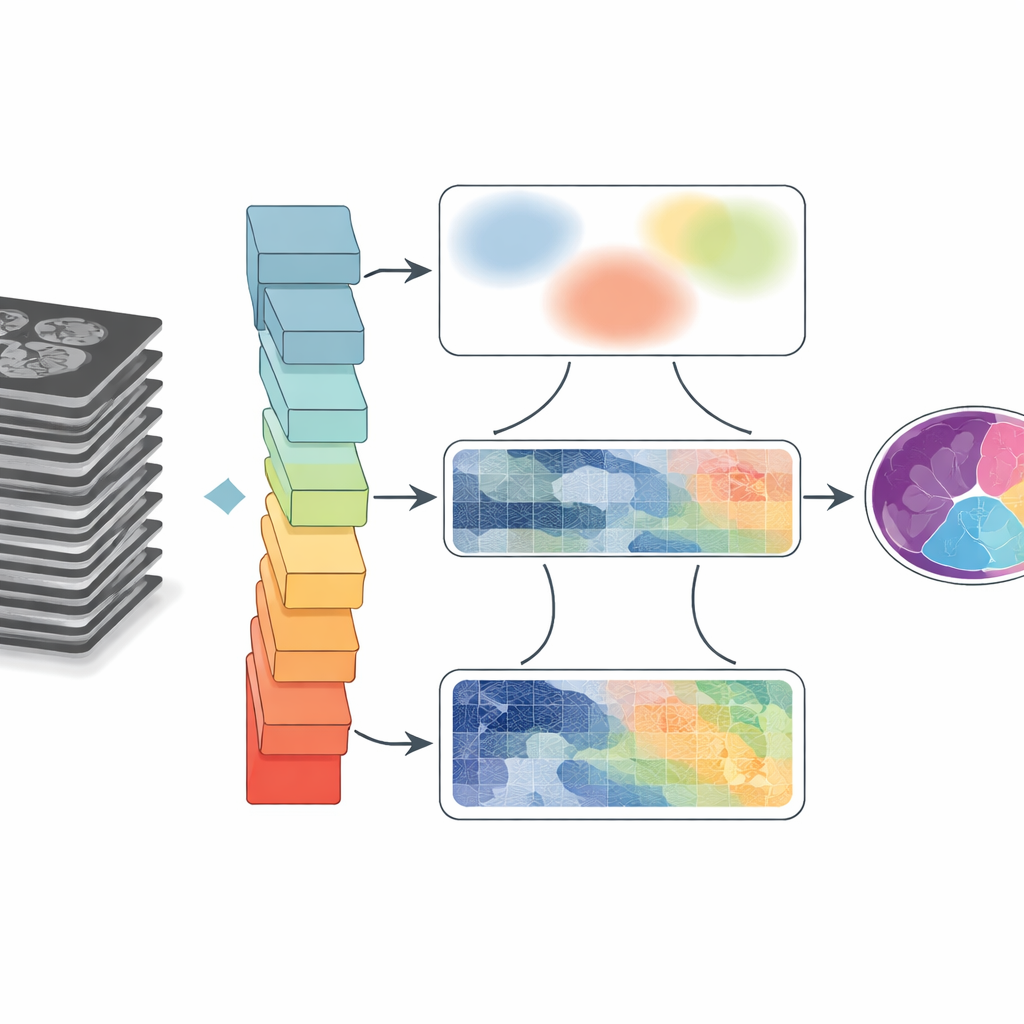
Pourquoi tracer des frontières dans les scans est si difficile
Les images médicales sont désordonnées. Les organes se touchent ou se superposent, les bords peuvent paraître flous, et le mouvement ou les limites matérielles introduisent du flou et des artéfacts. Les programmes traditionnels regroupent les pixels selon des règles simples, qui échouent souvent quand les structures sont petites ou à faible contraste. L’apprentissage profond a grandement amélioré les performances en permettant aux réseaux neuronaux d’apprendre des motifs directement à partir de larges jeux de données. Cependant, les architectures communes se concentrent soit sur de petits voisinages de pixels, manquant les connexions à longue distance, soit s’élargissent pour voir le contexte global au prix de la perte de détails fins au niveau des frontières. Ce compromis devient critique lorsque les cliniciens ont besoin de formes et de tailles exactes, par exemple pour mesurer les cavités cardiaques ou suivre le mouvement de la langue après une intervention.
Mélanger vision d’ensemble et détails fins
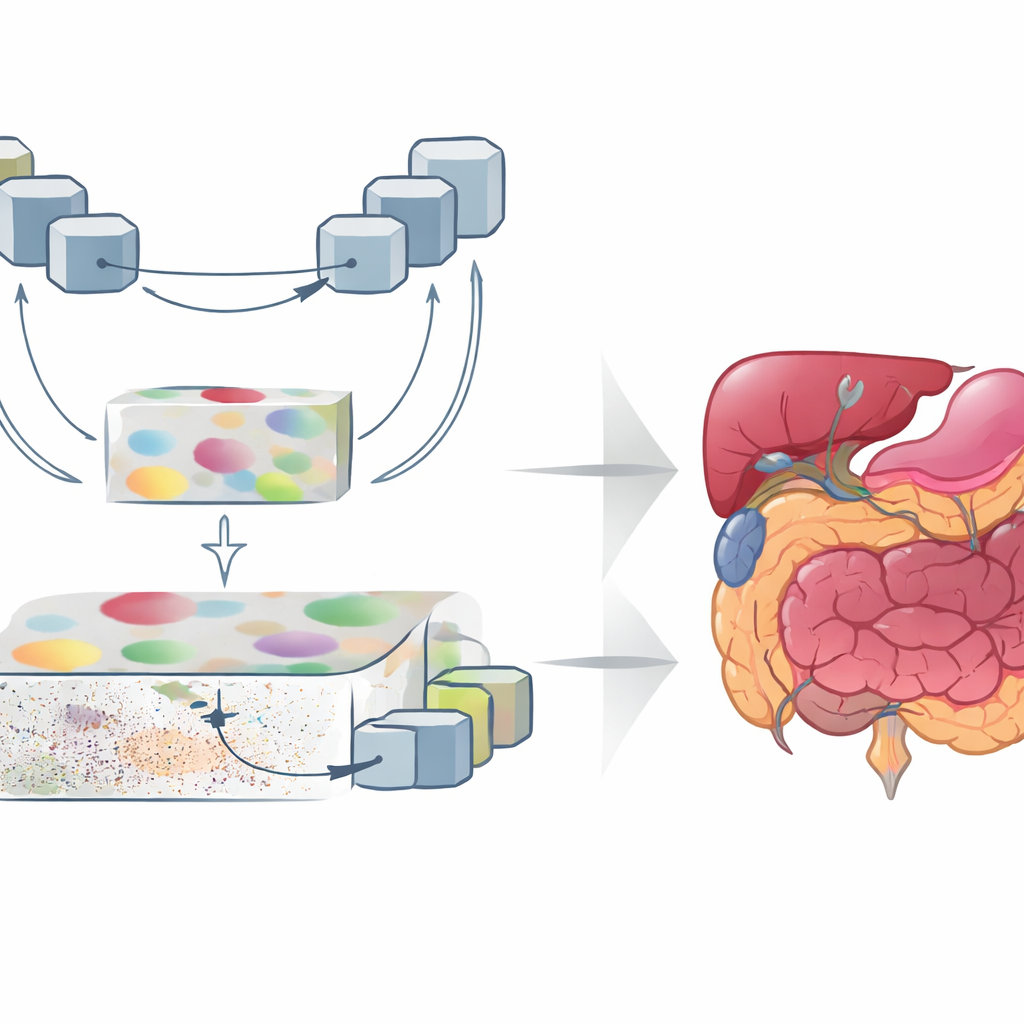
GoLoCo-Net est conçu pour capturer à la fois le contexte large d’une image et les minuscules détails à ses marges. En son cœur se trouve un encodeur « vision transformer » moderne qui analyse l’ensemble du scan en une fois, apprenant comment des régions distantes se rapportent les unes aux autres. Sur cette base, les auteurs construisent deux branches de décodage séparées. Une branche se concentre sur la compréhension de haut niveau : quelles structures sont présentes et comment elles sont disposées. L’autre préserve l’information de bas niveau comme la texture et les contours nets. Plutôt que de simplement assembler ces vues, GoLoCo-Net utilise des modules d’attention soigneusement conçus afin que l’information globale puisse guider le détail local et, en retour, que les indices locaux affinent la vue globale.
Comment les nouveaux modules influencent la perception
Le premier module clé, nommé Contextual Attention Feature Enhancement, enrichit la représentation de haut niveau. Il fait transiter les caractéristiques abstraites à travers un bloc en forme de U qui réduit et agrandit à plusieurs reprises la représentation de l’image, permettant au réseau d’examiner les structures à différentes échelles. Des mécanismes d’attention mettent ensuite en relief les régions les plus importantes et atténuent la tendance des transformers à répartir leur attention trop largement, ce qui peut estomper les limites des organes. Le deuxième module, Global-Guide-Local Feature, part du côté opposé : il prend l’information détaillée sur les bords et la texture provenant des couches superficielles et utilise un signal global issu des couches profondes pour filtrer le bruit et l’arrière-plan. Des blocs d’attention supplémentaires soulignent les canaux et les régions spatiales importantes, de sorte que les petits organes et les structures fines sont préservés sans être noyés par le désordre environnant.
Preuves d’efficacité sur plusieurs organes et appareils
Pour évaluer GoLoCo-Net, les chercheurs l’ont testé sur trois jeux de données très différents. Le premier capture le tractus vocal en mouvement lors d’IRM de parole, où la langue, le voile du palais et les tissus environnants bougent rapidement et sont sujets au flou et aux artéfacts d’imagerie. Le second contient des IRM cardiaques utilisées pour mesurer les cavités et le muscle du cœur. Le troisième est un jeu de données CT d’organes abdominaux multiples, incluant le foie, les reins et le pancréas. Sur les trois, GoLoCo-Net a surpassé plusieurs modèles convolutionnels et basés sur des transformers de pointe, obtenant des scores de recouvrement plus élevés avec les contours tracés par des experts et une meilleure préservation des formes anatomiques. Il est resté robuste même lorsque du bruit supplémentaire était ajouté, ce qui suggère qu’il peut traiter des données imparfaites issues du monde réel.
Quelles implications pour les patients et les cliniciens
Concrètement, GoLoCo-Net offre une manière plus fiable de transformer des scans bruts en cartes anatomiques précises. Pour les radiologues et les chirurgiens, cela peut signifier des mesures d’organes et de tumeurs plus nettes et plus cohérentes. Pour les chercheurs et cliniciens en parole, cela peut fournir des vues image par image plus claires du mouvement de la langue et du voile du palais, sans tracé manuel laborieux. Parce que les modules clés sont conçus pour s’intégrer dans des systèmes existants, l’approche pourrait être largement adoptée à mesure que l’IA en imagerie évolue. La leçon principale est simple : en apprenant aux ordinateurs à équilibrer la vue d’ensemble et les détails les plus fins, ce travail nous rapproche d’une interprétation des images médicales plus rapide, plus précise et plus robuste.
Citation: He, Y., Miquel, M.E. & Zhang, Q. GoLoCo-Net: global-local guided contextual attention network for medical images segmentation. Sci Rep 16, 12300 (2026). https://doi.org/10.1038/s41598-026-42415-0
Mots-clés: segmentation d’images médicales, IRM, CT, apprentissage profond, vision transformer