Clear Sky Science · pt
GoLoCo-Net: rede de atenção contextual guiada global-local para segmentação de imagens médicas
Ver o Interior do Corpo com Mais Clareza
Médicos cada vez mais dependem de exames de RM e TC para entender como nossos órgãos se movem e mudam ao longo do tempo, desde o coração batendo até a língua em movimento durante a fala. Mas, para transformar essas imagens em tons de cinza em mapas claros e codificados por cores da anatomia, os computadores precisam delinear cada estrutura com precisão — uma tarefa conhecida como segmentação. Este artigo apresenta o GoLoCo-Net, um novo método de inteligência artificial que torna esses contornos mais nítidos e confiáveis em diferentes tipos de exames médicos, potencialmente melhorando o diagnóstico, o planejamento do tratamento e a pesquisa sobre o funcionamento do corpo.
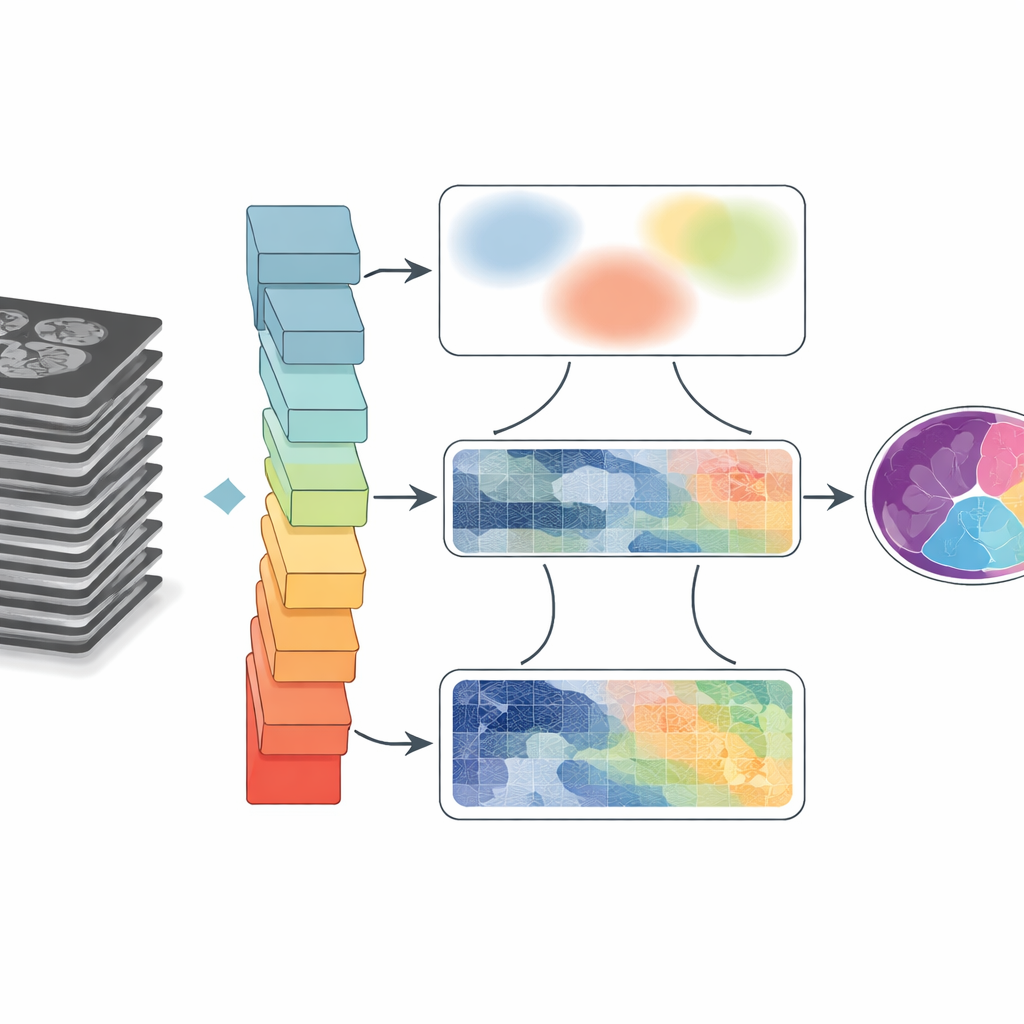
Por Que Desenhar Limites em Exames É Tão Difícil
Imagens médicas são confusas. Órgãos se tocam ou se sobrepõem, bordas podem ficar borradas, e movimento ou limitações do equipamento introduzem desfoque e artefatos. Programas tradicionais agrupam pixels com base em regras simples, que frequentemente falham quando estruturas são pequenas ou têm baixo contraste. O aprendizado profundo melhorou muito o desempenho ao permitir que redes neurais aprendam padrões diretamente de grandes conjuntos de dados. No entanto, arquiteturas comuns ou se concentram em vizinhanças pequenas de pixels, perdendo conexões de longo alcance, ou ampliam a visão para o quadro geral, mas perdem detalhes finos nas bordas. Essa troca torna-se crítica quando médicos precisam de formas e tamanhos precisos, como medir câmaras cardíacas ou rastrear o movimento da língua após cirurgia.
Misturando Visão Geral e Detalhe Fino
O GoLoCo-Net foi projetado para capturar tanto o contexto amplo de uma imagem quanto os pequenos detalhes em suas bordas. No núcleo dele está um codificador moderno do tipo "vision transformer" que vê todo o exame de uma vez, aprendendo como regiões distantes se relacionam. Sobre isso, os autores constroem dois ramos de decodificação separados. Um ramo foca no entendimento de alto nível: que estruturas estão presentes e como elas se organizam. O outro preserva informações de baixo nível, como textura e contornos nítidos. Em vez de simplesmente costurar essas visões, o GoLoCo-Net usa módulos de atenção cuidadosamente desenhados para que a informação global possa guiar o detalhe local e, por sua vez, pistas locais possam afinar a visão global.
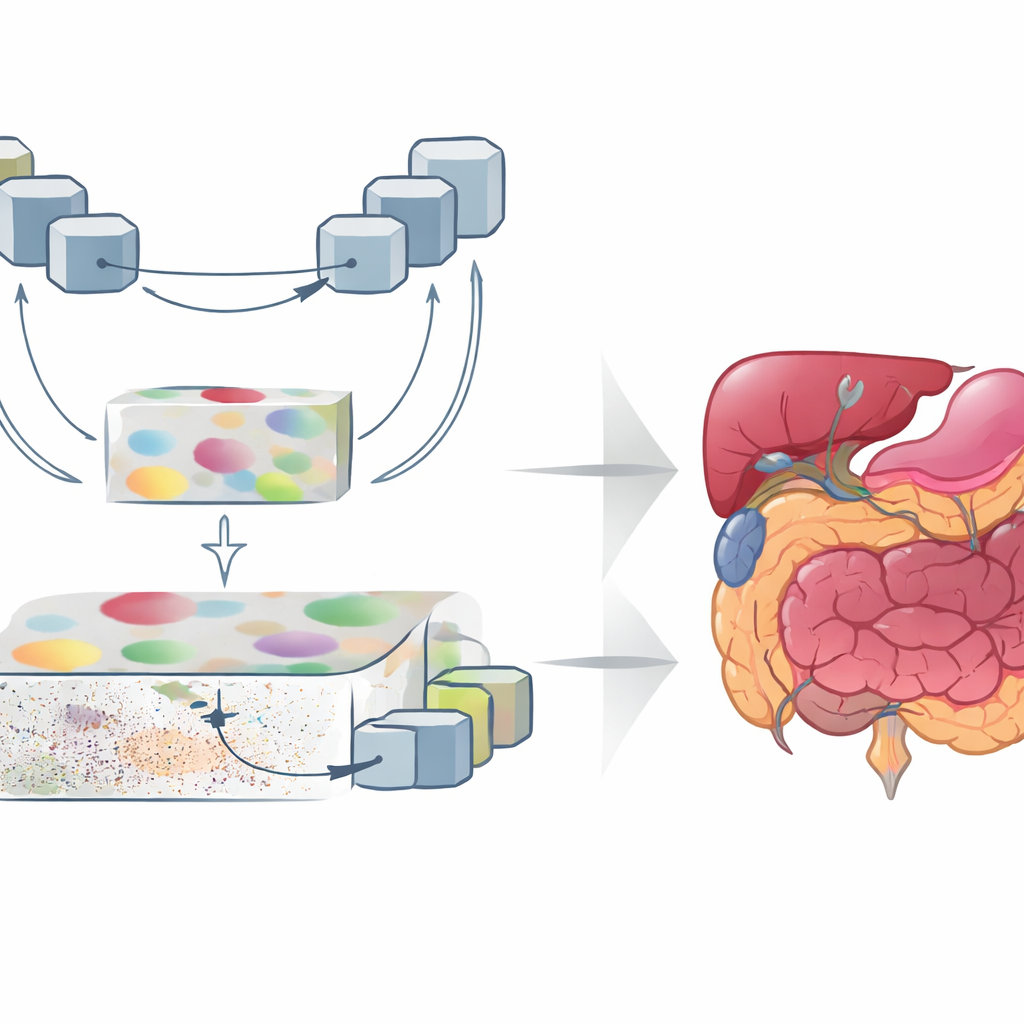
Como os Novos Módulos Modelam a Visão
O primeiro módulo chave, chamado Aperfeiçoamento de Recursos por Atenção Contextual, enriquece a representação de alto nível. Ele direciona as características abstratas através de um bloco em formato de U que repetidamente reduz e aumenta a representação da imagem, permitindo que a rede observe estruturas em múltiplas escalas. Mecanismos de atenção então destacam regiões que importam mais e atenuam a tendência dos transformers de espalhar o foco excessivamente, o que pode borrar as bordas dos órgãos. O segundo módulo, Recurso Global-Guia-Local, parte do lado oposto: ele captura informações detalhadas de bordas e textura das camadas rasas e usa um sinal global de camadas mais profundas para filtrar ruído e fundo. Blocos adicionais de atenção enfatizam canais e regiões espaciais importantes, de modo que órgãos pequenos e estruturas finas são preservados sem serem sufocados por ruído.
Comprovando que Funciona em Diferentes Órgãos e Aparelhos
Para testar o GoLoCo-Net, os pesquisadores o avaliaram em três conjuntos de dados bastante distintos. Um captura o trato vocal em movimento durante RM de fala, onde a língua, o palato mole e os tecidos circundantes se movem rapidamente e são propensos a desfoque e artefatos de imagem. O segundo contém exames de RM cardíaca usados para medir as câmaras e o músculo do coração. O terceiro é um conjunto de TC de múltiplos órgãos abdominais, incluindo fígado, rins e pâncreas. Em todos os três, o GoLoCo-Net superou vários modelos líderes baseados em convolução e em transformers, alcançando maiores escores de sobreposição com contornos desenhados por especialistas e melhor preservação das formas anatômicas. Manteve-se robusto mesmo quando ruído extra foi adicionado, sugerindo que pode lidar com dados imperfeitos do mundo real.
O Que Isso Significa para Pacientes e Clínicos
Em termos práticos, o GoLoCo-Net oferece uma maneira mais confiável de transformar exames brutos em mapas precisos da anatomia. Para radiologistas e cirurgiões, isso pode significar medições mais limpas e consistentes de órgãos e tumores. Para cientistas da fala e clínicos, pode fornecer visões quadro a quadro mais claras de como a língua e o palato mole se movem, sem rastreamento manual trabalhoso. Como os módulos principais foram projetados para se integrar a sistemas existentes, a abordagem pode ser adotada amplamente à medida que a IA em imagem médica evolui. A conclusão principal é simples: ao ensinar computadores a equilibrar a visão geral com os detalhes mais finos, este trabalho nos aproxima de uma interpretação de imagens médicas mais rápida, precisa e robusta.
Citação: He, Y., Miquel, M.E. & Zhang, Q. GoLoCo-Net: global-local guided contextual attention network for medical images segmentation. Sci Rep 16, 12300 (2026). https://doi.org/10.1038/s41598-026-42415-0
Palavras-chave: segmentação de imagem médica, RM, TC, aprendizado profundo, vision transformer