Clear Sky Science · ar
GoLoCo-Net: شبكة الانتباه السياقي الموجهة عالميًا ومحليًا لتجزئة الصور الطبية
رؤية أعمق داخل الجسم
يعتمد الأطباء بشكل متزايد على صور الرنين المغناطيسي والتصوير المقطعي لفهم كيفية تحرك أعضائنا وتغيرها مع الزمن، من القلب النابض إلى اللسان أثناء النطق. لكن لتحويل هذه الصور الرمادية إلى خرائط ملونة واضحة للتشريح، يجب على الحواسيب تحديد حدود كل بنية بدقة، وهو ما يُعرف بالتجزئة. تقدم هذه الورقة GoLoCo-Net، طريقة ذكاء اصطناعي جديدة تجعل تلك الحدود أوضح وأكثر موثوقية عبر أنواع مختلفة من الفحوصات الطبية، مما قد يحسّن التشخيص وتخطيط العلاج والبحوث حول كيفية عمل الجسم.
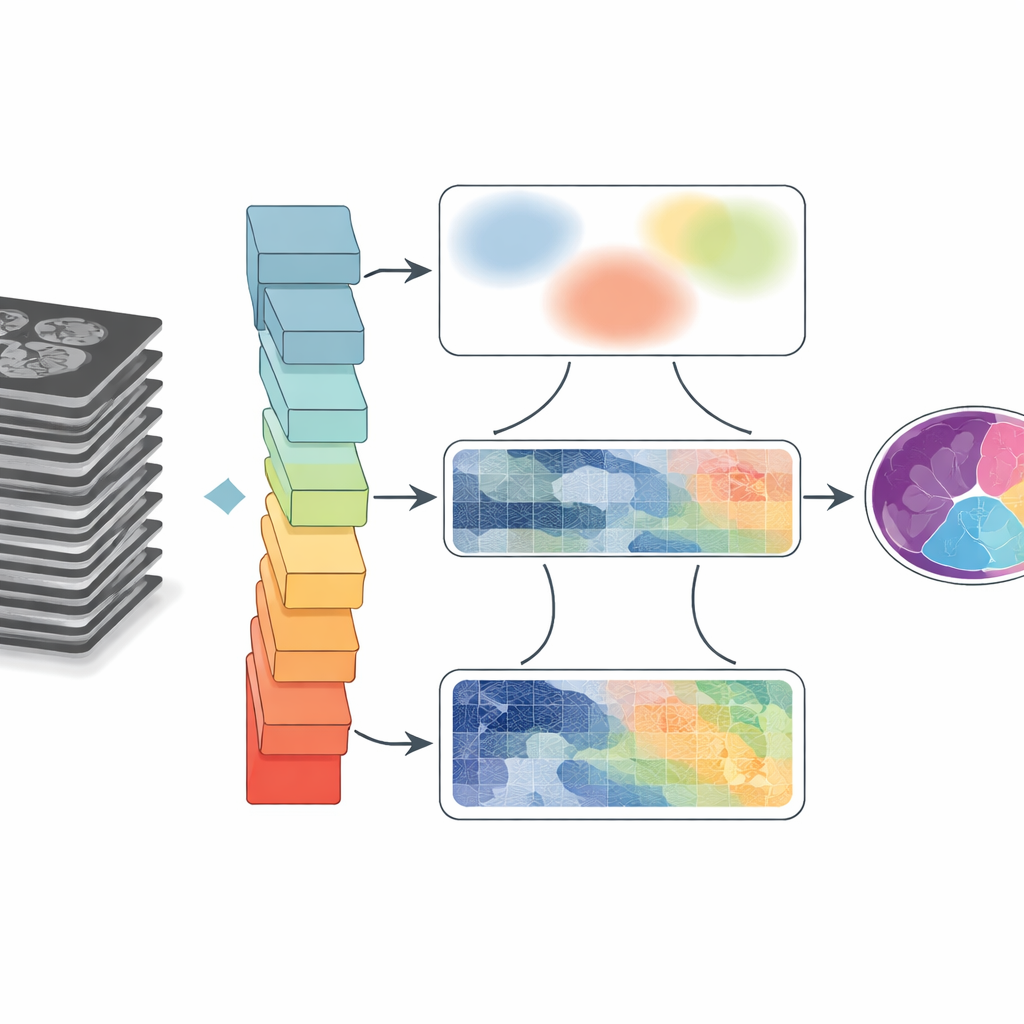
لماذا رسم الحدود في الفحوصات أمر صعب للغاية
الصور الطبية فوضوية. الأعضاء تتلامس أو تتداخل، الحواف قد تبدو غائمة، والحركة أو قيود الأجهزة تضيف ضبابية ومشوشات. البرامج التقليدية تجمع البكسلات بناءً على قواعد بسيطة، والتي غالبًا ما تفشل عندما تكون البنى صغيرة أو تباينها ضعيف. حسن التعلم العميق الأداء بشكل كبير بتمكين الشبكات العصبية من تعلم الأنماط مباشرة من مجموعات بيانات كبيرة. ومع ذلك، فإن التصاميم الشائعة إما تركز على جوار صغير من البكسلات فتغفل الاتصالات بعيدة المدى، أو تُوسِّع الرؤية لرؤية الصورة العامة فتفقد التفاصيل الدقيقة على الحواف. تصبح هذه المقايضة حاسمة عندما يحتاج الأطباء لشكل وأحجام دقيقة، مثل قياس حجرات القلب أو تتبع حركة اللسان بعد الجراحة.
دمج الصورة الكبيرة مع التفاصيل الدقيقة
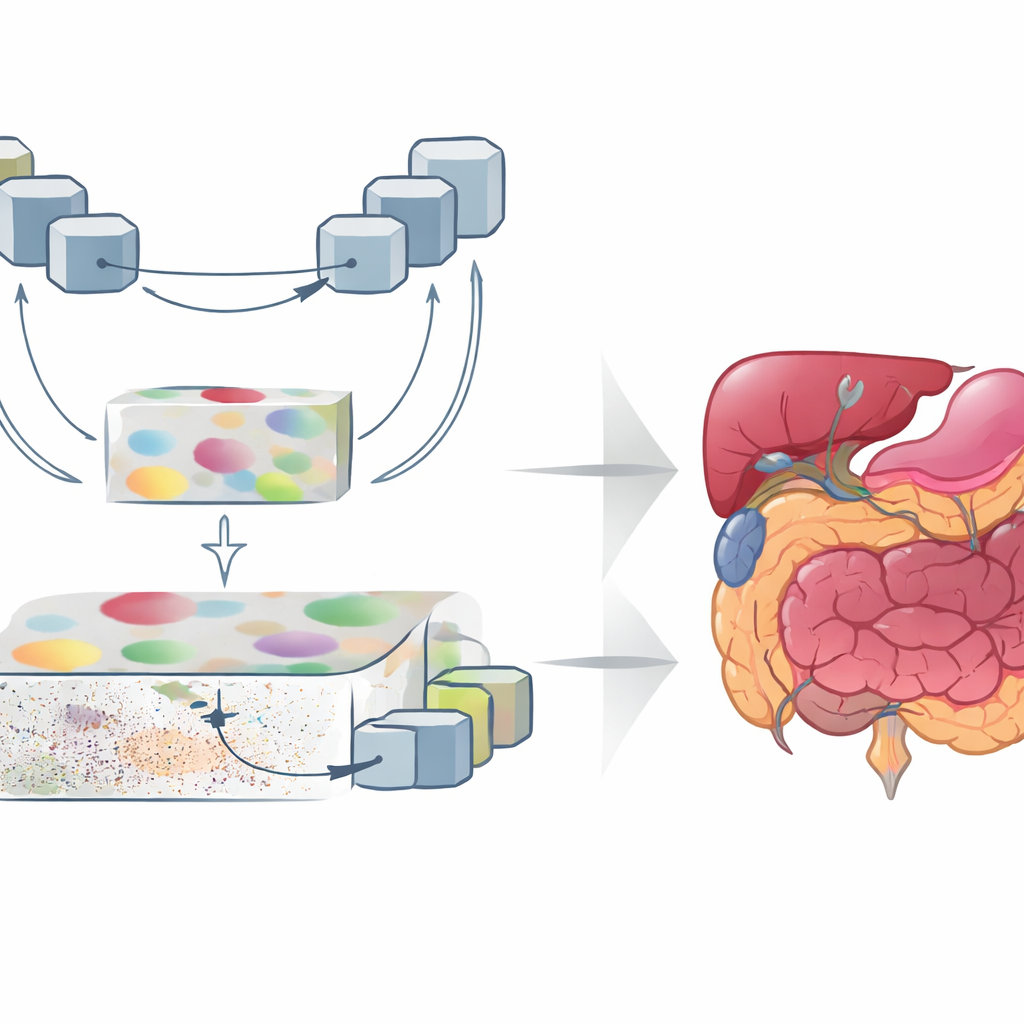
صُممت GoLoCo-Net لالتقاط كل من السياق الواسع للصورة والتفاصيل الدقيقة عند الحواف. في جوهرها يوجد مُشفّر حديث من نوع «محول الرؤية» ينظر إلى الفحص بأكمله دفعة واحدة، ويتعلم كيف ترتبط المناطق البعيدة ببعضها. وفوق ذلك يبني المؤلفون فرعين فكّين منفصلين. يركز أحد الفروع على الفهم عالي المستوى: ما البنى الموجودة وكيفية ترتيبها. أما الآخر فيحافظ على المعلومات منخفضة المستوى مثل النسيج والحواف الحادة. بدلًا من مجرد خياطة هذين المنظورين معًا، تستخدم GoLoCo-Net وحدات انتباه مصممة بعناية بحيث توجه المعلومات العالمية التفاصيل المحلية، وفي المقابل تسمح للإشارات المحلية بشحذ الرؤية العالمية.
كيف تشّكل الوحدات الجديدة الصورة
الوحدة الرئيسية الأولى، المسماة تعزيز الميزات بالانتباه السياقي، تثري التمثيل عالي المستوى. تمرر الميزات المجردة عبر كتلة على شكل حرف U تقلل وتكبر تمثيل الصورة بشكل متكرر، مما يتيح للشبكة النظر إلى البنى بأحجام متعددة. تبرز آليات الانتباه بعد ذلك المناطق الأكثر أهمية وتقلل من ميل المحولات لتوسيع التركيز بشكل مفرط، والذي قد يطمس حدود الأعضاء. تبدأ الوحدة الثانية، ميزة الدليل العالمي للمحلي، من الجهة المعاكسة: تأخذ معلومات الحواف والنسيج التفصيلية من الطبقات السطحية وتستخدم إشارة عالمية من الطبقات الأعمق لتصفية الضوضاء والخلفية. تبرز كتل انتباه إضافية القنوات والمناطق المكانية المهمة، بحيث تُحفظ الأعضاء الصغيرة والهياكل الرقيقة دون أن تُطغى عليها الفوضى.
إثبات الفعالية عبر أعضاء وأجهزة تصوير مختلفة
لاختبار GoLoCo-Net، قيّم الباحثون أدائها على ثلاث مجموعات بيانات مختلفة تمامًا. تلتقط الأولى القناة الصوتية أثناء حركة الكلام في رنين مغناطيسي سريع، حيث يتحرك اللسان والحنك الرخو والأنسجة المحيطة بسرعة ويكونون عرضة للضباب والمشوشات التصويرية. تحتوي الثانية على صور رنين مغناطيسي قلبية تُستخدم لقياس حجرات وعضلة القلب. الثالثة هي مجموعة بيانات تصوير مقطعي لأعضاء البطن المتعددة، بما في ذلك الكبد والكليتان والبنكرياس. في الثلاثة، تفوقت GoLoCo-Net على عدة نماذج متقدمة قائمة على الشبكات الالتفافية والمحولات، محققة درجات تداخل أعلى مع الحدود المرسومة من الخبراء وحفاظًا أفضل على أشكال التشريح. بقيت قوية حتى عند إضافة ضوضاء إضافية، مما يشير إلى قدرتها على التعامل مع بيانات العالم الحقيقي غير المثالية.
ماذا يعني هذا للمرضى والأطباء
عمليًا، تقدم GoLoCo-Net طريقة أكثر موثوقية لتحويل الصور الخام إلى خرائط تشريحية دقيقة. بالنسبة لأطباء الأشعة والجراحين، يمكن أن يعني ذلك قياسات أنظف وأكثر اتساقًا للأعضاء والأورام. بالنسبة لعلماء ومعالجي النطق، يمكن أن يوفر مشاهد أوضح إطارًا بإطار لكيفية تحرك اللسان والحنك الرخو، دون الحاجة إلى تتبع يدوي مرهق. وبما أن الوحدات الأساسية صممت لتُدمج في الأنظمة القائمة، فقد يُعتمد النهج على نطاق واسع مع استمرار تطور الذكاء الاصطناعي في التصوير. الخلاصة بسيطة: من خلال تعليم الحواسيب موازنة الصورة الكبيرة مع أدق التفاصيل، يقرب هذا العملنا من تفسير أسرع وأكثر دقة وصلابة للصور الطبية.
الاستشهاد: He, Y., Miquel, M.E. & Zhang, Q. GoLoCo-Net: global-local guided contextual attention network for medical images segmentation. Sci Rep 16, 12300 (2026). https://doi.org/10.1038/s41598-026-42415-0
الكلمات المفتاحية: تجزئة الصور الطبية, الرنين المغناطيسي, التصوير المقطعي المحوسب, التعلم العميق, محول الرؤية