Clear Sky Science · nl
GoLoCo-Net: global-local guided contextual attention network voor segmentatie van medische beelden
Binnen in het lichaam duidelijker zien
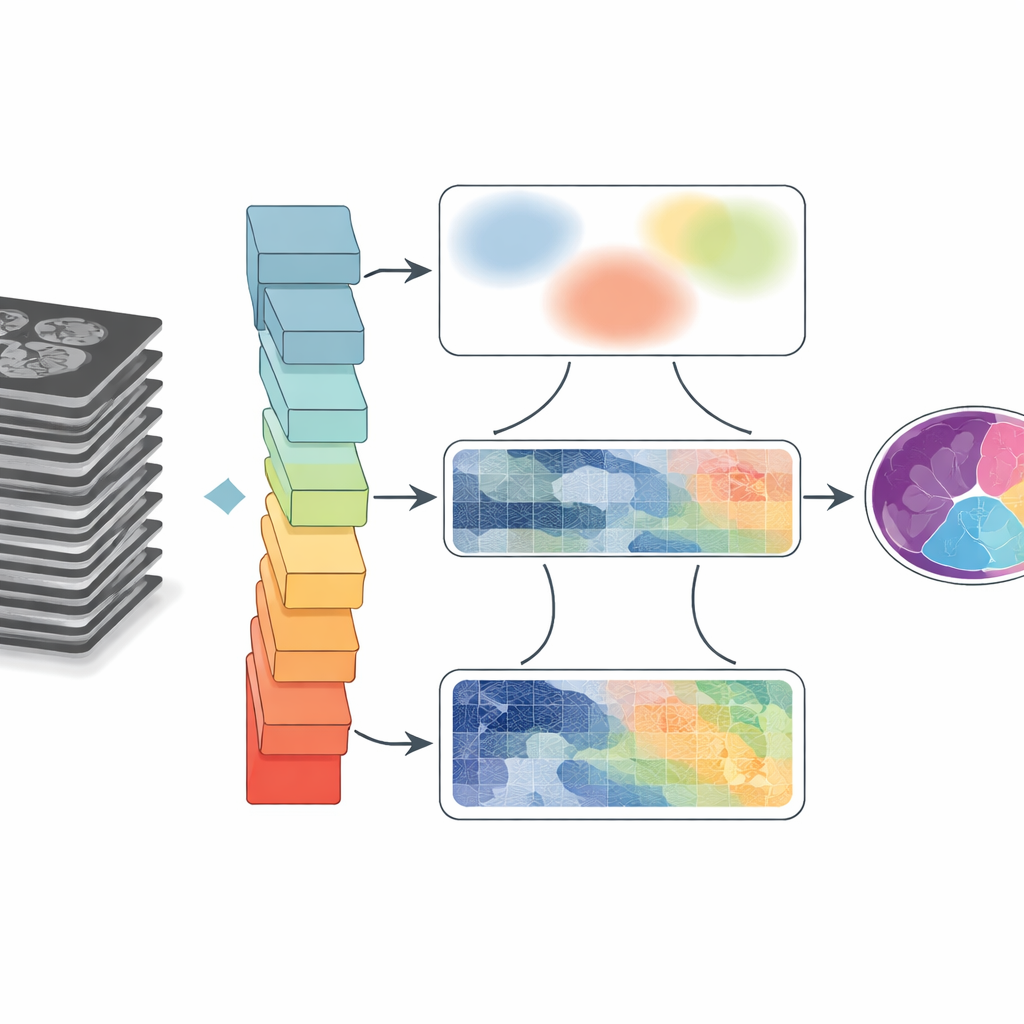
Artsen vertrouwen steeds vaker op MRI- en CT-scans om te begrijpen hoe onze organen bewegen en veranderen in de tijd, van het kloppende hart tot de tong in beweging tijdens spraak. Maar om deze grijsschaalbeelden om te zetten in duidelijke, kleurgecodeerde kaarten van de anatomie, moeten computers elke structuur nauwkeurig omlijnen — een taak die segmentatie genoemd wordt. Dit artikel introduceert GoLoCo-Net, een nieuwe kunstmatige-intelligentiemethode die die omlijningen scherper en betrouwbaarder maakt over verschillende typen medische scans, wat mogelijk de diagnostiek, behandelplanning en het onderzoek naar lichaamsfuncties verbetert.
Waarom grenzen trekken in scans zo moeilijk is
Medische beelden zijn rommelig. Organen raken elkaar aan of overlappen, randen kunnen vaag lijken, en beweging of hardwarebeperkingen veroorzaken onscherpte en artefacten. Traditionele computerprogramma’s groeperen pixels op basis van simpele regels, wat vaak faalt wanneer structuren klein zijn of een zwak contrast hebben. Deep learning heeft de prestaties sterk verbeterd doordat neurale netwerken patronen rechtstreeks uit grote datasets kunnen leren. Veel gangbare ontwerpen richten zich echter ofwel op kleine pixelbuurten, waardoor langeafstandrelaties missen, of ze zoomen uit om het grote geheel te zien maar verliezen fijne details bij randen. Deze afweging wordt cruciaal wanneer artsen nauwkeurige vormen en afmetingen nodig hebben, bijvoorbeeld voor het meten van hartkamers of het volgen van tongbewegingen na een operatie.
Het grote geheel en fijne details combineren
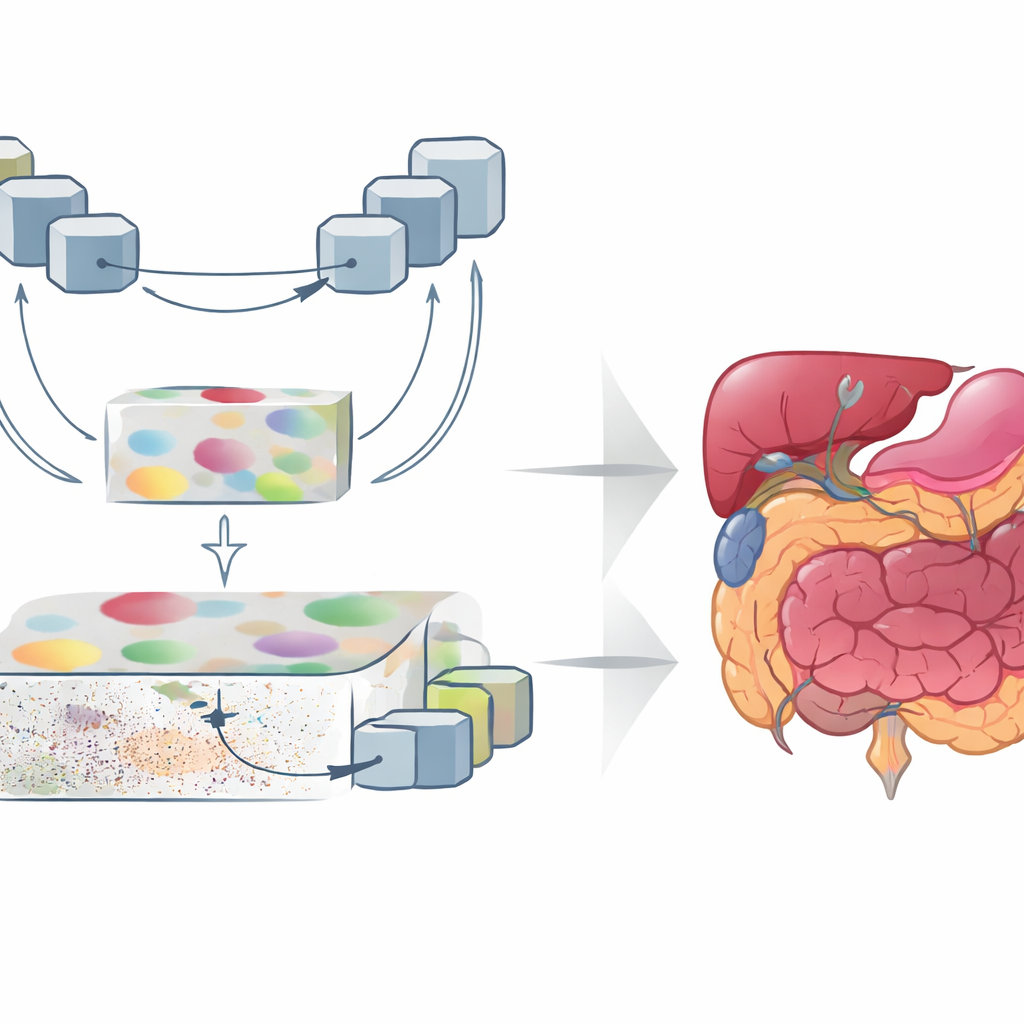
GoLoCo-Net is ontworpen om zowel de brede context van een beeld als de fijne details bij de randen vast te leggen. Centraal staat een moderne "vision transformer"-encoder die de hele scan in één keer bekijkt en leert hoe verre regio’s zich tot elkaar verhouden. Daarboven bouwen de auteurs twee afzonderlijke decoder-branches. De ene tak richt zich op begrip op hoog niveau: welke structuren aanwezig zijn en hoe ze gerangschikt zijn. De andere bewaart laag-niveau-informatie zoals textuur en scherpe grenzen. In plaats van deze gezichtspunten simpelweg aan elkaar te plakken, gebruikt GoLoCo-Net zorgvuldig samengestelde attention-modules zodat globale informatie lokale details kan sturen en lokale aanwijzingen op hun beurt het globale beeld kunnen verscherpen.
Hoe de nieuwe modules het beeld vormen
De eerste sleutelmodule, Contextual Attention Feature Enhancement genoemd, verrijkt de hoog-niveau representatie. Hij leidt de abstracte kenmerken door een U-vormig blok dat de beeldrepresentatie herhaaldelijk verkleint en vergroot, waardoor het netwerk structuren op meerdere schalen kan bekijken. Attention-mechanismen benadrukken vervolgens de regio’s die er het meest toe doen en dempen de neiging van transformers om hun focus te breed te verspreiden, wat orgaangrenzen kan vervagen. De tweede module, Global-Guide-Local Feature, begint aan de tegenovergestelde kant: zij neemt gedetailleerde rand- en texture informatie uit ondiepe lagen en gebruikt een globaal signaal uit diepere lagen om ruis en achtergrond te filteren. Extra attention-blokken benadrukken belangrijke kanalen en ruimtelijke regio’s, zodat kleine organen en dunne structuren bewaard blijven zonder te worden overschaduwd door rommel.
Bewijzen dat het werkt voor verschillende organen en scanners
Om GoLoCo-Net te testen, evalueerden de onderzoekers het op drie zeer verschillende datasets. De eerste bevat de vocale tractus in beweging tijdens spraak-MRI, waarbij de tong, het zachte gehemelte en omliggende weefsels snel bewegen en gevoelig zijn voor onscherpte en beeldartefacten. De tweede bevat cardiale MRI-scans die gebruikt worden om de hartkamers en de hartspier te meten. De derde is een CT-dataset van meerdere abdominale organen, inclusief lever, nieren en alvleesklier. Op alle drie scoorde GoLoCo-Net beter dan meerdere toonaangevende convolutionele en transformer-gebaseerde modellen, met hogere overlap-scores met door experts getekende contouren en betere behoud van anatomische vormen. Het bleef robuust, zelfs wanneer extra ruis werd toegevoegd, wat suggereert dat het met imperfecte, reële data om kan gaan.
Wat dit betekent voor patiënten en clinici
In praktische termen biedt GoLoCo-Net een betrouwbaardere manier om ruwe scans om te zetten in precieze anatomische kaarten. Voor radiologen en chirurgen kan dat schonere, consistentere metingen van organen en tumoren betekenen. Voor spraakwetenschappers en clinici kan het duidelijkere, frame-voor-frame beelden van hoe de tong en het zachte gehemelte bewegen bieden, zonder tijdrovend handmatig traceren. Omdat de sleutelmodules zijn ontworpen om in bestaande systemen te worden ingeplugd, kan de aanpak breed worden overgenomen naarmate imaging-AI zich verder ontwikkelt. De belangrijkste conclusie is eenvoudig: door computers te leren het grote geheel in balans te brengen met de fijnste details, brengt dit werk ons dichter bij snellere, nauwkeurigere en robuustere interpretatie van medische beelden.
Bronvermelding: He, Y., Miquel, M.E. & Zhang, Q. GoLoCo-Net: global-local guided contextual attention network for medical images segmentation. Sci Rep 16, 12300 (2026). https://doi.org/10.1038/s41598-026-42415-0
Trefwoorden: segmentatie van medische beelden, MRI, CT, deep learning, vision transformer