Clear Sky Science · ru
GoLoCo-Net: глобально-локальная сеть с управляемым контекстным вниманием для сегментации медицинских изображений
Более ясное «видение» внутренностей тела
Врачи всё чаще опираются на МРТ и КТ, чтобы понять, как наши органы движутся и изменяются со временем — от бьющегося сердца до языка в движении при речи. Но чтобы преобразовать эти оттенки серого в чёткие, цветовые карты анатомии, компьютерам нужно точно очерчивать каждую структуру — задача, известная как сегментация. В этой статье представлена GoLoCo-Net, новый метод искусственного интеллекта, который делает эти контуры более чёткими и надёжными на разных типах медицинских снимков, что может улучшить диагностику, планирование лечения и исследования функционирования организма.
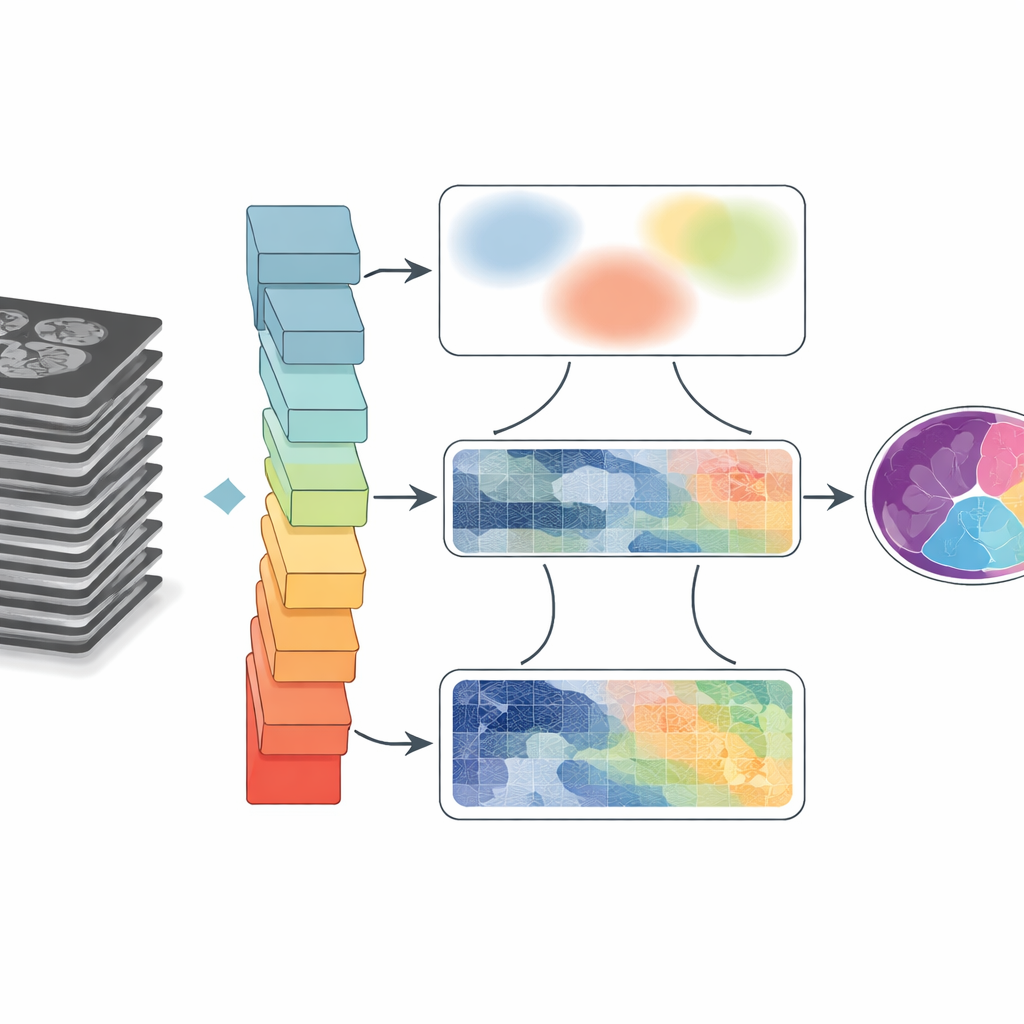
Почему так сложно проводить границы на снимках
Медицинские изображения часто бывают «грязными». Органы соприкасаются или перекрываются, границы могут выглядеть расплывчатыми, а движение или ограничения оборудования приводят к размытиям и артефактам. Традиционные алгоритмы группируют пиксели по простым правилам, которые часто терпят неудачу, когда структуры малы или имеют слабый контраст. Глубокое обучение существенно повысило качество, позволяя нейронным сетям изучать паттерны прямо из больших наборов данных. Однако распространённые архитектуры либо фокусируются на локальных окрестностях пикселей, упуская дальние связи, либо «отдаляются», чтобы охватить общую картину, теряя при этом тонкие детали на границах. Этот компромисс становится критичным, когда врачам нужны точные формы и размеры — например, при измерении полостей сердца или отслеживании движения языка после операции.
Сочетание общей картины и тонких деталей
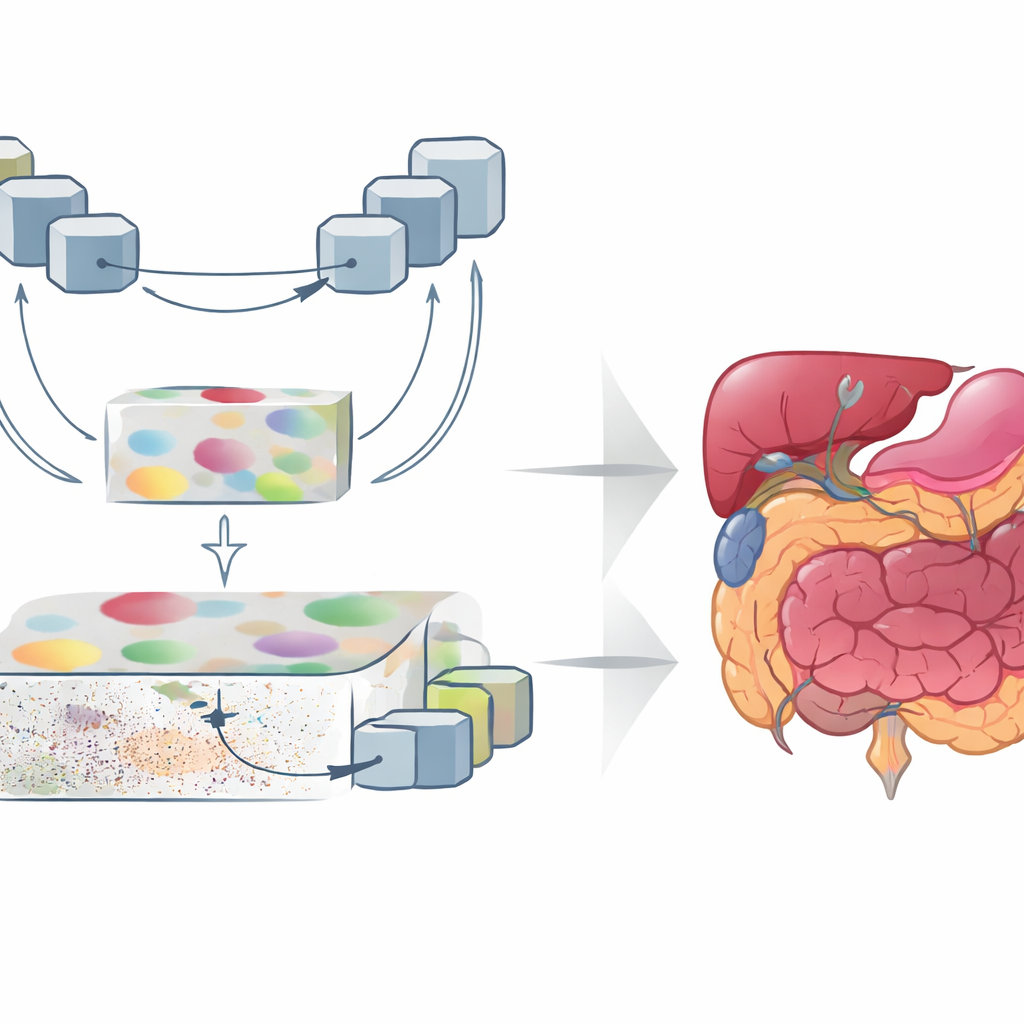
GoLoCo-Net разработана так, чтобы захватывать и широкий контекст изображения, и мельчайшие детали на его краях. В её основе — современный энкодер на базе «vision transformer», который рассматривает весь снимок сразу и учится, как удалённые области связаны друг с другом. Поверх этого авторы строят две отдельные ветви декодера. Одна ветвь фокусируется на высокоуровневом понимании: какие структуры присутствуют и как они расположены. Другая сохраняет низкоуровневую информацию — текстуру и чёткие границы. Вместо простого сшивания этих представлений GoLoCo-Net использует тщательно продуманные модули внимания, чтобы глобальная информация направляла локальные детали, а локальные подсказки, в свою очередь, уточняли глобальную картину.
Как новые модули формируют представление
Первый ключевой модуль, называемый Усиление признаков с контекстным вниманием (Contextual Attention Feature Enhancement), обогащает высокоуровневое представление. Он пропускает абстрактные признаки через U-образный блок, который многократно сжимает и расширяет представление изображения, позволяя сети рассматривать структуры в разных масштабах. Механизмы внимания затем выделяют наиболее важные области и ослабляют тенденцию трансформеров распределять фокус слишком широко, что может размывать границы органов. Второй модуль, Global-Guide-Local Feature, действует с противоположной стороны: он берёт детальную информацию о краях и текстуре из мелких слоёв и использует глобальный сигнал из глубоких слоёв, чтобы отфильтровывать шум и фон. Дополнительные блоки внимания подчёркивают важные каналы и пространственные области, так что маленькие органы и тонкие структуры сохраняются и не теряются в помехах.
Доказательства эффективности на разных органах и сканерах
Чтобы проверить GoLoCo-Net, исследователи протестировали её на трёх очень разных наборах данных. Один фиксирует в движении голосовой тракт при МРТ речи, где язык, мягкое нёбо и окружающие ткани быстро двигаются и подвержены размытию и артефактам. Второй содержит кардиологические МРТ для измерения полостей и миокарда сердца. Третий — КТ-набор данных с несколькими органами брюшной полости, включая печень, почки и поджелудочную железу. Во всех трёх случаях GoLoCo-Net превзошла несколько ведущих свёрточных и трансформерных моделей, показывая более высокое совпадение с экспертно очерченными контурами и лучшую сохранность анатомических форм. Модель оставалась робастной даже при добавлении дополнительного шума, что указывает на способность работать с несовершенными, реальными данными.
Что это значит для пациентов и клиницистов
Практически GoLoCo-Net предлагает более надёжный способ превратить сырые снимки в точные карты анатомии. Для радиологов и хирургов это может означать чище и последовательнее измерения органов и опухолей. Для исследователей речи и клиницистов — более чёткие покадровые представления движения языка и мягкого нёба без трудоёмкого ручного обвода. Поскольку ключевые модули спроектированы так, чтобы их можно было подключать к существующим системам, подход может широко распространиться по мере развития ИИ в медицине. Главный вывод прост: научив компьютеры уравновешивать общую картину и мельчайшие детали, эта работа приближает нас к более быстрому, точному и надёжному анализу медицинских изображений.
Цитирование: He, Y., Miquel, M.E. & Zhang, Q. GoLoCo-Net: global-local guided contextual attention network for medical images segmentation. Sci Rep 16, 12300 (2026). https://doi.org/10.1038/s41598-026-42415-0
Ключевые слова: сегментация медицинских изображений, МРТ, КТ, глубокое обучение, vision transformer