Clear Sky Science · en
GoLoCo-Net: global-local guided contextual attention network for medical images segmentation
Seeing Inside the Body More Clearly
Doctors increasingly rely on MRI and CT scans to understand how our organs move and change over time, from the beating heart to the tongue in motion during speech. But to turn these grey-scale images into clear, color-coded maps of anatomy, computers must precisely outline each structure, a task known as segmentation. This paper introduces GoLoCo-Net, a new artificial intelligence method that makes those outlines sharper and more reliable across different types of medical scans, potentially improving diagnosis, treatment planning, and research on how the body works.
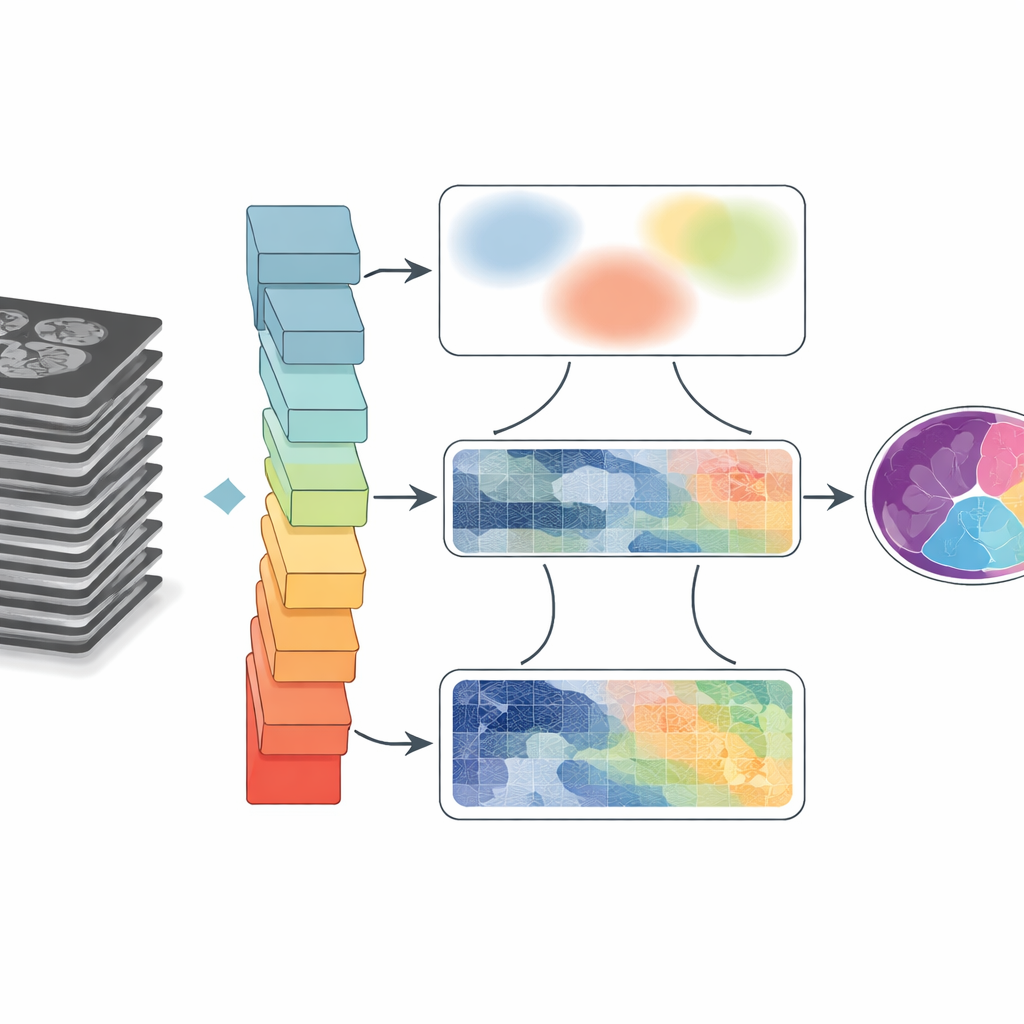
Why Drawing Borders in Scans Is So Hard
Medical images are messy. Organs touch or overlap, edges can look fuzzy, and motion or hardware limitations introduce blur and artifacts. Traditional computer programs group pixels based on simple rules, which often fail when structures are small or have weak contrast. Deep learning has greatly improved performance by letting neural networks learn patterns directly from large datasets. However, common designs either focus on small neighborhoods of pixels, missing long-distance connections, or zoom out to see the big picture but lose fine detail at boundaries. This trade-off becomes critical when doctors need accurate shapes and sizes, such as measuring heart chambers or tracking tongue motion after surgery.
Blending Big Picture and Fine Detail
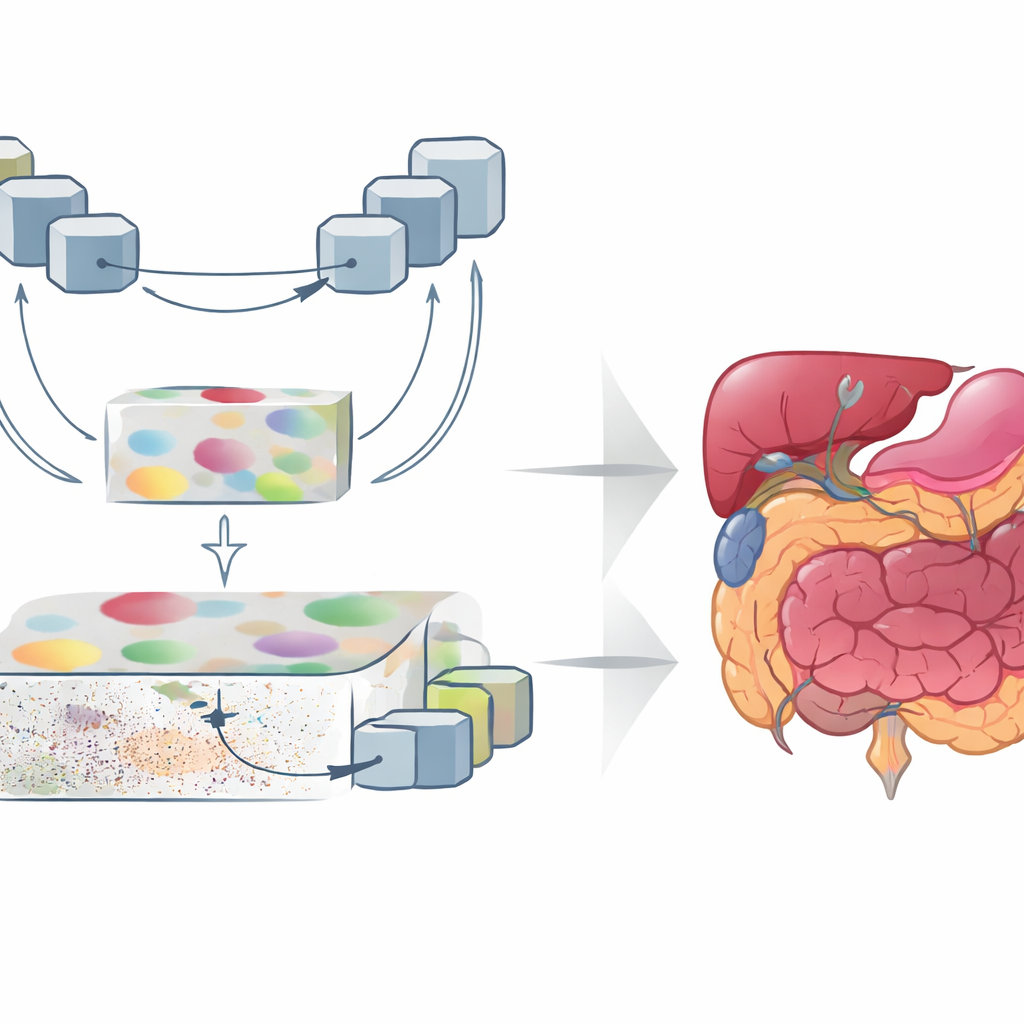
GoLoCo-Net is designed to capture both the wide context of an image and the tiny details at its edges. At its core lies a modern "vision transformer" encoder that views the entire scan at once, learning how distant regions relate to each other. On top of this, the authors build two separate decoding branches. One branch focuses on high-level understanding: what structures are present and how they are arranged. The other preserves low-level information such as texture and sharp boundaries. Instead of simply stitching these views together, GoLoCo-Net uses carefully crafted attention modules so that global information can guide local detail and, in turn, local cues can sharpen the global view.
How the New Modules Shape the View
The first key module, called Contextual Attention Feature Enhancement, enriches the high-level representation. It routes the abstract features through a U-shaped block that repeatedly shrinks and enlarges the image representation, allowing the network to look at structures at multiple sizes. Attention mechanisms then highlight regions that matter most and tone down the tendency of transformers to spread their focus too broadly, which can blur organ boundaries. The second module, Global-Guide-Local Feature, starts from the opposite side: it takes detailed edge and texture information from shallow layers and uses a global signal from deeper layers to filter out noise and background. Additional attention blocks emphasize important channels and spatial regions, so that small organs and thin structures are preserved without being overwhelmed by clutter.
Proving It Works Across Organs and Scanners
To test GoLoCo-Net, the researchers evaluated it on three very different datasets. One captures the vocal tract in motion during speech MRI, where the tongue, soft palate, and surrounding tissues move quickly and are prone to blur and imaging artifacts. The second contains cardiac MRI scans used to measure the heart’s chambers and muscle. The third is a CT dataset of multiple abdominal organs, including the liver, kidneys, and pancreas. On all three, GoLoCo-Net outperformed several leading convolutional and transformer-based models, achieving higher overlap scores with expert-drawn outlines and better preservation of anatomical shapes. It remained robust even when extra noise was added, suggesting it can handle imperfect, real-world data.
What This Means for Patients and Clinicians
In practical terms, GoLoCo-Net offers a more reliable way to turn raw scans into precise maps of anatomy. For radiologists and surgeons, that can mean cleaner, more consistent measurements of organs and tumors. For speech scientists and clinicians, it can provide clearer, frame-by-frame views of how the tongue and soft palate move, without laborious manual tracing. Because the key modules are designed to plug into existing systems, the approach may be adopted widely as imaging AI continues to evolve. The main takeaway is simple: by teaching computers to balance the big picture with the finest details, this work moves us closer to faster, more accurate, and more robust interpretation of medical images.
Citation: He, Y., Miquel, M.E. & Zhang, Q. GoLoCo-Net: global-local guided contextual attention network for medical images segmentation. Sci Rep 16, 12300 (2026). https://doi.org/10.1038/s41598-026-42415-0
Keywords: medical image segmentation, MRI, CT, deep learning, vision transformer