Clear Sky Science · it
GoLoCo-Net: rete di attenzione contestuale guidata globale-locale per la segmentazione delle immagini mediche
Vedere l’interno del corpo con maggiore chiarezza
I medici si affidano sempre più a esami MRI e TC per comprendere come i nostri organi si muovono e cambiano nel tempo, dal battito cardiaco alla lingua in movimento durante il parlato. Ma per trasformare queste immagini in scala di grigi in mappe anatomiche chiare e codificate a colori, i computer devono tracciare con precisione ogni struttura, un compito noto come segmentazione. Questo articolo presenta GoLoCo-Net, un nuovo metodo di intelligenza artificiale che rende quei contorni più nitidi e affidabili su diversi tipi di esami medici, migliorando potenzialmente la diagnosi, la pianificazione del trattamento e la ricerca sul funzionamento del corpo.
Perché tracciare i confini nelle immagini è così difficile
Le immagini mediche sono complesse. Gli organi si toccano o si sovrappongono, i bordi possono apparire sfocati e il movimento o i limiti dell’apparecchiatura introducono sfocature e artefatti. I programmi tradizionali raggruppano i pixel sulla base di regole semplici, che spesso falliscono quando le strutture sono piccole o con basso contrasto. L’apprendimento profondo ha notevolmente migliorato le prestazioni permettendo alle reti neurali di apprendere pattern direttamente da grandi dataset. Tuttavia, i progetti comuni o si concentrano su piccoli vicinati di pixel, perdendo connessioni a lunga distanza, oppure fanno un’ampia panoramica perdendo dettagli fini ai bordi. Questo compromesso diventa critico quando i medici hanno bisogno di forme e dimensioni accurate, come nel misurare le camere cardiache o nel tracciare il movimento della lingua dopo un intervento chirurgico.
Fondere il quadro generale e i dettagli fini
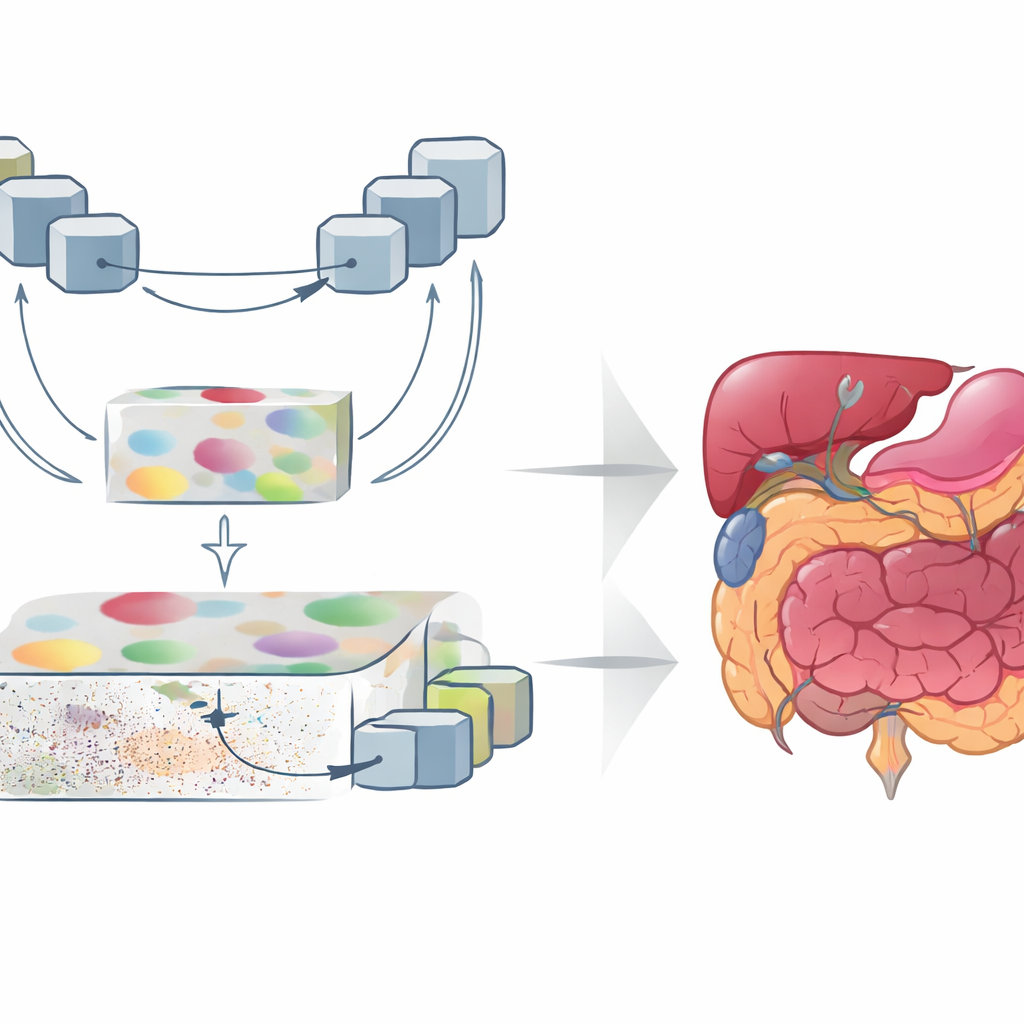
GoLoCo-Net è progettato per catturare sia il contesto ampio di un’immagine sia i minuscoli dettagli ai suoi margini. Al suo nucleo c’è un moderno encoder basato su "vision transformer" che osserva l’intera scansione in una volta, imparando come regioni distanti sono correlate tra loro. Sopra a questo, gli autori costruiscono due rami di decodifica separati. Un ramo si concentra sulla comprensione di alto livello: quali strutture sono presenti e come sono disposte. L’altro preserva informazioni di basso livello come la texture e i contorni netti. Invece di limitarsi a cucire queste viste insieme, GoLoCo-Net utilizza moduli di attenzione accuratamente progettati in modo che l’informazione globale possa guidare il dettaglio locale e, a sua volta, i segnali locali possano affinare la visione globale.
Come i nuovi moduli modellano la visione
Il primo modulo chiave, chiamato Contextual Attention Feature Enhancement, arricchisce la rappresentazione di alto livello. Instrada le caratteristiche astratte attraverso un blocco a forma di U che riduce e ingrandisce ripetutamente la rappresentazione dell’immagine, permettendo alla rete di osservare le strutture a più scale. I meccanismi di attenzione quindi evidenziano le regioni più rilevanti e attenuano la tendenza dei transformer a diffondere lo sguardo troppo ampiamente, cosa che può sfumare i confini degli organi. Il secondo modulo, Global-Guide-Local Feature, parte dall’opposto: prende informazioni dettagliate su bordi e texture da strati superficiali e utilizza un segnale globale proveniente da strati più profondi per filtrare rumore e sfondo. Blocchi di attenzione aggiuntivi enfatizzano i canali e le regioni spaziali importanti, in modo che organi piccoli e strutture sottili siano preservati senza essere sopraffatti dal disturbo circostante.
Dimostrare che funziona su organi e scanner diversi
Per testare GoLoCo-Net, i ricercatori lo hanno valutato su tre dataset molto diversi. Uno cattura il tratto vocale in movimento durante MRI del parlato, dove lingua, velo palatino e tessuti circostanti si muovono rapidamente e sono soggetti a sfocature e artefatti. Il secondo contiene scansioni MRI cardiache utilizzate per misurare le camere e il muscolo del cuore. Il terzo è un dataset TC di più organi addominali, compresi fegato, reni e pancreas. Su tutti e tre, GoLoCo-Net ha superato diversi modelli di punta basati su convoluzioni e transformer, ottenendo punteggi di sovrapposizione più alti con i contorni tracciati dagli esperti e una migliore conservazione delle forme anatomiche. È rimasto robusto anche quando è stato aggiunto rumore extra, suggerendo che può gestire dati imperfetti nel mondo reale.
Cosa significa per pazienti e clinici
In termini pratici, GoLoCo-Net offre un modo più affidabile per trasformare le scansioni grezze in mappe anatomiche precise. Per radiologi e chirurghi, ciò può significare misurazioni di organi e tumori più pulite e coerenti. Per scienziati del parlato e clinici, può fornire viste più chiare, fotogramma per fotogramma, di come si muovono lingua e velo palatino, senza il laborioso tracciamento manuale. Poiché i moduli chiave sono progettati per integrarsi nei sistemi esistenti, l’approccio potrebbe essere adottato diffusamente man mano che l’IA per l’imaging continua a evolversi. La conclusione principale è semplice: insegnando ai computer a bilanciare il quadro generale con i dettagli più fini, questo lavoro ci avvicina a un’interpretazione delle immagini mediche più rapida, precisa e robusta.
Citazione: He, Y., Miquel, M.E. & Zhang, Q. GoLoCo-Net: global-local guided contextual attention network for medical images segmentation. Sci Rep 16, 12300 (2026). https://doi.org/10.1038/s41598-026-42415-0
Parole chiave: segmentazione di immagini mediche, risonanza magnetica (MRI), TC, apprendimento profondo, vision transformer