Clear Sky Science · sv
En enhetlig ram för att korrigera batch‑effekter och integrera multi‑omics‑data
Varför det spelar roll att blanda många datatyper
Modern biologi kan mäta många slags molekyler i våra celler, från vilka gener som är aktiva till hur DNA är kemiskt märkta och hur tätt det packas. Att studera dessa lager tillsammans, känt som ”multi‑omics”, kan avslöja dolda mönster i sjukdomar som cancer eller i hjärnans kopplingar. Men eftersom dessa mätningar är kostsamma kombinerar forskare ofta data från många sjukhus och laboratorier, vilket inför oönskade tekniska skillnader som kan sudda ut eller till och med dölja verkliga biologiska signaler. Denna artikel introducerar MoDAmix, en ny beräkningsmetod som rensar och förenar sådana komplexa dataset så att forskare kan lita på vad de ser.

Problemet med röriga databatcher
När laboratorier runt om i världen mäter liknande prover använder de sällan identiska maskiner, protokoll eller tidpunkter. Dessa skillnader skapar ”batch‑effekter” – systematiska egenheter orsakade av tekniken snarare än biologin. I single‑omics‑studier försöker flera verktyg redan ta bort dessa artefakter, men de behandlar varje mätningstyp för sig. För multi‑omics‑data räcker det inte. Om varje lager rengörs separat kan de olika molekylära vyerna av samma patient eller cell glida isär och bryta de kopplingar som är mest informativa. Författarna menar att vad som behövs istället är ett samordnat angreppssätt som rengör alla lager tillsammans samtidigt som deras gemensamma struktur bevaras.
Ett nytt sätt att alignera många datalager
MoDAmix tar sig an denna utmaning genom att låna idéer från ”domänanpassning”, en maskininlärningsstrategi som används för att få modeller att fungera i olika miljöer, till exempel bilder från olika kameror. Metoden går till i fyra steg. Först lär den sig hur varje omics‑typ ska representeras och hur biologiska subtyper särskiljs med en märkt ”source”-datamängd. Därefter minskar den batch‑effekter inom varje omics‑lager genom att träna systemet så att prover från olika studier ser lika ut om de representerar samma biologi. Tredje steget för samman alla omics‑typer i ett gemensamt lågdimentionellt rum och tvingar modellen igen att ignorera tekniska skillnader mellan dataset. Slutligen skärps subtypgränserna genom att modellen får gissa etiketter för den omärkta ”target”-datan och varsamt dra prover av samma subtyp mot gemensamma centra i detta delade rum.
Att sätta metoden på prov
Forskarna testade MoDAmix på tre krävande uppgifter. I en single‑cell‑studie av vuxen musehjärna kombinerade de genaktivitet och kromatinåtkomlighet för att identifiera celltyper. I två cancerstudier integrerade de genuttryck med DNA‑metylering för att klassificera subtyper av akut myeloisk leukemi och hjärntumörer över oberoende patientkohorter. De jämförde MoDAmix med populära verktyg för batch‑korrigering och med nyare metoder för multi‑omics‑integration. Med mått som klassificeringsnoggrannhet och klusterkvalitet gav MoDAmix konsekvent renare grupperingar av celler och patienter. Visuella kartor över data visade att prover från olika batcher blandades väl, medan distinkta celltyper eller tumörsubtyper förblev klart separerade – något konkurrerande metoder ofta misslyckades med att uppnå.
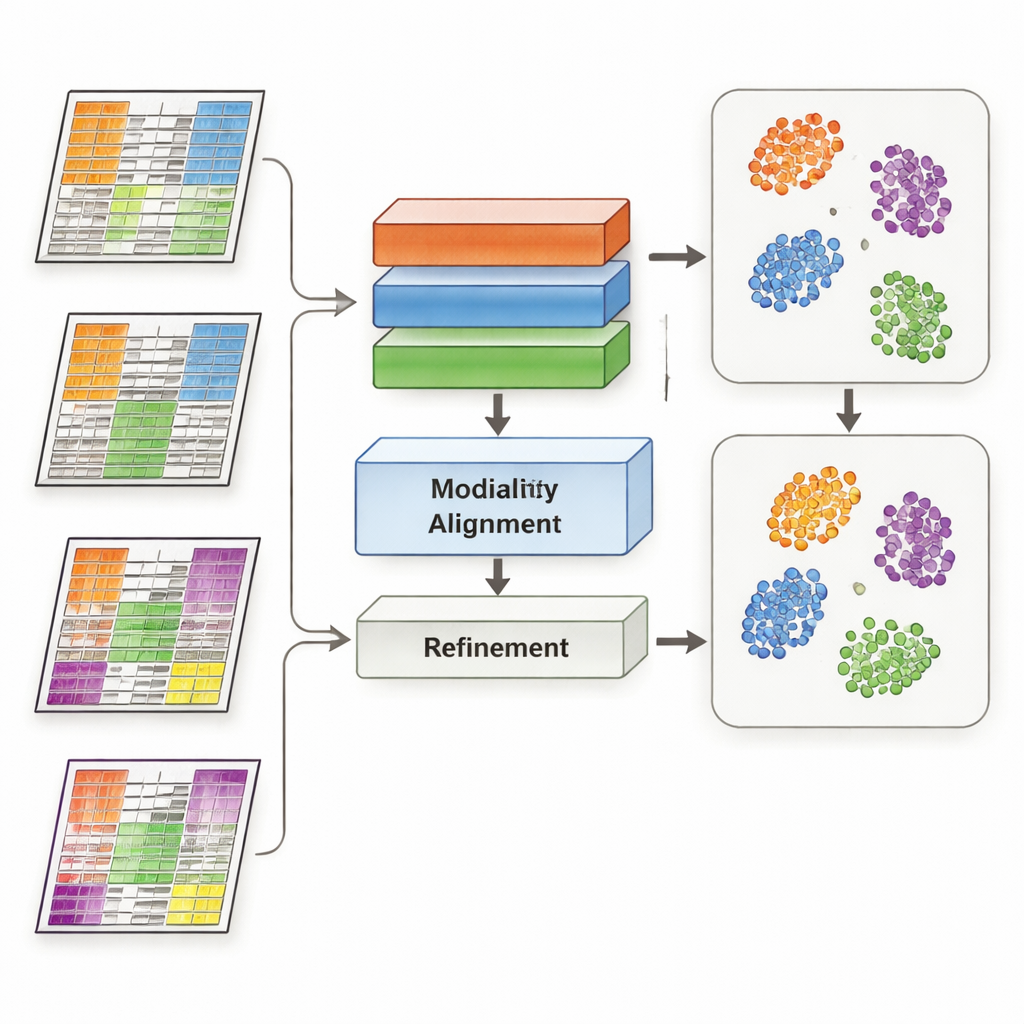
Varför adversariell inlärning hjälper
En nyckelingrediens i MoDAmix är adversariell inlärning, där en del av modellen försöker skilja mellan batcher medan en annan del lär sig göra dem omöjliga att urskilja. För att testa dess betydelse tog författarna bort dessa adversariella delar och observerade hur prestationen förändrades. Utan dem blev subtyp‑prediktionerna mindre precisa och klustren i det gemensamma rummet blev suddigare och mer överlappande. När adversariell anpassning hölls endast på single‑omics‑nivå men inte i det gemensamma multi‑omics‑rummet förbättrades resultaten något men låg fortfarande efter den fullständiga modellen. Dessa experiment visar att det är avgörande för robust integration att aktivt tvinga modellen att bortse från batch‑specifika signaler både på individ‑ och sammansatt nivå.
Vad detta betyder för framtida studier
MoDAmix erbjuder ett generellt recept för att rengöra och förena multi‑omics‑data från många källor, vilket gör det enklare att hitta pålitliga mönster i hjärnans cellmångfald, cancersubtyper och bortom. Genom att noggrant separera tekniskt brus från genuina biologiska skillnader tillåter det forskare att sammanföra information över kohorter utan att förlora de subtila signaler som är viktiga för diagnos, prognos eller behandlingsval. Allteftersom multi‑omics‑projekt växer kan verktyg som MoDAmix bli avgörande för att omvandla stora, röriga dataset till tydliga, handlingsbara insikter.
Citering: Choi, J., Chae, H. A unified framework for correcting batch effects and integrating multi-omics data. Sci Rep 16, 12341 (2026). https://doi.org/10.1038/s41598-026-42355-9
Nyckelord: multi‑omics‑integration, korrigering av batch‑effekter, cancersubtypning, single‑cell‑analys, domänanpassning