Clear Sky Science · it
Un quadro unificato per correggere gli effetti di batch e integrare dati multi‑omici
Perché conta combinare molti tipi di dati
La biologia moderna può misurare molti tipi di molecole nelle nostre cellule, da quali geni sono attivi a come il DNA è chimicamente marcato e quanto è compattato. Studiare questi strati insieme, noto come “multi‑omica”, può rivelare pattern nascosti in malattie come il cancro o nella rete del cervello. Ma poiché queste misurazioni sono costose, gli scienziati spesso combinano dati provenienti da diversi ospedali e laboratori, il che introduce differenze tecniche indesiderate che possono offuscare o addirittura nascondere segnali biologici reali. Questo articolo presenta MoDAmix, un nuovo metodo computazionale che pulisce e combina questi dataset complessi in modo che i ricercatori possano fidarsi di ciò che osservano.

Il problema dei batch di dati disordinati
Quando laboratori in tutto il mondo misurano campioni simili, raramente usano macchine, protocolli o tempistiche identiche. Queste differenze creano “effetti di batch” – anomalie sistematiche causate dalla tecnologia piuttosto che dalla biologia. Negli studi single‑omici, diversi strumenti cercano già di rimuovere questi artefatti, ma trattano ogni tipo di misura separatamente. Per i dati multi‑omici questo non basta. Se ogni strato viene pulito singolarmente, le diverse vedute molecolari dello stesso paziente o cellula possono allontanarsi, rompendo i collegamenti più informativi. Gli autori sostengono che ciò che serve è invece un approccio coordinato che pulisca tutti gli strati insieme mantenendo intatta la loro struttura condivisa.
Un nuovo modo per allineare molti strati di dati
MoDAmix affronta questa sfida prendendo spunto dall’“adattamento di dominio”, una strategia di machine learning usata per far funzionare modelli in contesti diversi, come immagini provenienti da fotocamere differenti. Il metodo procede in quattro passaggi. Primo, impara a rappresentare ciascun tipo di omica e a distinguere i sottotipi biologici usando un dataset etichettato “source”. Secondo, riduce gli effetti di batch all’interno di ciascuno strato omico addestrando il sistema a rendere campioni di studi diversi simili se rappresentano la stessa biologia. Terzo, unisce tutti i tipi di omica in uno spazio condiviso a bassa dimensionalità e di nuovo forza il modello a ignorare le differenze tecniche tra i dataset. Infine, affina i confini dei sottotipi facendo sì che il modello indovini le etichette per i dati “target” non etichettati e avvicini delicatamente i campioni dello stesso sottotipo verso centri comuni in questo spazio condiviso.
Mettere alla prova il metodo
I ricercatori hanno testato MoDAmix su tre compiti impegnativi. In uno studio single‑cell sul cervello adulto del topo, hanno combinato l’attività genica e l’accessibilità della cromatina per identificare tipi cellulari. In due studi sul cancro, hanno integrato l’espressione genica con la metilazione del DNA per classificare sottotipi di leucemia mieloide acuta e tumori cerebrali in coorti di pazienti indipendenti. Hanno confrontato MoDAmix con strumenti popolari di correzione del batch e con metodi più recenti di integrazione multi‑omica. Usando misure come l’accuratezza di classificazione e la qualità del clustering, MoDAmix ha prodotto costantemente raggruppamenti più puliti di cellule e pazienti. Mappe visive dei dati hanno mostrato che i campioni provenienti da batch diversi erano ben mescolati, mentre tipi cellulari o sottotipi tumorali distinti rimanevano chiaramente separati – cosa che metodi concorrenti spesso non riuscivano a ottenere.
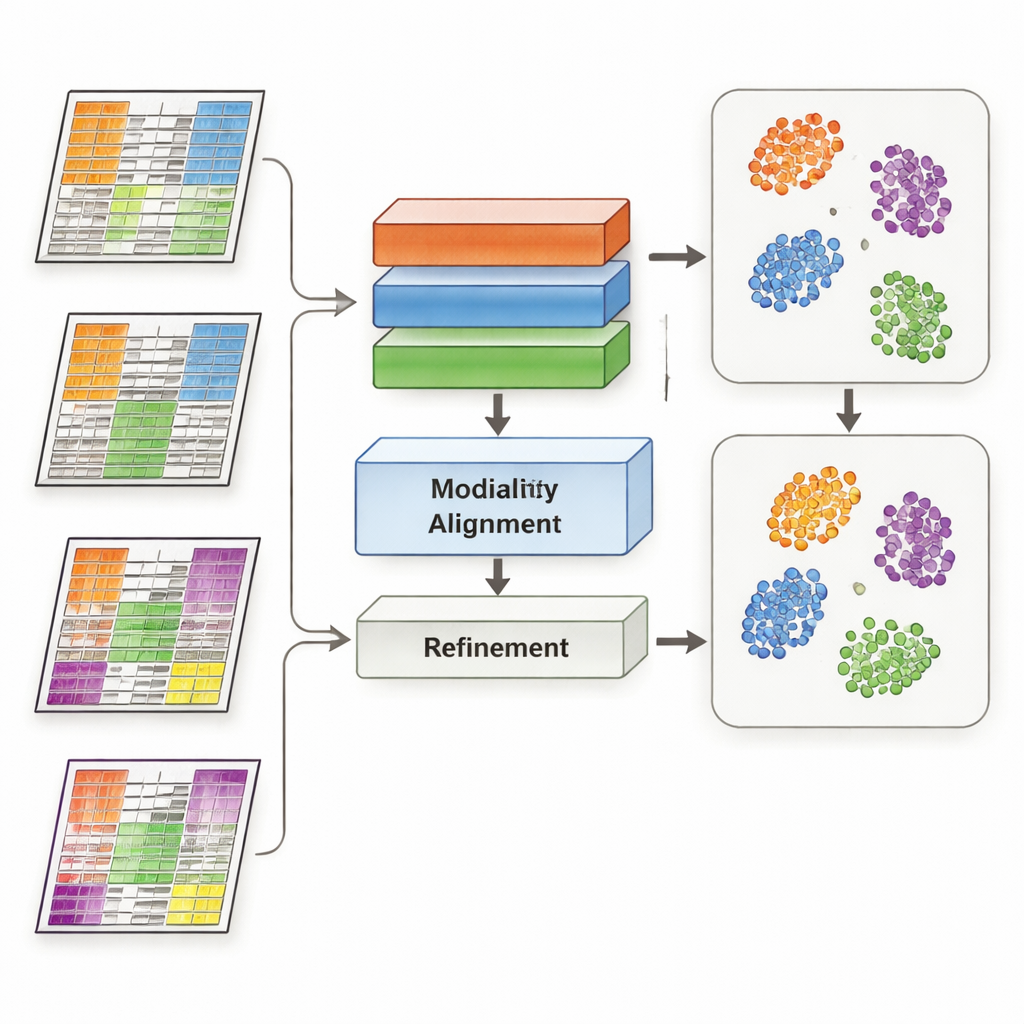
Perché l’apprendimento adversariale aiuta
Un ingrediente chiave in MoDAmix è l’apprendimento adversariale, in cui una parte del modello cerca di distinguere i batch mentre un’altra parte impara a renderli indistinguibili. Per valutarne l’importanza, gli autori hanno rimosso questi componenti adversarial e osservato come è cambiata la performance. Senza di essi, le predizioni dei sottotipi sono diventate meno accurate e i cluster nello spazio condiviso più sfumati e sovrapposti. Quando l’allineamento adversariale è stato mantenuto solo a livello single‑omico ma non nello spazio multi‑omico congiunto, i risultati sono migliorati in parte ma sono comunque rimasti inferiori al modello completo. Questi esperimenti mostrano che spingere attivamente il modello a ignorare segnali specifici del batch sia a livello individuale che combinato è cruciale per un’integrazione robusta.
Che cosa significa per studi futuri
MoDAmix offre una ricetta generale per pulire e unificare dati multi‑omici provenienti da molte fonti, facilitando l’individuazione di pattern affidabili nella diversità delle cellule cerebrali, nei sottotipi tumorali e oltre. Separando con cura il rumore tecnico dalle vere differenze biologiche, permette ai ricercatori di combinare informazioni tra coorti senza perdere i segnali sottili che contano per diagnosi, prognosi o scelta terapeutica. Con la crescita dei progetti multi‑omici, strumenti come MoDAmix potrebbero diventare essenziali per trasformare dataset vasti e disordinati in intuizioni chiare e utili.
Citazione: Choi, J., Chae, H. A unified framework for correcting batch effects and integrating multi-omics data. Sci Rep 16, 12341 (2026). https://doi.org/10.1038/s41598-026-42355-9
Parole chiave: integrazione multi‑omica, correzione degli effetti di batch, sottotipizzazione del cancro, analisi single‑cell, adattamento di dominio