Clear Sky Science · es
Un marco unificado para corregir efectos de lote e integrar datos multi-ómicos
Por qué importa mezclar muchos tipos de datos
La biología moderna puede medir muchos tipos de moléculas en nuestras células, desde qué genes están activos hasta cómo se etiqueta químicamente el ADN y qué tan compactado está. Estudiar estas capas conjuntamente, conocido como “multi-ómica”, puede revelar patrones ocultos en enfermedades como el cáncer o en el cableado del cerebro. Pero dado que estas mediciones son costosas, los científicos a menudo combinan datos de muchos hospitales y laboratorios, lo que introduce diferencias técnicas no deseadas que pueden difuminar o incluso ocultar señales biológicas reales. Este artículo presenta MoDAmix, un nuevo método computacional que limpia y combina conjuntos de datos complejos para que los investigadores puedan confiar en lo que observan.

El problema de los lotes desordenados
Cuando laboratorios de todo el mundo miden muestras similares, rara vez usan máquinas, protocolos o tiempos idénticos. Estas diferencias crean “efectos de lote”: peculiaridades sistemáticas causadas por la tecnología y no por la biología. En estudios de ómica única, ya existen varias herramientas que intentan eliminar estos artefactos, pero tratan cada tipo de medición por separado. Para datos multi-ómicos, eso no basta. Si cada capa se limpia de forma independiente, las diferentes vistas moleculares del mismo paciente o célula pueden desviarse entre sí, rompiendo los vínculos más informativos. Los autores sostienen que en su lugar se necesita un enfoque coordinado que limpie todas las capas a la vez manteniendo intacta su estructura compartida.
Una nueva forma de alinear muchas capas de datos
MoDAmix aborda este reto tomando ideas de la “adaptación de dominio”, una estrategia de aprendizaje automático usada para que los modelos funcionen en distintos entornos, como imágenes de diferentes cámaras. El método procede en cuatro pasos. Primero, aprende a representar cada tipo de ómica y a distinguir subtipos biológicos usando un conjunto de datos “origen” etiquetado. Segundo, reduce los efectos de lote dentro de cada capa ómica entrenando el sistema para que muestras de diferentes estudios parezcan similares si representan la misma biología. Tercero, reúne todos los tipos de ómica en un espacio compartido de baja dimensión y otra vez fuerza al modelo a ignorar las diferencias técnicas entre conjuntos de datos. Finalmente, afina los límites de los subtipos permitiendo que el modelo prediga etiquetas para los datos “destino” no etiquetados y acercando suavemente las muestras del mismo subtipo hacia centros comunes en este espacio compartido.
Poner el método a prueba
Los investigadores evaluaron MoDAmix en tres tareas exigentes. En un estudio de célula única del cerebro adulto de ratón, combinaron actividad génica y accesibilidad de la cromatina para identificar tipos celulares. En dos estudios de cáncer, integraron expresión génica con metilación del ADN para clasificar subtipos de leucemia mieloide aguda y tumores cerebrales en cohortes de pacientes independientes. Compararon MoDAmix con herramientas populares de corrección de lote y con métodos más recientes de integración multi-ómica. Usando medidas como la precisión de clasificación y la calidad del agrupamiento, MoDAmix produjo de forma consistente agrupamientos más limpios de células y pacientes. Mapas visuales de los datos mostraron que las muestras de distintos lotes estaban bien mezcladas, mientras que los tipos celulares o subtipos tumorales seguían claramente separados, algo que los métodos competidores a menudo no lograron.
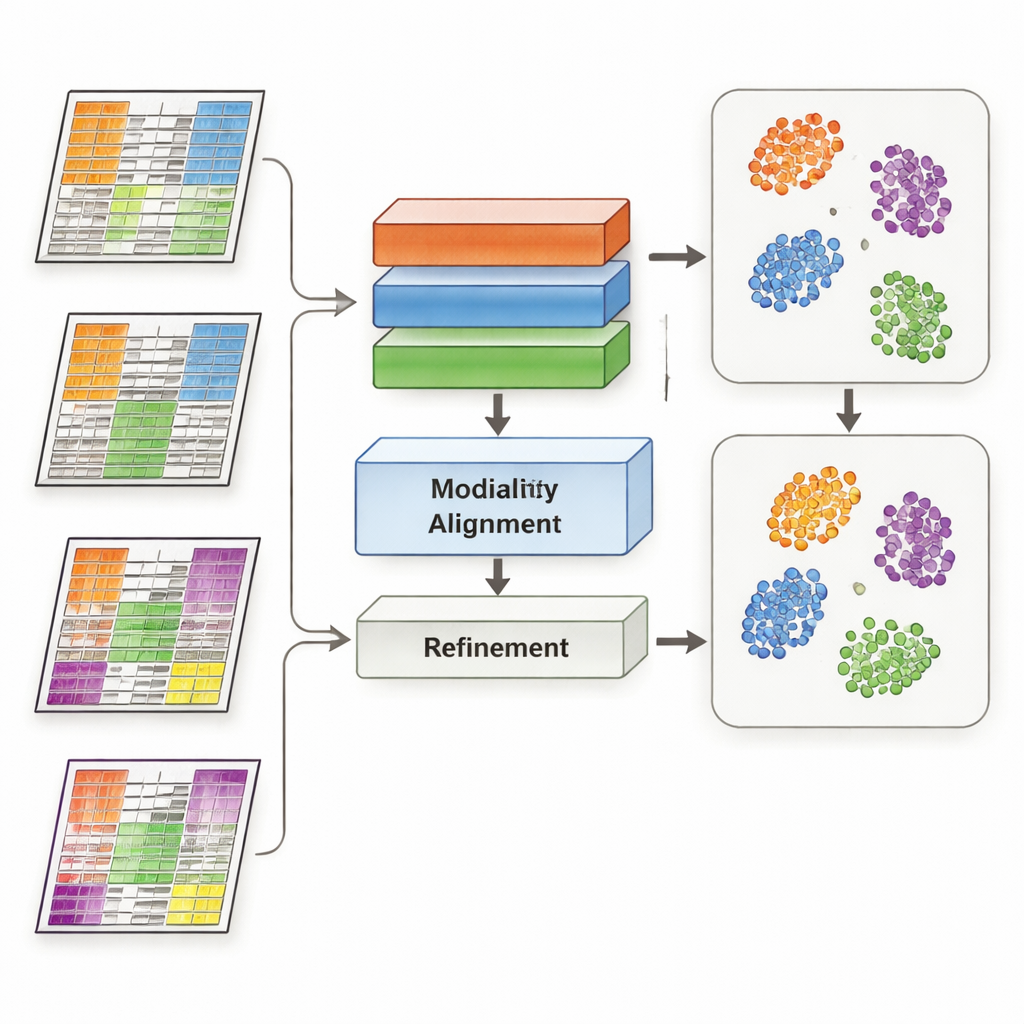
Por qué ayuda el aprendizaje adversarial
Un ingrediente clave en MoDAmix es el aprendizaje adversarial, en el que una parte del modelo intenta distinguir los lotes mientras otra aprende a hacerlos indistinguibles. Para probar su importancia, los autores eliminaron estos componentes adversariales y observaron cómo cambiaba el rendimiento. Sin ellos, las predicciones de subtipo se volvieron menos precisas y los agrupamientos en el espacio compartido se hicieron más difusos y solapados. Cuando la alineación adversarial se mantuvo solo a nivel de ómica única pero no en el espacio multi-ómico conjunto, los resultados mejoraron algo pero aún quedaron por detrás del modelo completo. Estos experimentos muestran que empujar activamente al modelo a ignorar señales específicas de lote tanto a nivel individual como combinado es crucial para una integración robusta.
Qué significa esto para estudios futuros
MoDAmix ofrece una receta general para limpiar y unificar datos multi-ómicos procedentes de muchas fuentes, facilitando la identificación de patrones fiables en la diversidad de células cerebrales, subtipos de cáncer y más. Al separar cuidadosamente el ruido técnico de las diferencias biológicas genuinas, permite a los investigadores reunir información entre cohortes sin perder las señales sutiles que importan para el diagnóstico, el pronóstico o la elección del tratamiento. A medida que los proyectos multi-ómicos siguen creciendo, herramientas como MoDAmix podrían volverse esenciales para convertir conjuntos de datos vastos y desordenados en conocimientos claros y aplicables.
Cita: Choi, J., Chae, H. A unified framework for correcting batch effects and integrating multi-omics data. Sci Rep 16, 12341 (2026). https://doi.org/10.1038/s41598-026-42355-9
Palabras clave: integración multi-ómica, corrección de efectos de lote, subtipificación del cáncer, análisis de célula única, adaptación de dominio