Clear Sky Science · ru
Унифицированная методика для коррекции эффектов пакетов и интеграции мультиомных данных
Почему важно сочетать разные типы данных
Современная биология позволяет измерять множество видов молекул в клетках — от активности генов до химических меток на ДНК и степени её упаковки. Совместное изучение этих слоёв, называемое «мульти‑омикой», может выявлять скрытые закономерности при заболеваниях, например раке, или в организации мозга. Но поскольку такие измерения дороги, учёные часто объединяют данные из разных больниц и лабораторий, что вносит нежелательные технические различия, размывающие или даже скрывающие истинные биологические сигналы. В этой работе представлена MoDAmix — новая вычислительная методика, которая очищает и объединяет такие сложные наборы данных, чтобы исследователи могли доверять полученным результатам.

Проблема несовместимых наборов данных
Когда лаборатории по всему миру измеряют похожие образцы, они редко используют одинаковые приборы, протоколы или расписание. Эти различия создают «эффекты пакетов» — систематические искажения, вызванные технологией, а не биологией. В исследованиях одиночного омиса уже существуют инструменты для удаления таких артефактов, но они обрабатывают каждый тип измерений по‑отдельности. Для мультиомных данных этого недостаточно. Если очищать каждый слой отдельно, разные молекулярные представления одного пациента или клетки могут расходиться, теряя информативные связи. Авторы утверждают, что нужен скоординированный подход, который очищает все слои одновременно, сохраняя их общую структуру.
Новый способ согласовать многочисленные слои данных
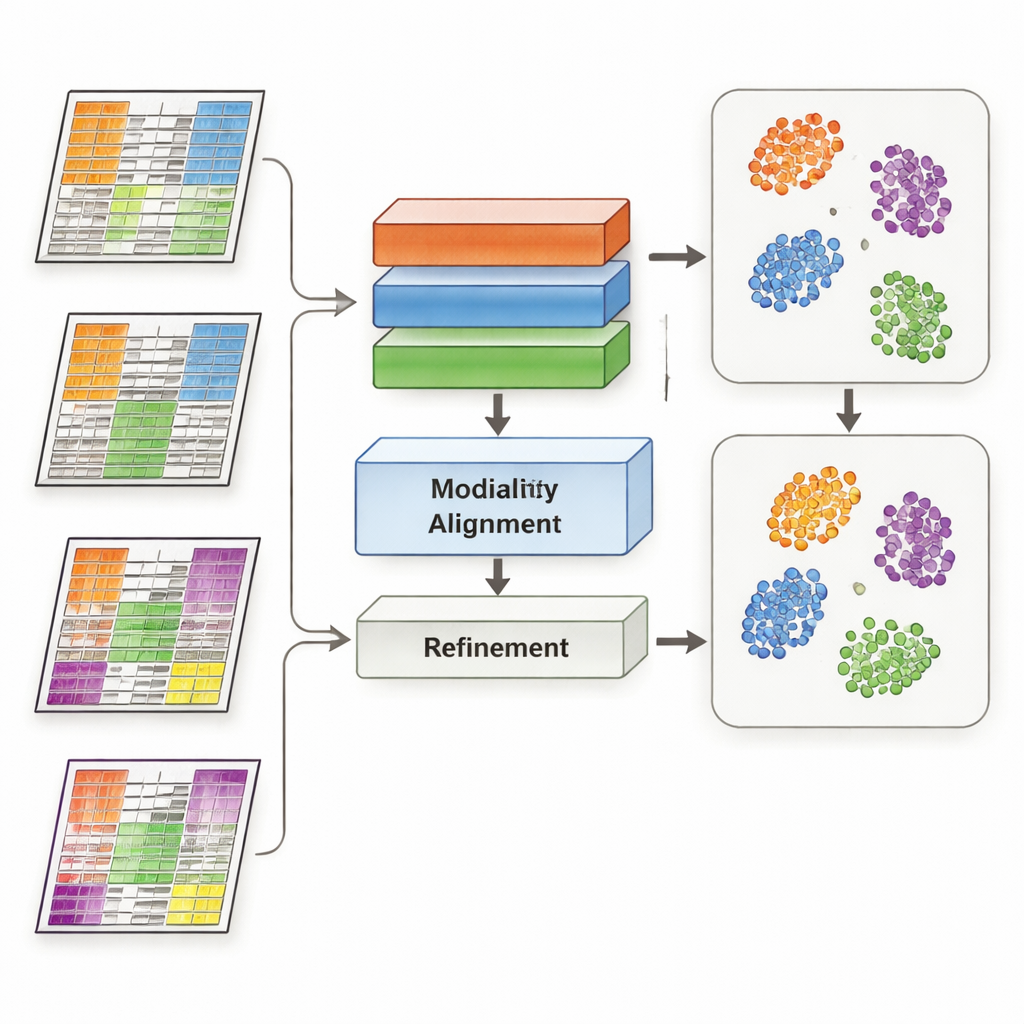
MoDAmix решает эту задачу, заимствуя идеи из «адаптации доменов» — стратегии машинного обучения, используемой для того, чтобы модели работали в разных условиях, например с изображениями с разных камер. Метод выполняется в четыре шага. Сначала он учится представлять каждый тип омics и различать биологические подтипы, используя размеченный «источник». Во‑вторых, он уменьшает эффекты пакетов в каждом омис‑слое, обучая систему делать так, чтобы образцы из разных исследований выглядели похоже, если они отражают одну и ту же биологию. В‑третьих, все типы омics объединяются в общее низкоразмерное пространство, и модель снова заставляют игнорировать технические различия между наборами данных. Наконец, границы подтипов уточняются: модель угадывает метки для неразмеченных «целевых» данных и аккуратно притягивает образцы одного подтипа к общим центрам в этом общем пространстве.
Проверка метода на практике
Исследователи испытали MoDAmix на трёх сложных задачах. В исследовании одиночных клеток взрослого мозга мыши они объединили данные об активности генов и доступности хроматина, чтобы выделить типы клеток. В двух онкологических исследованиях они интегрировали экспрессию генов с метилированием ДНК для классификации подтипов острого миелоидного лейкоза и опухолей мозга в независимых когортах пациентов. MoDAmix сравнивали с популярными инструментами коррекции эффектов пакетов и с новыми методами интеграции мультиомики. По таким метрикам, как точность классификации и качество кластеризации, MoDAmix последовательно давал более чистые группировки клеток и пациентов. Визуализации данных показывали, что образцы из разных пакетов хорошо перемешаны, тогда как отдельные типы клеток или подтипы опухолей оставались чётко разделёнными — то, чего часто не удавалось добиться конкурентам.
Почему полезно состязательное обучение
Ключевой компонент MoDAmix — состязательное (адверсариальное) обучение, в котором одна часть модели пытается различать пакеты, а другая учится делать их неотличимыми. Чтобы оценить важность этого приёма, авторы убрали состязательные блоки и посмотрели на изменения в результатах. Без них прогнозы подтипов стали менее точными, а кластеры в общем пространстве — более размытыми и перекрывающимися. Когда адверсариальная выравнивающая компонента сохранялась только для отдельных омис‑слоёв, но не применялась в объединённом мультиомном пространстве, результаты улучшались частично, но всё же отставали от полной модели. Эти эксперименты показывают, что активное подавление сигналов, специфичных для пакетов, как на уровне отдельных слоёв, так и в объединённом пространстве, критично для надёжной интеграции.
Значение для будущих исследований
MoDAmix предлагает общий рецепт для очистки и объединения мультиомных данных из разных источников, что облегчает обнаружение надёжных закономерностей в разнообразии клеток мозга, подтипах рака и других областях. Тщательно разделяя технический шум и истинные биологические различия, метод позволяет объединять информацию по когортам, не теряя тонких сигналов, важных для диагностики, прогноза или выбора лечения. По мере роста проектов по мультиомике инструменты вроде MoDAmix могут стать необходимыми для превращения огромных, неупорядоченных наборов данных в понятные и применимые выводы.
Цитирование: Choi, J., Chae, H. A unified framework for correcting batch effects and integrating multi-omics data. Sci Rep 16, 12341 (2026). https://doi.org/10.1038/s41598-026-42355-9
Ключевые слова: интеграция мультиомики, коррекция эффектов пакетов, типирование рака, анализ одиночных клеток, адаптация доменов