Clear Sky Science · pl
Ujednolicone ramy korekcji efektów partii i integracji danych wielo-omicznych
Dlaczego mieszanie wielu typów danych ma znaczenie
Nowoczesna biologia potrafi mierzyć wiele rodzajów cząsteczek w komórkach — od aktywności genów po chemiczne znaczniki DNA i stopień jego upakowania. Badanie tych warstw razem, zwane „wielo-omics”, może ujawnić ukryte wzorce w chorobach takich jak rak czy w sieciowaniach mózgu. Ponieważ jednak takie pomiary są kosztowne, naukowcy często łączą dane z wielu szpitali i laboratoriów, co wprowadza niepożądane techniczne różnice mogące rozmyć lub ukryć prawdziwe sygnały biologiczne. W artykule przedstawiono MoDAmix — nową metodę obliczeniową, która oczyszcza i łączy takie złożone zbiory danych, tak by badacze mogli ufać wynikom.

Problem niejednolitych partii danych
Kiedy laboratoria na całym świecie mierzą podobne próbki, rzadko korzystają z identycznych maszyn, protokołów czy harmonogramów. Te różnice powodują „efekty partii” — systematyczne artefakty wynikające z technologii, a nie biologii. W badaniach pojedynczego omics istnieje już kilka narzędzi próbujących usuwać takie zakłócenia, ale traktują one każdy typ pomiaru oddzielnie. W przypadku wielo-omics to nie wystarcza. Jeśli każdą warstwę oczyszcza się osobno, różne molekularne widoki tej samej osoby lub komórki mogą się rozjechać, niszcząc powiązania najbardziej informacyjne. Autorzy argumentują, że potrzebne jest skoordynowane podejście, które oczyszcza wszystkie warstwy razem, zachowując ich wspólną strukturę.
Nowy sposób wyrównywania wielu warstw danych
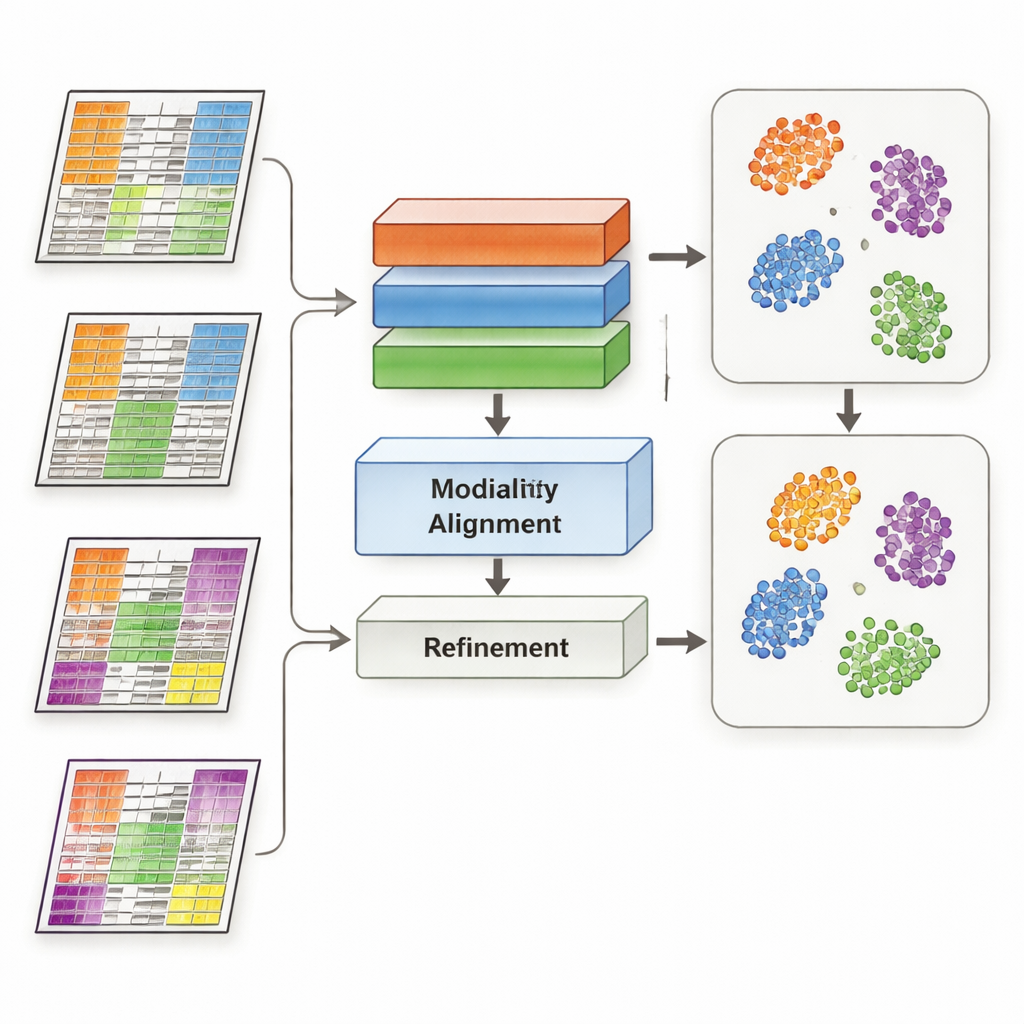
MoDAmix stawia czoła temu wyzwaniu, zapożyczając pomysły z „adaptacji domeny”, strategii uczenia maszynowego stosowanej do sprawiania, by modele działały w różnych warunkach, na przykład przy obrazach z różnych kamer. Metoda działa w czterech krokach. Najpierw uczy się reprezentacji każdego typu omics i rozróżniania podtypów biologicznych na oznakowanym zbiorze „źródłowym”. Po drugie, redukuje efekty partii w każdej warstwie omics, trenując system tak, by próbki z różnych badań wyglądały podobnie, jeśli reprezentują tę samą biologię. Po trzecie, scala wszystkie typy omics w wspólną niskowymiarową przestrzeń i ponownie wymusza, by model ignorował techniczne różnice między zbiorami danych. Na koniec ostrzy granice podtypów, pozwalając modelowi zgadywać etykiety dla nieoznakowanych danych „docelowych” i delikatnie przyciągając próbki tego samego podtypu do wspólnych środków w tej wspólnej przestrzeni.
Przetestowanie metody
Naukowcy przetestowali MoDAmix na trzech wymagających zadaniach. W badaniu pojedynczych komórek dorosłego mózgu myszy połączyli aktywność genów i dostępność chromatyny, by identyfikować typy komórek. W dwóch badaniach nad nowotworami zintegrowali ekspresję genów z metylacją DNA, by klasyfikować podtypy ostrej białaczki szpikowej i nowotworów mózgu w niezależnych kohortach pacjentów. Porównali MoDAmix z popularnymi narzędziami do korekcji efektów partii oraz z nowszymi metodami integracji wielo-omics. Na miarach takich jak dokładność klasyfikacji i jakość klasteryzacji, MoDAmix konsekwentnie dawał czystrze grupowania komórek i pacjentów. Mapy wizualne danych pokazały, że próbki z różnych partii były dobrze wymieszane, podczas gdy odrębne typy komórek czy podtypy guzów pozostawały wyraźnie oddzielone — coś, czego konkurencyjne metody często nie osiągały.
Dlaczego uczenie adwersarialne pomaga
Kluczowym składnikiem MoDAmix jest uczenie adwersarialne, w którym jedna część modelu próbuje rozróżnić partie, podczas gdy inna uczy się sprawiać, by stały się nierozróżnialne. Aby ocenić jego rolę, autorzy usunęli te adwersarialne elementy i obserwowali zmiany w wydajności. Bez nich przewidywania podtypów stały się mniej dokładne, a klastry we wspólnej przestrzeni mniej wyraźne i bardziej zachodzące na siebie. Gdy adwersarialne wyrównanie utrzymano tylko na poziomie pojedynczego omics, ale nie w wspólnej przestrzeni multi-omics, wyniki nieco się poprawiły, lecz nadal ustępowały pełnemu modelowi. Eksperymenty te pokazują, że aktywne wymuszanie ignorowania sygnałów specyficznych dla partii zarówno na poziomie poszczególnych warstw, jak i w przestrzeni połączonej, jest kluczowe dla solidnej integracji.
Co to oznacza dla przyszłych badań
MoDAmix oferuje ogólny przepis na oczyszczanie i scalanie danych wielo-omics pochodzących z wielu źródeł, ułatwiając odnajdywanie wiarygodnych wzorców w różnorodności komórek mózgowych, podtypach nowotworów i nie tylko. Poprzez staranne oddzielenie technicznego szumu od prawdziwych różnic biologicznych pozwala badaczom łączyć informacje z różnych kohort bez utraty subtelnych sygnałów istotnych dla diagnozy, rokowania czy wyboru terapii. W miarę rozwoju projektów wielo-omics narzędzia takie jak MoDAmix mogą stać się niezbędne do przekształcania ogromnych, nieuporządkowanych zbiorów danych w czytelne, praktyczne wnioski.
Cytowanie: Choi, J., Chae, H. A unified framework for correcting batch effects and integrating multi-omics data. Sci Rep 16, 12341 (2026). https://doi.org/10.1038/s41598-026-42355-9
Słowa kluczowe: integracja wielo-omics, korekcja efektów partii, podtypowanie nowotworów, analiza pojedynczych komórek, adaptacja domeny