Clear Sky Science · pt
Uma estrutura unificada para corrigir efeitos de lote e integrar dados multiômicos
Por que misturar muitos tipos de dados importa
A biologia moderna consegue medir muitos tipos de moléculas em nossas células, desde quais genes estão ativos até como o DNA é quimicamente marcado e quão compactado ele está. Estudar essas camadas em conjunto, conhecido como “multi‑ômica”, pode revelar padrões ocultos em doenças como o câncer ou na organização do cérebro. Mas como essas medições são caras, os cientistas frequentemente combinam dados de diversos hospitais e laboratórios, o que introduz diferenças técnicas indesejadas que podem borrar ou até ocultar sinais biológicos reais. Este artigo apresenta o MoDAmix, um novo método computacional que limpa e integra esses conjuntos de dados complexos para que os pesquisadores possam confiar no que observam.

O problema dos lotes de dados desorganizados
Quando laboratórios ao redor do mundo medem amostras semelhantes, raramente usam máquinas, protocolos ou cronogramas idênticos. Essas diferenças criam “efeitos de lote” — particularidades sistemáticas causadas pela tecnologia em vez da biologia. Em estudos de ômica única, várias ferramentas já tentam remover esses artefatos, mas tratam cada tipo de medição isoladamente. Para dados multiômicos, isso não é suficiente. Se cada camada for limpa separadamente, as diferentes visões moleculares de um mesmo paciente ou célula podem se afastar, rompendo as conexões mais informativas. Os autores argumentam que o que é necessário é uma abordagem coordenada que limpe todas as camadas simultaneamente, preservando a estrutura compartilhada entre elas.
Uma nova forma de alinhar múltiplas camadas de dados
O MoDAmix enfrenta esse desafio trazendo ideias da “adaptação de domínio”, uma estratégia de aprendizado de máquina usada para fazer modelos funcionarem em contextos diferentes, como imagens de câmeras distintas. O método avança em quatro etapas. Primeiro, aprende como representar cada tipo ômico e como distinguir subtipos biológicos usando um conjunto de dados rotulado de “origem”. Segundo, reduz efeitos de lote dentro de cada camada ômica treinando o sistema para fazer com que amostras de diferentes estudos pareçam semelhantes se representam a mesma biologia. Terceiro, reúne todos os tipos ômicos em um espaço compartilhado de baixa dimensão e novamente força o modelo a ignorar diferenças técnicas entre conjuntos de dados. Finalmente, aprimora os limites entre subtipos permitindo que o modelo estime rótulos para os dados “alvo” não rotulados e, suavemente, puxe amostras do mesmo subtipo para centros comuns nesse espaço compartilhado.
Colocando o método à prova
Os pesquisadores testaram o MoDAmix em três tarefas exigentes. Em um estudo de célula única do cérebro adulto de camundongo, combinaram atividade gênica e acessibilidade de cromatina para identificar tipos celulares. Em dois estudos de câncer, integraram expressão gênica com metilação do DNA para classificar subtipos de leucemia mieloide aguda e tumores cerebrais em coortes de pacientes independentes. Compararam o MoDAmix com ferramentas populares de correção de lote e com métodos mais recentes de integração multiômica. Usando medidas como acurácia de classificação e qualidade de agrupamento, o MoDAmix produziu consistentemente agrupamentos mais claros de células e pacientes. Mapas visuais dos dados mostraram que amostras de diferentes lotes ficaram bem misturadas, enquanto tipos celulares distintos ou subtipos tumorais permaneceram claramente separados — algo que métodos concorrentes frequentemente não conseguem alcançar.
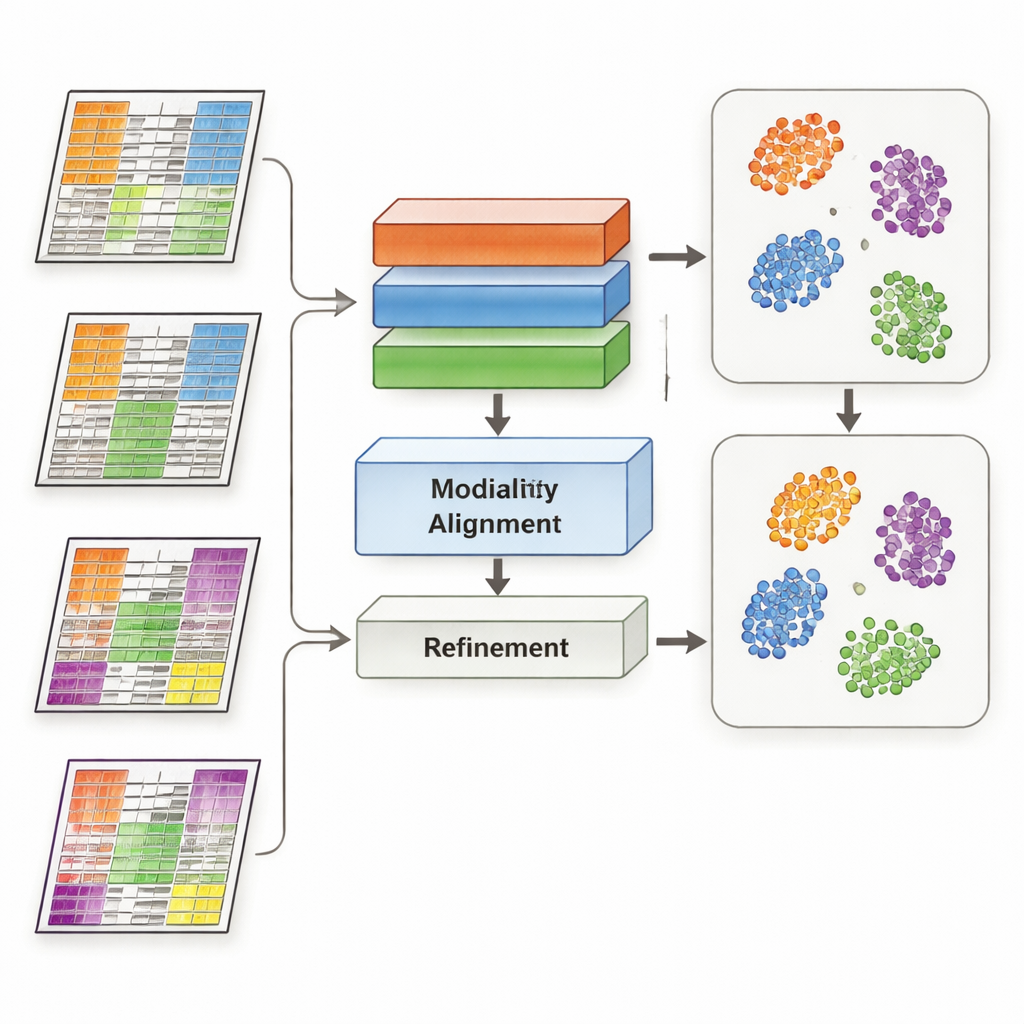
Por que o aprendizado adversarial ajuda
Um ingrediente chave no MoDAmix é o aprendizado adversarial, em que uma parte do modelo tenta distinguir os lotes enquanto outra parte aprende a torná‑los indistinguíveis. Para testar sua importância, os autores removeram esses componentes adversariais e observaram como o desempenho mudou. Sem eles, as previsões de subtipo ficaram menos precisas e os agrupamentos no espaço compartilhado tornaram‑se mais difusos e sobrepostos. Quando o alinhamento adversarial foi mantido apenas ao nível de cada ômica, mas não no espaço multiômico conjunto, os resultados melhoraram em certa medida, mas ainda ficaram aquém do modelo completo. Estes experimentos mostram que forçar ativamente o modelo a ignorar sinais específicos de lote tanto em níveis individuais quanto combinados é crucial para uma integração robusta.
O que isso significa para estudos futuros
O MoDAmix oferece uma receita geral para limpar e unificar dados multiômicos de múltiplas fontes, tornando mais fácil encontrar padrões confiáveis na diversidade de células cerebrais, em subtipos de câncer e além. Ao separar cuidadosamente o ruído técnico das diferenças biológicas genuínas, ele permite que os pesquisadores agreguem informações entre coortes sem perder os sinais sutis que importam para diagnóstico, prognóstico ou escolha de tratamento. À medida que projetos multiômicos continuam a crescer, ferramentas como o MoDAmix podem se tornar essenciais para transformar conjuntos de dados vastos e desordenados em insights claros e acionáveis.
Citação: Choi, J., Chae, H. A unified framework for correcting batch effects and integrating multi-omics data. Sci Rep 16, 12341 (2026). https://doi.org/10.1038/s41598-026-42355-9
Palavras-chave: integração multiômica, correção de efeitos de lote, subtipagem de câncer, análise de célula única, adaptação de domínio