Clear Sky Science · fr
Un cadre unifié pour corriger les effets de lot et intégrer des données multi-omiques
Pourquoi il est important de fusionner de nombreux types de données
La biologie moderne peut mesurer de nombreux types de molécules dans nos cellules, depuis les gènes actifs jusqu’à la façon dont l’ADN est chimiquement marqué et compacté. Étudier ces couches ensemble, appelé « multi‑omique », peut révéler des motifs cachés dans des maladies comme le cancer ou dans l’organisation du cerveau. Mais comme ces mesures sont coûteuses, les scientifiques combinent souvent des données provenant de plusieurs hôpitaux et laboratoires, ce qui introduit des différences techniques indésirables susceptibles d’estomper voire de masquer de vrais signaux biologiques. Cet article présente MoDAmix, une nouvelle méthode computationnelle qui nettoie et combine ces jeux de données complexes afin que les chercheurs puissent avoir confiance dans leurs observations.

Le problème des lots de données hétérogènes
Lorsque des laboratoires du monde entier mesurent des échantillons similaires, ils n’utilisent rarement des machines, des protocoles ou des calendriers identiques. Ces différences créent des « effets de lot » — des particularités systématiques causées par la technologie plutôt que par la biologie. Dans les études mono‑omiques, plusieurs outils cherchent déjà à retirer ces artefacts, mais ils traitent chaque type de mesure séparément. Pour les données multi‑omiques, cela ne suffit pas. Si chaque couche est nettoyée indépendamment, les différentes vues moléculaires d’un même patient ou d’une même cellule peuvent diverger, rompant les liens les plus informatifs. Les auteurs soutiennent qu’il faut plutôt une approche coordonnée qui nettoie toutes les couches conjointement tout en préservant leur structure partagée.
Une nouvelle façon d’aligner plusieurs couches de données
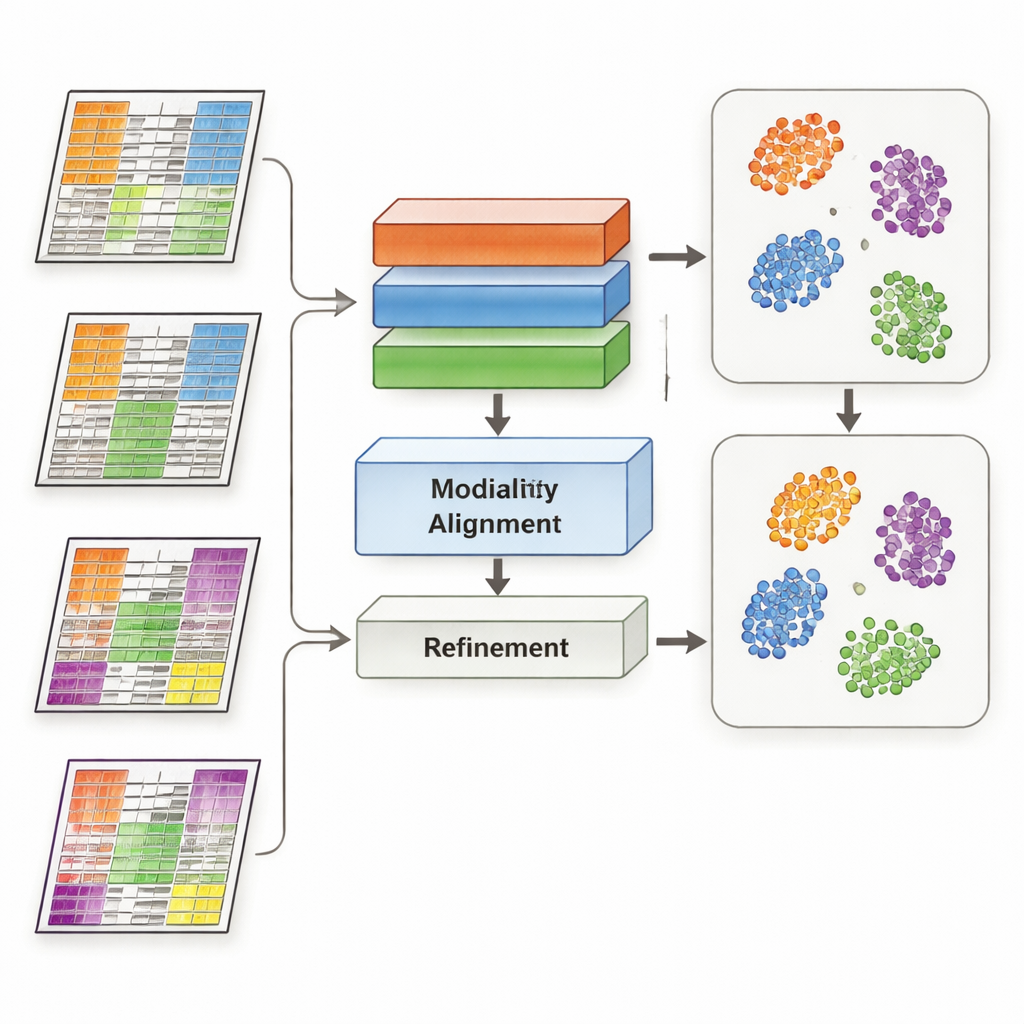
MoDAmix relève ce défi en empruntant des idées à l’« adaptation de domaine », une stratégie d’apprentissage automatique utilisée pour rendre les modèles opérationnels dans des contextes différents, par exemple des images prises par des caméras différentes. La méthode se déroule en quatre étapes. D’abord, elle apprend à représenter chaque type d’omique et à distinguer des sous‑types biologiques en utilisant un jeu de données « source » étiqueté. Ensuite, elle réduit les effets de lot au sein de chaque couche omique en entraînant le système à rendre similaires des échantillons provenant d’études différentes s’ils représentent la même biologie. Troisièmement, elle rassemble tous les types d’omique dans un espace commun de faible dimension et contraint à nouveau le modèle à ignorer les différences techniques entre jeux de données. Enfin, elle affine les frontières des sous‑types en laissant le modèle deviner les étiquettes pour les données « cible » non étiquetées et en rapprochant doucement les échantillons du même sous‑type vers des centres communs dans cet espace partagé.
Évaluer la méthode
Les chercheurs ont testé MoDAmix sur trois tâches exigeantes. Dans une étude en cellule unique sur le cerveau d’une souris adulte, ils ont combiné l’activité génique et l’accessibilité de la chromatine pour identifier les types cellulaires. Dans deux études sur le cancer, ils ont intégré l’expression génique avec la méthylation de l’ADN pour classer les sous‑types de leucémie myéloïde aiguë et de tumeurs cérébrales à travers des cohortes de patients indépendantes. Ils ont comparé MoDAmix à des outils populaires de correction de lot et à des méthodes plus récentes d’intégration multi‑omique. À l’aide de mesures telles que la précision de classification et la qualité de regroupement, MoDAmix a systématiquement produit des groupements de cellules et de patients plus clairs. Les cartes visuelles des données montraient que les échantillons provenant de différents lots étaient bien mélangés, tandis que les types cellulaires ou sous‑types de tumeur distincts restaient nettement séparés — ce que les méthodes concurrentes réussissaient souvent moins bien.
Pourquoi l’apprentissage antagoniste est utile
Un ingrédient clé de MoDAmix est l’apprentissage antagoniste, dans lequel une partie du modèle tente de distinguer les lots tandis qu’une autre partie apprend à les rendre indiscernables. Pour évaluer son importance, les auteurs ont retiré ces éléments antagonistes et observé l’impact sur les performances. Sans eux, les prédictions de sous‑type devenaient moins précises et les grappes dans l’espace partagé se faisaient plus floues et plus chevauchantes. Lorsque l’alignement antagoniste était conservé uniquement au niveau mono‑omique mais pas dans l’espace multi‑omique conjoint, les résultats s’amélioraient quelque peu mais restaient inférieurs au modèle complet. Ces expériences montrent qu’inciter activement le modèle à ignorer les signaux spécifiques aux lots aux niveaux individuel et combiné est crucial pour une intégration robuste.
Ce que cela implique pour les études futures
MoDAmix propose une recette générale pour nettoyer et unifier des données multi‑omiques provenant de nombreuses sources, facilitant la découverte de motifs fiables dans la diversité des cellules cérébrales, les sous‑types de cancer et au‑delà. En séparant soigneusement le bruit technique des différences biologiques réelles, il permet aux chercheurs de regrouper des informations entre cohortes sans perdre les signaux subtils qui comptent pour le diagnostic, le pronostic ou le choix thérapeutique. À mesure que les projets multi‑omiques grandissent, des outils comme MoDAmix pourraient devenir essentiels pour transformer des jeux de données vastes et désordonnés en connaissances claires et exploitables.
Citation: Choi, J., Chae, H. A unified framework for correcting batch effects and integrating multi-omics data. Sci Rep 16, 12341 (2026). https://doi.org/10.1038/s41598-026-42355-9
Mots-clés: intégration multi-omique, correction des effets de lot, sous-typage du cancer, analyse en cellule unique, adaptation de domaine