Clear Sky Science · sv
Utvärdering av ruttstabilitet och samordning i svärmbaserade multiagent-uppgiftsorienterade dialogsystem
Varför smartare chattbotar spelar roll
Chattbotar blir snabbt den första kontaktpunkten när du bokar hotell, ändrar ett flyg eller ber ett företag om hjälp. Men så fort en konversation hoppar mellan uppgifter — till exempel att hitta en restaurang, kolla ett tågschema och betala en räkning — börjar dagens system ofta svaja. Denna artikel tittar under huven på ”svärm-liknande” assistenter bestående av många små specialiserade botar som styrs av en central controller, och ställer en enkel men avgörande fråga: hur vet vi att detta interna samarbete faktiskt är stabilt och pålitligt, inte bara flytande vid ytan?
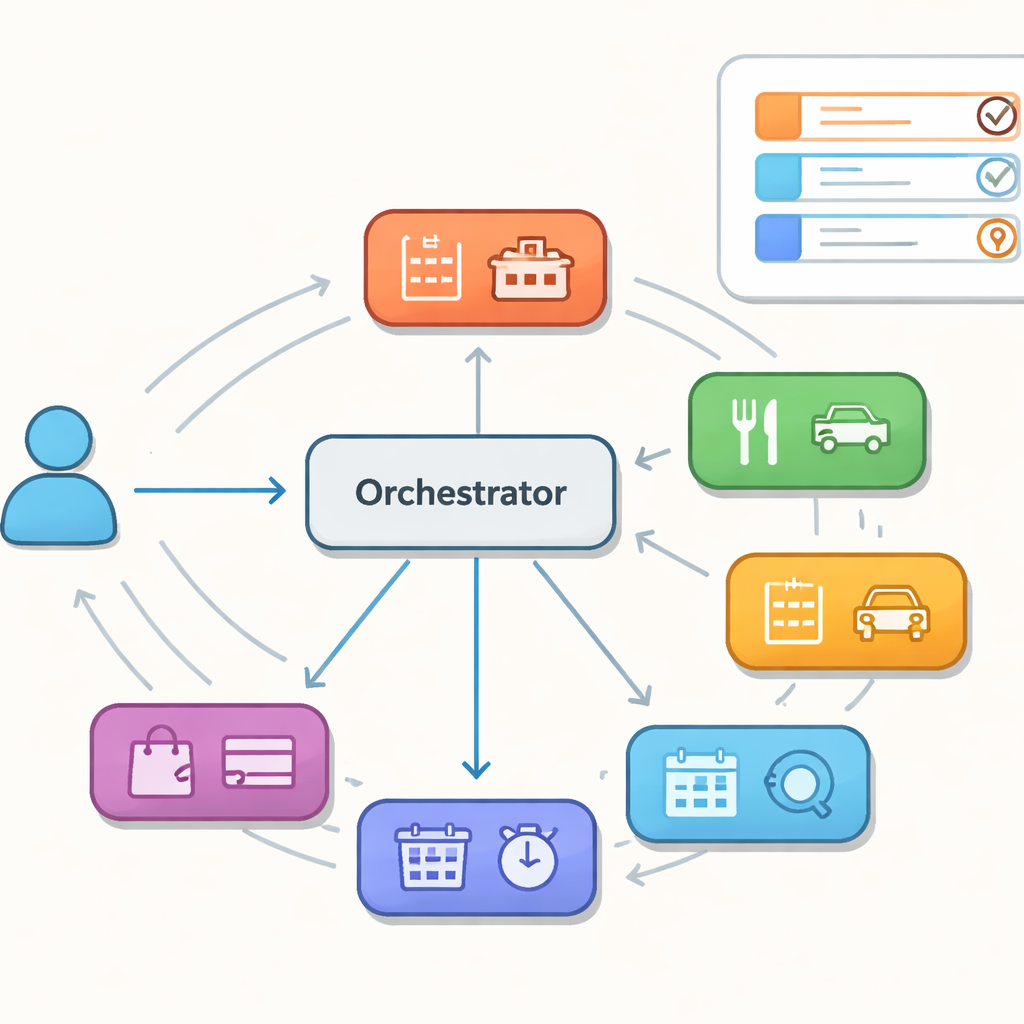
Många hjälpare, en dirigent
I stället för en jätte-modell som hanterar allt studerar författarna assistenter byggda av en samling specialistagenter, var och en skicklig inom ett snävt domän såsom hotell, restauranger eller taxi. En central orkestrator avgör, tur för tur, vilken specialist som ska agera härnäst och håller ett delat minne av vad användaren hittills vill. Denna uppsättning, ibland liknad vid en svärm av samarbetande agenter, lovar flexibilitet och enklare underhåll. Den skapar dock också nya felmodi: controllern kan skicka en tur till fel specialist, snurra i cirklar mellan agenter eller misslyckas med att hålla det delade minnet konsekvent när kontrollen växlar. Dessa dolda misstag syns kanske inte i ett enstaka svar, men de kan stjälpa längre samtal.
Mäta lagarbete, inte bara prat
För att gå bortom anekdotiska demo bygger författarna en ”utvärderingsförst”-pipeline ovanpå en populär flerdomän-dialogdatamängd kallad MultiWOZ 2.2. De skiljer medvetet åt två delar: en routingmodell som väljer specialisten, och en språkgenerator som genererar systemets åtgärder och uppdaterar den delade tron om användarens mål. Genom att avkoppla dessa kan de precisa var problemen kommer från — dålig delegering eller bristfällig språkproduktion. De definierar sedan koordinationsfokuserade mätvärden: om den valda specialisten matchar den sanna domänen för den turen, hur mycket framsteg systemet gör med att fylla i nödvändiga detaljer som datum och platser, hur ofta det byter eller studsar mellan agenter, om det hamnar i loopar, och hur väl det återhämtar sig efter tidiga misstag.
Sätta systemet under stress
Teamet stannar inte vid statiska testkonversationer. De introducerar stresstester som efterliknar friktion i verkliga världen: användare som omformulerar förfrågningar, korrigerar tidigare information efter många turer eller verktyg som svarar långsamt. Dessa perturbationer behåller de ursprungliga uppgifterna men stör kontexten som routern ser, vilket gör det möjligt för forskarna att kontrollera hur robust orkestreringen är när verkligheten avviker från de prydliga, annoterade manus som finns i datamängden. De följer också ”kaskadfel” — situationer där en liten tidig svikt i routing eller tillståndsspårning dramatiskt ökar risken att hela uppgiften senare kollapsar och lämnar viktiga begränsningar ouppfyllda.
Vad gör routningen stabilare
Med en DeBERTa-baserad modell som router och en FLAN-T5-modell som generator jämför författarna flera routingpolicys, inklusive enkla regler och inlärda modeller med och utan förtroendebaserade skydd. En huvudfynd är att lägga till förtroende-aware grindning — att bara agera när routern är tillräckligt säker, och annars falla tillbaka till säkrare beteende — kraftigt minskar instabila överlämningar. I deras huvudinställning stiger routingnoggrannheten till cirka 0,77, samtidigt som frekvensen av byten mellan agenter minskar och ”studs”-mönster, där systemet oscillerar fram och tillbaka, nästan försvinner. Samtidigt observerar de att vara alltför konservativ kan minska mängden användbara tillståndsuppdateringar som registreras, vilket blottlägger en spänning mellan att fatta precisa beslut och att stadigt avancera mot användarens mål.
Varför dessa lärdomar bär över
För att testa hur generella dessa insikter är applicerar författarna samma orkestrationsmätningar på en annan benchmark, Schema-Guided Dialogue-datamängden, som har andra domäner och scheman. Prestandan sjunker överlag, men de grundläggande samordningsproblemen består: felroutning och saknade tillståndsuppdateringar är fortfarande huvudboven, medan loopen är relativt sällsynt. Detta tyder på att de observerade mönstren inte är egenheter i en enskild datamängd utan speglar djupare utmaningar i att samordna många agenter över långa, skiftande konversationer.
Vad detta betyder för framtida assistenter
För icke-specialister är slutsatsen att bygga pålitliga multi-skill chattbotar handlar lika mycket om att organisera deras interna lagarbete som om att träna större språkmodeller. Artikeln erbjuder en konkret ritning och ett mått för att jämföra orkestreringsstrategier, och visar hur tidiga routingbeslut, tillståndsspårning och överlämningsbeteende tillsammans formar om en konversation tyst driver ur kurs eller framgångsrikt slutför komplexa uppgifter. Genom att lyfta fram kompromissen mellan noggrannhet och framsteg och genom att exponera hur små tidiga fel kan växa till stora problem ger arbetet systemdesigners praktiska verktyg för att finjustera och övervaka agent-svärmar innan de sätts i drift i kundnära, höginsatsroller.
Citering: Khan, A., Masood, F., Iqbal, A. et al. Evaluating routing stability and coordination in swarm-based multi-agent task-oriented dialogue systems. Sci Rep 16, 11813 (2026). https://doi.org/10.1038/s41598-026-42158-y
Nyckelord: multiagentdialog, konversations-AI, uppgiftsorienterade chattbotar, ruttstabilitet, dialogtillståndsspårning