Clear Sky Science · nl
Evaluatie van routeringsstabiliteit en coördinatie in zwerm-gebaseerde multi-agent taakgerichte dialoguesystemen
Waarom slimmer chatbots ertoe doen
Chatbots worden snel het eerste aanspreekpunt wanneer je een hotel boekt, een vlucht wijzigt of een bedrijf om hulp vraagt. Maar zodra een gesprek tussen taken springt — bijvoorbeeld een restaurant zoeken, een treintijd checken en een rekening betalen — haperen de systemen van vandaag vaak. Dit artikel kijkt onder de motorkap van "zwermachtige" assistenten die uit vele kleine specialist-bots bestaan en worden aangestuurd door een centrale controller, en stelt een eenvoudige maar cruciale vraag: hoe weten we of deze interne samenwerking daadwerkelijk stabiel en betrouwbaar is, en niet alleen vlot aanvoelt aan de oppervlakte?
Veel helpers, één dirigent
In plaats van één gigantisch model dat alles afhandelt, bestuderen de auteurs assistenten opgebouwd uit een verzameling specialistische agenten, elk bedreven in een smal domein zoals hotels, restaurants of taxi’s. Een centrale orkestrator beslist beurt voor beurt welke specialist de volgende actie uitvoert en houdt een gedeeld geheugen bij van wat de gebruiker tot nu toe wil. Deze opzet, soms vergeleken met een zwerm samenwerkende agenten, belooft flexibiliteit en eenvoudiger onderhoud. Tegelijkertijd introduceert het ook nieuwe faalmodi: de controller kan een beurt naar de verkeerde specialist sturen, in cirkels blijven draaien tussen agenten, of het gedeelde geheugen inconsistent houden wanneer de controle wisselt. Deze verborgen misstappen hoeven zich niet in één antwoord te manifesteren, maar kunnen langere gesprekken ontsporen.
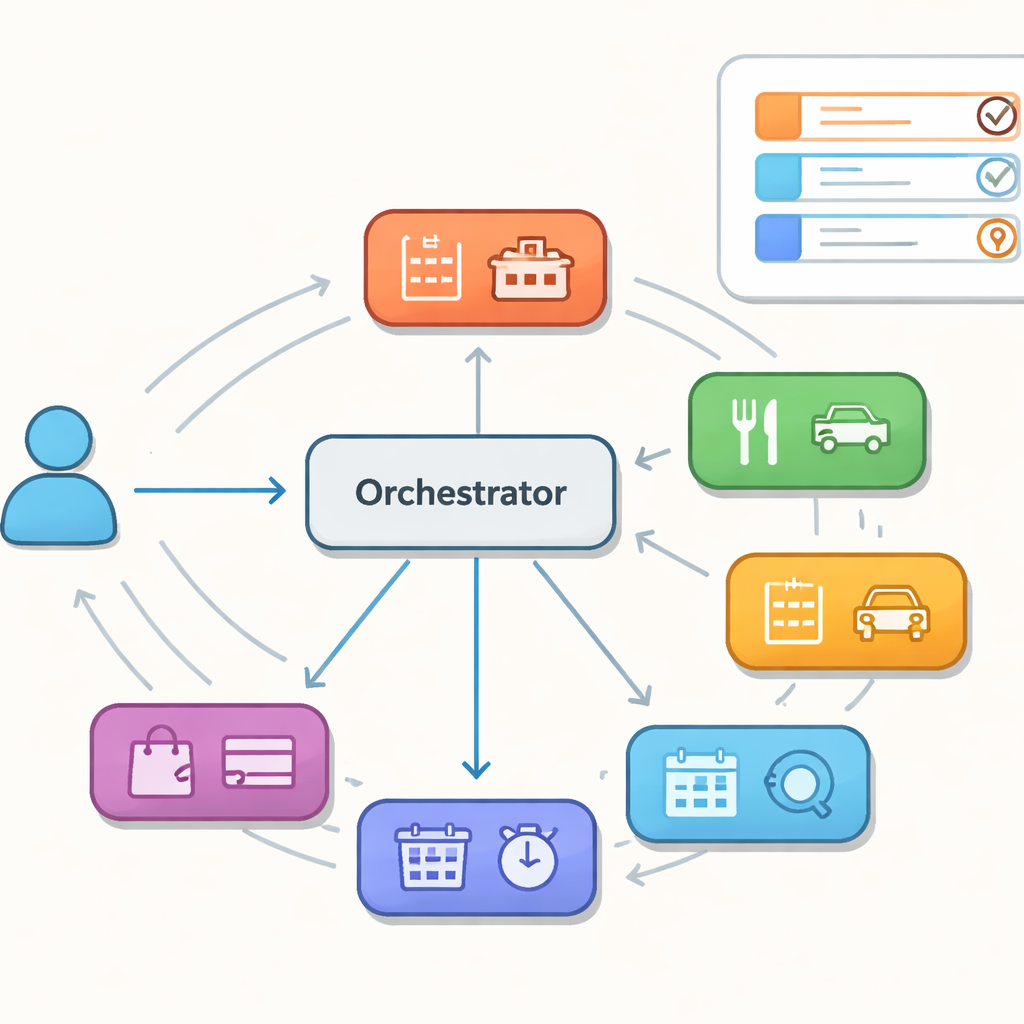
Teamwork meten, niet alleen spraak
Om verder te gaan dan anekdotische demo’s bouwen de auteurs een "evaluation-first" pijplijn bovenop een populair multi-domein dialoogdataset genaamd MultiWOZ 2.2. Ze scheiden doelbewust twee onderdelen: een routeringsmodel dat de specialist kiest, en een taalmodel dat de acties van het systeem genereert en het gedeelde geloof over de doelen van de gebruiker bijwerkt. Door deze te ontkoppelen kunnen ze precies vaststellen of problemen voortkomen uit slechte delegatie of uit gebrekkige taalgeneratie. Vervolgens definiëren ze coördinatiegerichte metriek: of de gekozen specialist overeenkomt met het werkelijke domein voor die beurt, hoeveel voortgang het systeem boekt bij het invullen van vereiste details zoals data en locaties, hoe vaak het tussen agenten schakelt of stuitert, of het in loops terechtkomt, en hoe goed het zich herstelt na vroege fouten.
Het systeem onder druk zetten
Het team blijft niet steken bij statische testgesprekken. Ze introduceren stresstests die realistische wrijving nabootsen: gebruikers die verzoeken herformuleren, eerder gegeven informatie corrigeren na vele beurten, of tools die traag reageren. Deze perturbaties houden de oorspronkelijke taken hetzelfde maar verstoren de context die de router ziet, waardoor de onderzoekers kunnen nagaan hoe robuust de orkestratie is wanneer de werkelijkheid afwijkt van de nette, geannoteerde scripts in de dataset. Ze volgen ook "cascading errors" — situaties waarin een kleine vroege fout in routering of state-tracking de kans drastisch vergroot dat de hele taak later instort en belangrijke beperkingen onvervuld blijven.
Wat routering stabieler maakt
Met een DeBERTa-gebaseerd model als router en een FLAN-T5-model als generator vergelijken de auteurs verschillende routeringsbeleid, waaronder eenvoudige regels en geleerde modellen met en zonder op vertrouwen gebaseerde waarborgen. Een belangrijke bevinding is dat het toevoegen van confidence-aware gating — alleen handelen wanneer de router voldoende zeker is, en anders terugvallen op veiliger gedrag — instabiele overdrachten sterk vermindert. In hun hoofdinstelling stijgt de routeringsaccuratesse naar ongeveer 0,77, terwijl het percentage schakelingen tussen agenten daalt en "bounce"-patronen, waarbij het systeem heen en weer oscilleert, vrijwel verdwijnen. Tegelijk merken ze op dat te conservatief optreden kan leiden tot minder nuttige state-updates, wat een spanningsveld onthult tussen het nemen van precieze beslissingen en het gestaag vorderen richting het doel van de gebruiker.
Waarom deze lessen overdraagbaar zijn
Om te testen hoe algemeen deze inzichten zijn, passen de auteurs dezelfde orkestratiemetriek toe op een andere benchmark, de Schema-Guided Dialogue dataset, die andere domeinen en schema’s bevat. De prestaties dalen overal, maar de fundamentele coördinatieproblemen blijven: misroutering en ontbrekende state-updates zijn nog steeds de hoofdoorzaken, terwijl lussen relatief zeldzaam zijn. Dit suggereert dat de waargenomen patronen geen eigenaardigheid van één dataset zijn, maar diepere uitdagingen weerspiegelen bij het coördineren van veel agenten over lange, veranderlijke gesprekken.
Wat dit betekent voor toekomstige assistenten
Voor niet-specialisten is de les dat het bouwen van betrouwbare multi-skill chatbots evenzeer gaat over het organiseren van hun interne samenwerking als over het trainen van grotere taalmodellen. Het artikel biedt een concreet stappenplan en meetlat voor het vergelijken van orkestratiestrategieën, en toont hoe vroege routeringsbeslissingen, state-tracking en overdrachtsgedrag gezamenlijk bepalen of een gesprek stilletjes afdrijft of succesvol complexe taken voltooit. Door de trade-off tussen nauwkeurigheid en voortgang te benadrukken en aan te tonen hoe kleine vroege fouten kunnen uitgroeien, geeft het werk systeemontwerpers praktische hulpmiddelen om agentenzwermen af te stemmen en te monitoren voordat ze in veeleisende klantgerichte rollen worden ingezet.
Bronvermelding: Khan, A., Masood, F., Iqbal, A. et al. Evaluating routing stability and coordination in swarm-based multi-agent task-oriented dialogue systems. Sci Rep 16, 11813 (2026). https://doi.org/10.1038/s41598-026-42158-y
Trefwoorden: multi-agent dialoog, conversational AI, taakgerichte chatbots, routeringsstabiliteit, dialogstate-tracking