Clear Sky Science · fr
Évaluer la stabilité du routage et la coordination dans les systèmes de dialogue orientés tâches à base d’essaim d’agents
Pourquoi des chatbots plus intelligents sont importants
Les chatbots deviennent rapidement le premier point de contact lorsque vous réservez un hôtel, modifiez un vol ou demandez de l’aide à une entreprise. Mais dès qu’une conversation passe entre plusieurs tâches — par exemple trouver un restaurant, vérifier un horaire de train et payer une facture — les systèmes actuels vacillent souvent. Cet article examine les coulisses d’assistants « en essaim » composés de nombreux petits bots spécialistes dirigés par un contrôleur central, et pose une question simple mais cruciale : comment savoir si ce travail d’équipe interne est réellement stable et fiable, et pas seulement fluide en surface ?
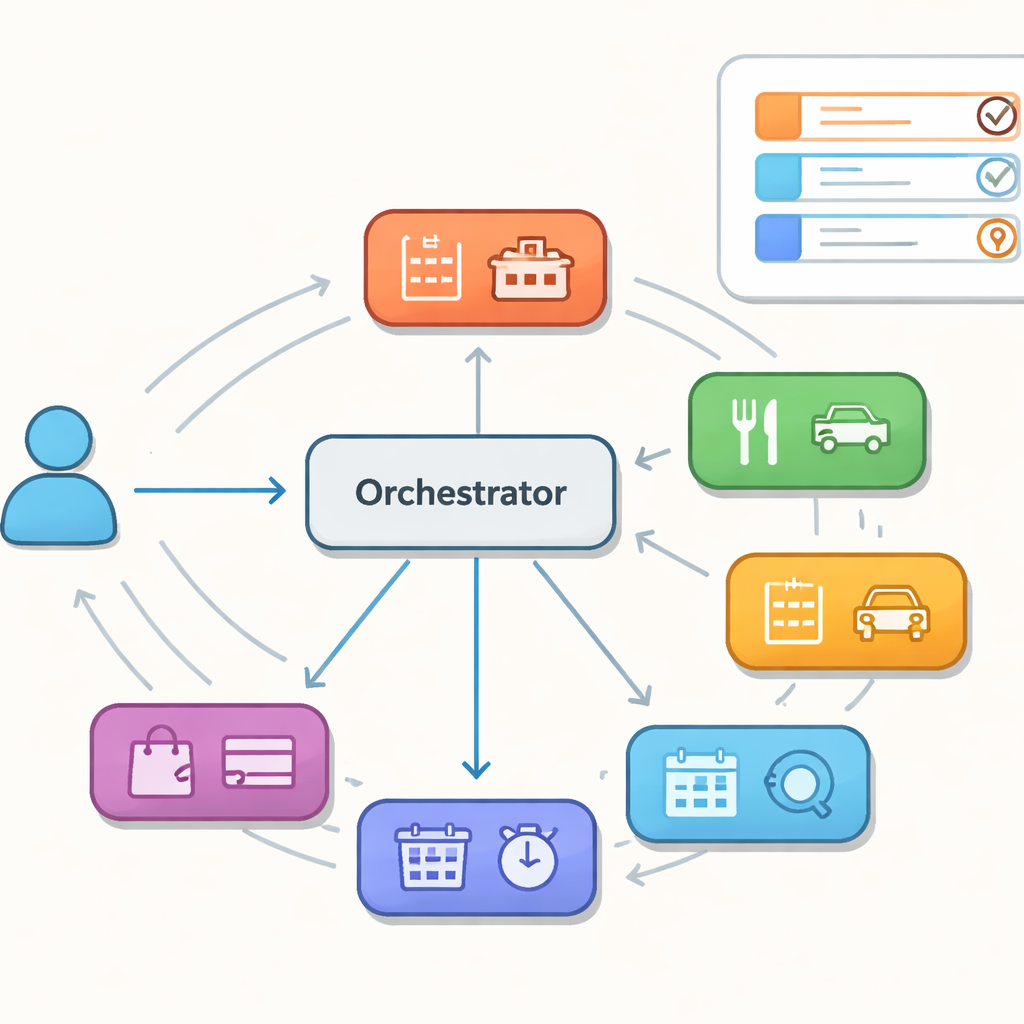
Plusieurs aides, un chef d’orchestre
Plutôt qu’un modèle unique et monolithique, les auteurs étudient des assistants construits à partir d’une collection d’agents spécialistes, chacun compétent dans un domaine restreint comme les hôtels, les restaurants ou les taxis. Un orchestrateur central décide, au fil des tours, quel spécialiste doit agir ensuite et conserve une mémoire partagée des objectifs de l’utilisateur. Cette architecture, parfois comparée à un essaim d’agents coopératifs, promet flexibilité et maintenance facilitée. Elle crée toutefois de nouveaux modes de défaillance : le contrôleur peut adresser un tour au mauvais spécialiste, tourner en rond entre agents ou ne pas maintenir la mémoire partagée cohérente lors des changements de contrôle. Ces erreurs cachées peuvent ne pas apparaître dans une seule réponse, mais elles peuvent compromettre des conversations plus longues.
Mesurer le travail d’équipe, pas seulement le discours
Pour aller au‑delà des démonstrations anecdotiques, les auteurs construisent une chaîne d’évaluation « axée sur l’évaluation » basée sur un jeu de données multi‑domaines populaire appelé MultiWOZ 2.2. Ils séparent délibérément deux éléments : un modèle de routage qui choisit le spécialiste, et un modèle de langage qui génère les actions du système et met à jour la croyance partagée sur les objectifs de l’utilisateur. En découplant ces composants, ils peuvent déterminer si les problèmes proviennent d’une mauvaise délégation ou d’une génération linguistique défaillante. Ils définissent ensuite des métriques centrées sur la coordination : si le spécialiste choisi correspond au domaine réel pour ce tour, combien de progrès le système fait pour remplir les détails requis (dates, lieux...), la fréquence des changements ou rebonds entre agents, la tendance à tomber en boucle, et la capacité à se remettre après des erreurs précoces.
Soumettre le système au stress
L’équipe ne s’arrête pas à des conversations tests statiques. Elle introduit des tests de résistance qui imitent les frictions du monde réel : des utilisateurs reformulant des demandes, corrigeant des informations antérieures après de nombreux tours, ou des outils répondant lentement. Ces perturbations conservent les tâches initiales mais dérangent le contexte vu par le routeur, ce qui permet aux chercheurs de vérifier la robustesse de l’orchestration quand la réalité s’écarte des scripts annotés propres du jeu de données. Ils suivent aussi les « erreurs en cascade » — des situations où une petite défaillance précoce de routage ou de suivi d’état augmente fortement la probabilité que la tâche entière s’effondre plus tard, laissant des contraintes importantes non satisfaites.
Ce qui rend le routage plus stable
En utilisant un modèle basé sur DeBERTa comme routeur et un modèle FLAN‑T5 comme générateur, les auteurs comparent plusieurs politiques de routage, y compris des règles simples et des modèles appris avec ou sans mécanismes de sécurité fondés sur la confiance. Une observation clé est que l’ajout d’un filtrage conscient de la confiance — n’agir que lorsque le routeur est suffisamment sûr, et sinon revenir à un comportement plus prudent — réduit fortement les transferts instables. Dans leur configuration principale, la précision du routage augmente à environ 0,77, tandis que le taux de changement entre agents diminue et que les schémas de « rebond », où le système oscille d’un agent à l’autre, disparaissent presque. En parallèle, ils observent qu’un comportement trop conservateur peut réduire la quantité d’actualisations d’état utiles enregistrées, révélant une tension entre prendre des décisions précises et progresser régulièrement vers l’objectif de l’utilisateur.
Pourquoi ces leçons sont généralisables
Pour tester la généralité de ces enseignements, les auteurs appliquent les mêmes métriques d’orchestration à un autre benchmark, le jeu de données Schema‑Guided Dialogue, qui comporte des domaines et des schémas différents. Les performances déclinent globalement, mais les problèmes de coordination de base persistent : le mauvais routage et les mises à jour d’état manquantes restent les principaux coupables, tandis que les boucles sont relativement rares. Cela suggère que les motifs observés ne sont pas des singularités d’un unique jeu de données mais reflètent des défis plus profonds pour coordonner de nombreux agents sur des conversations longues et changeantes.
Ce que cela signifie pour les assistants de demain
Pour les non‑spécialistes, la conclusion est que construire des chatbots multi‑compétences fiables tient autant à organiser leur travail d’équipe interne qu’à entraîner des modèles de langage plus grands. L’article propose un plan concret et un étalon pour comparer les stratégies d’orchestration, montrant comment les décisions de routage précoces, le suivi d’état et le comportement de transfert façonnent ensemble si une conversation dévie discrètement de sa trajectoire ou réussit à accomplir des tâches complexes. En mettant en évidence le compromis entre précision et progression et en exposant comment de petites erreurs initiales peuvent s’amplifier, le travail fournit aux concepteurs d’applications des outils pratiques pour ajuster et surveiller des essaims d’agents avant de les déployer dans des contextes clients à enjeux élevés.
Citation: Khan, A., Masood, F., Iqbal, A. et al. Evaluating routing stability and coordination in swarm-based multi-agent task-oriented dialogue systems. Sci Rep 16, 11813 (2026). https://doi.org/10.1038/s41598-026-42158-y
Mots-clés: dialogue multi-agent, IA conversationnelle, chatbots orientés tâches, stabilité du routage, suivi de l’état du dialogue