Clear Sky Science · es
Evaluación de la estabilidad de enrutamiento y la coordinación en sistemas de diálogo orientados a tareas basados en enjambres de agentes
Por qué importan los chatbots más inteligentes
Los chatbots se están convirtiendo rápidamente en el primer punto de contacto cuando reservas un hotel, cambias un vuelo o pides ayuda a una empresa. Pero en cuanto una conversación salta entre tareas —por ejemplo, buscar un restaurante, consultar el horario de un tren y pagar una factura— los sistemas actuales a menudo se tambalean. Este artículo examina el interior de asistentes “en forma de enjambre” compuestos por muchos pequeños bots especialistas guiados por un controlador central, y plantea una pregunta simple pero crucial: ¿cómo sabemos si este trabajo en equipo interno es realmente estable y fiable, y no solo fluido en apariencia?
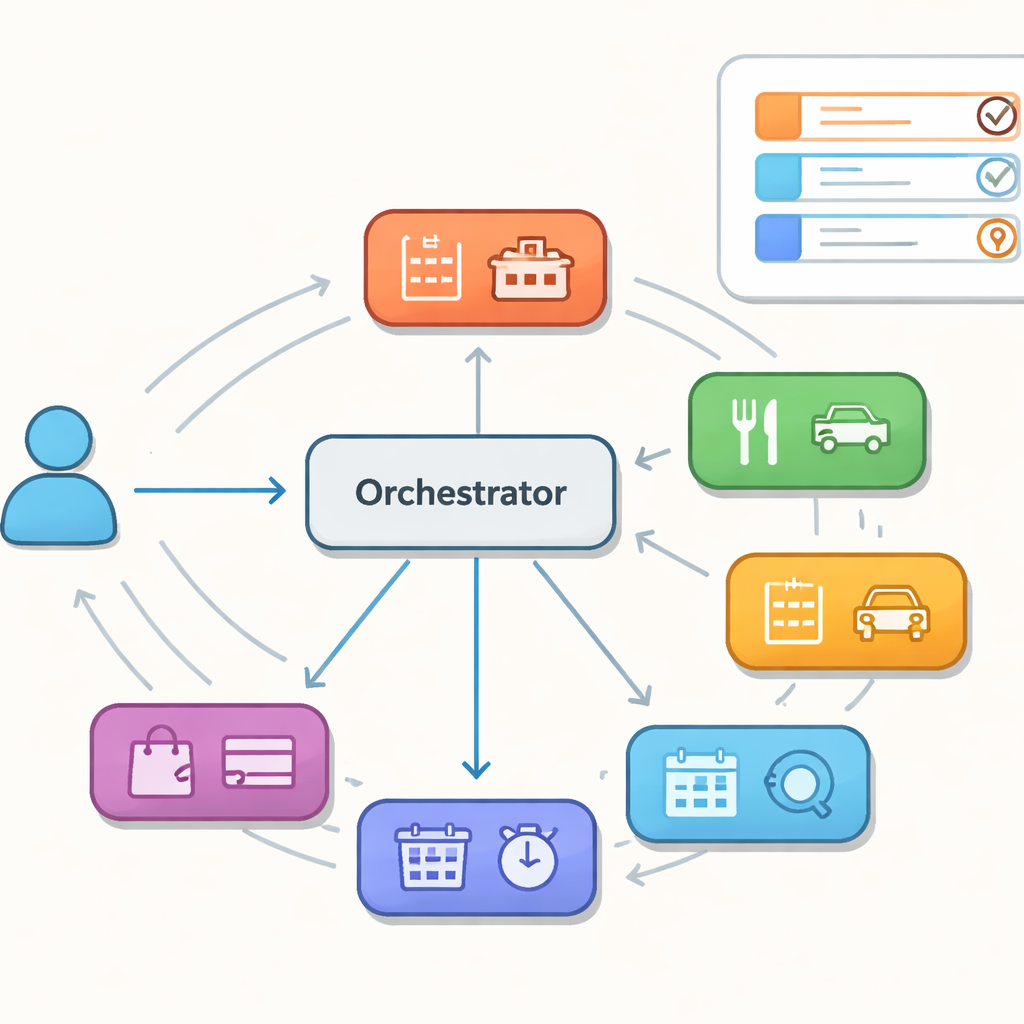
Muchos ayudantes, un director
En lugar de un único modelo gigantesco que lo gestione todo, los autores estudian asistentes construidos a partir de una colección de agentes especialistas, cada uno competente en un dominio estrecho como hoteles, restaurantes o taxis. Un orquestador central decide, turno a turno, qué especialista debe actuar a continuación y mantiene una memoria compartida de lo que el usuario quiere hasta ese momento. Esta configuración, a veces comparada con un enjambre de agentes cooperantes, promete flexibilidad y mantenimiento más sencillo. Sin embargo, también crea nuevos modos de fallo: el controlador puede enviar un turno al especialista equivocado, girar en círculos entre agentes o no mantener la memoria compartida consistente cuando cambia el control. Estos tropiezos ocultos pueden no notarse en una sola respuesta, pero pueden descarrilar conversaciones más largas.
Medir el trabajo en equipo, no solo la conversación
Para ir más allá de demostraciones anecdóticas, los autores construyen una canalización «orientada a la evaluación» sobre un popular conjunto de datos multi-dominio llamado MultiWOZ 2.2. Deliberadamente separan dos piezas: un modelo de enrutamiento que elige al especialista, y un modelo de lenguaje que genera las acciones del sistema y actualiza la creencia compartida sobre los objetivos del usuario. Al desacoplarlos, pueden identificar si los problemas provienen de una mala delegación o de una generación de lenguaje deficiente. Luego definen métricas centradas en la coordinación: si el especialista elegido coincide con el dominio real de ese turno, cuánto progreso hace el sistema rellenando detalles requeridos como fechas y ubicaciones, con qué frecuencia cambia o rebota entre agentes, si cae en bucles y qué tan bien se recupera tras errores tempranos.
Poniendo el sistema bajo estrés
El equipo no se conforma con conversaciones estáticas de prueba. Introducen pruebas de estrés que imitan la fricción del mundo real: usuarios que reformulan peticiones, corrigen información anterior tras muchos turnos o herramientas que responden con lentitud. Estas perturbaciones mantienen las tareas originales pero alteran el contexto que ve el enrutador, lo que permite a los investigadores comprobar cuán robusta es la orquestación cuando la realidad se desvía de los guiones anotados y ordenados del conjunto de datos. También rastrean “errores en cascada”: situaciones en las que un pequeño desliz temprano en el enrutamiento o el seguimiento del estado aumenta dramáticamente la probabilidad de que toda la tarea colapse más adelante, dejando restricciones importantes sin cumplir.
Qué hace que el enrutamiento sea más estable
Usando un modelo basado en DeBERTa como enrutador y un modelo FLAN-T5 como generador, los autores comparan varias políticas de enrutamiento, incluidas reglas simples y modelos aprendidos con y sin salvaguardas basadas en la confianza. Un hallazgo clave es que añadir un filtrado consciente de la confianza —actuar solo cuando el enrutador está suficientemente seguro y, en caso contrario, recurrir a un comportamiento más seguro— reduce drásticamente las transferencias inestables. En su configuración principal, la precisión del enrutamiento asciende a alrededor de 0,77, mientras que la tasa de cambios entre agentes disminuye y los patrones de “rebote”, en los que el sistema oscila de un lado a otro, casi desaparecen. Al mismo tiempo, observan que ser demasiado conservador puede reducir la cantidad de actualizaciones útiles del estado registradas, lo que revela una tensión entre tomar decisiones precisas y avanzar de forma sostenida hacia el objetivo del usuario.
Por qué estas lecciones se aplican más allá
Para comprobar cuán generales son estos hallazgos, los autores aplican las mismas métricas de orquestación a otro punto de referencia, el conjunto de datos Schema-Guided Dialogue, que tiene dominios y esquemas distintos. El rendimiento cae en general, pero los problemas básicos de coordinación persisten: el enrutamiento incorrecto y las actualizaciones de estado faltantes siguen siendo los principales culpables, mientras que los bucles son relativamente raros. Esto sugiere que los patrones observados no son peculiaridades de un único conjunto de datos, sino que reflejan desafíos más profundos en la coordinación de muchos agentes a lo largo de conversaciones largas y cambiantes.
Qué significa esto para los asistentes del futuro
Para el público no especializado, la conclusión es que construir chatbots multi-habilidad de confianza depende tanto de organizar su trabajo en equipo interno como de entrenar modelos de lenguaje más grandes. El artículo ofrece un plan y un criterio concretos para comparar estrategias de orquestación, mostrando cómo las decisiones tempranas de enrutamiento, el seguimiento del estado y el comportamiento de las transferencias configuran conjuntamente si una conversación deriva silenciosamente o completa con éxito tareas complejas. Al destacar el intercambio entre precisión y progreso y al exponer cómo pequeños errores tempranos pueden convertirse en una bola de nieve, el trabajo proporciona a los diseñadores de sistemas herramientas prácticas para ajustar y monitorizar enjambres de agentes antes de desplegarlos en funciones de atención al cliente de alto riesgo.
Cita: Khan, A., Masood, F., Iqbal, A. et al. Evaluating routing stability and coordination in swarm-based multi-agent task-oriented dialogue systems. Sci Rep 16, 11813 (2026). https://doi.org/10.1038/s41598-026-42158-y
Palabras clave: diálogo multiagente, IA conversacional, chatbots orientados a tareas, estabilidad de enrutamiento, seguimiento del estado del diálogo