Clear Sky Science · en
Evaluating routing stability and coordination in swarm-based multi-agent task-oriented dialogue systems
Why smarter chatbots matter
Chatbots are quickly becoming the first point of contact when you book a hotel, change a flight, or ask a company for help. But as soon as a conversation jumps between tasks — say, finding a restaurant, checking a train time, and paying a bill — today’s systems often wobble. This paper looks under the hood of “swarm-like” assistants made of many small specialist bots guided by a central controller, and asks a simple but crucial question: how do we know if this internal teamwork is actually stable and reliable, not just fluent on the surface?
Many helpers, one conductor
Instead of one giant model handling everything, the authors study assistants built from a collection of specialist agents, each good at a narrow domain such as hotels, restaurants, or taxis. A central orchestrator decides, turn by turn, which specialist should act next and keeps a shared memory of what the user wants so far. This setup, sometimes likened to a swarm of cooperating agents, promises flexibility and easier maintenance. However, it also creates new failure modes: the controller might send a turn to the wrong specialist, spin in circles between agents, or fail to keep the shared memory consistent when control switches. These hidden missteps may not show up in a single reply, but they can derail longer conversations.
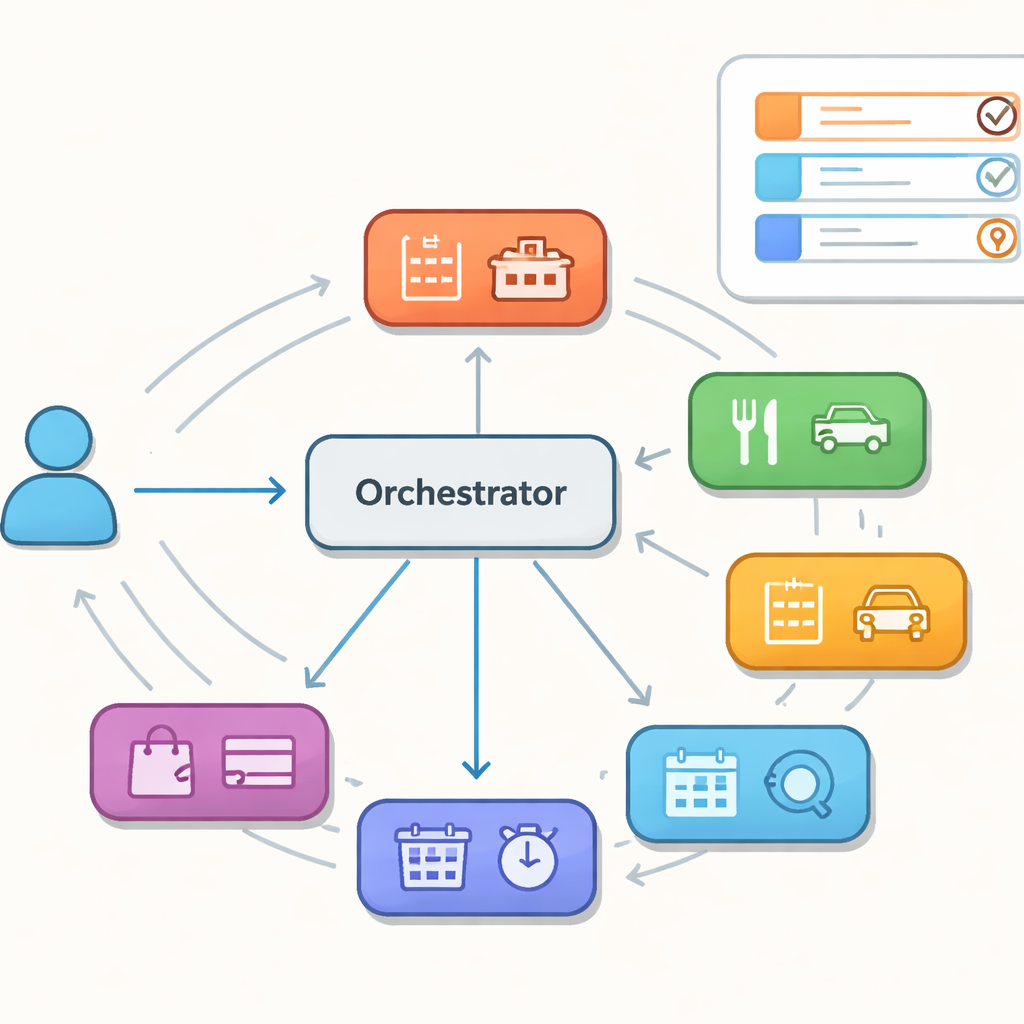
Measuring teamwork, not just talk
To move beyond anecdotal demos, the authors build an “evaluation-first” pipeline on top of a popular multi-domain dialogue dataset called MultiWOZ 2.2. They deliberately separate two pieces: a routing model that chooses the specialist, and a language model that generates the system’s actions and updates the shared belief about the user’s goals. By decoupling these, they can pinpoint whether problems arise from bad delegation or from poor language generation. They then define coordination-focused metrics: whether the chosen specialist matches the true domain for that turn, how much progress the system makes filling in required details like dates and locations, how often it switches or bounces between agents, whether it falls into loops, and how well it recovers after early mistakes.
Putting the system under stress
The team does not stop at static test conversations. They introduce stress tests that mimic real-world friction: users rephrasing requests, correcting earlier information after many turns, or tools responding slowly. These perturbations keep the original tasks the same but disturb the context the router sees, allowing the researchers to check how robust the orchestration is when reality deviates from the neat, annotated scripts in the dataset. They also track “cascading errors” — situations where a small early slip in routing or state tracking dramatically increases the chance that the entire task later collapses, leaving important constraints unmet.
What makes routing more stable
Using a DeBERTa-based model as the router and a FLAN-T5 model as the generator, the authors compare several routing policies, including simple rules and learned models with and without confidence-based safeguards. A key finding is that adding confidence-aware gating — only acting when the router is sufficiently sure, and otherwise falling back to safer behavior — sharply reduces unstable handoffs. In their main setting, routing accuracy rises to about 0.77, while the rate of switching between agents drops and “bounce” patterns, where the system oscillates back and forth, nearly vanish. At the same time, they observe that being too conservative can reduce the amount of useful state updates recorded, revealing a tension between making precise decisions and steadily advancing toward the user’s goal.
Why these lessons carry over
To test how general these insights are, the authors apply the same orchestration metrics to another benchmark, the Schema-Guided Dialogue dataset, which has different domains and schemas. Performance drops overall, but the basic coordination problems remain: misrouting and missing state updates are still the main culprits, while looping is relatively rare. This suggests that the observed patterns are not quirks of a single dataset but reflect deeper challenges in coordinating many agents over long, shifting conversations.
What this means for future assistants
For non-specialists, the takeaway is that building trustworthy multi-skill chatbots is as much about organizing their internal teamwork as it is about training bigger language models. The paper offers a concrete blueprint and yardstick for comparing orchestration strategies, showing how early routing decisions, state tracking, and handoff behavior jointly shape whether a conversation quietly drifts off course or successfully completes complex tasks. By highlighting the trade-off between accuracy and progress and by exposing how small early errors can snowball, the work gives system designers practical tools to tune and monitor agent swarms before deploying them in high-stakes customer-facing roles.
Citation: Khan, A., Masood, F., Iqbal, A. et al. Evaluating routing stability and coordination in swarm-based multi-agent task-oriented dialogue systems. Sci Rep 16, 11813 (2026). https://doi.org/10.1038/s41598-026-42158-y
Keywords: multi-agent dialogue, conversational AI, task-oriented chatbots, routing stability, dialogue state tracking