Clear Sky Science · ja
群れ型マルチエージェントのタスク指向対話システムにおけるルーティングの安定性と協調性の評価
なぜより賢いチャットボットが重要なのか
ホテルの予約や航空便の変更、企業への問い合わせなどで、チャットボットが最初の接点になることが増えています。しかし、会話が複数のタスクにまたがる——例えば、レストラン探し、列車の時刻確認、支払いといった具合に——と、現在のシステムはしばしば不安定になります。本論文は、多数の小さな専門エージェントと中央のコントローラで構成される「群れのような」アシスタントの内部を調べ、表面的な流暢さだけでなく、この内部のチームワークが本当に安定で信頼できるかどうかという、単純だが重要な問いを投げかけます。
多くのヘルパー、ひとつの指揮者
すべてを処理する巨大モデルの代わりに、著者らは、ホテル、レストラン、タクシーなど狭いドメインに特化した複数の専門エージェントから構成されるアシスタントを研究します。中央のオーケストレータがターンごとにどの専門家が次に動くべきかを決め、これまでのユーザーの意図を共有メモリに保持します。この構成は、協調するエージェントの群れに例えられ、柔軟性や保守のしやすさをもたらす一方で、新たな故障モードも生み出します。コントローラが誤った専門家へターンを送る、エージェント間で堂々巡りする、制御が切り替わる際に共有メモリが一貫性を失う、といった問題です。これらの隠れた誤りは単一の応答では現れないことが多いものの、長期の会話を大きく乱す可能性があります。
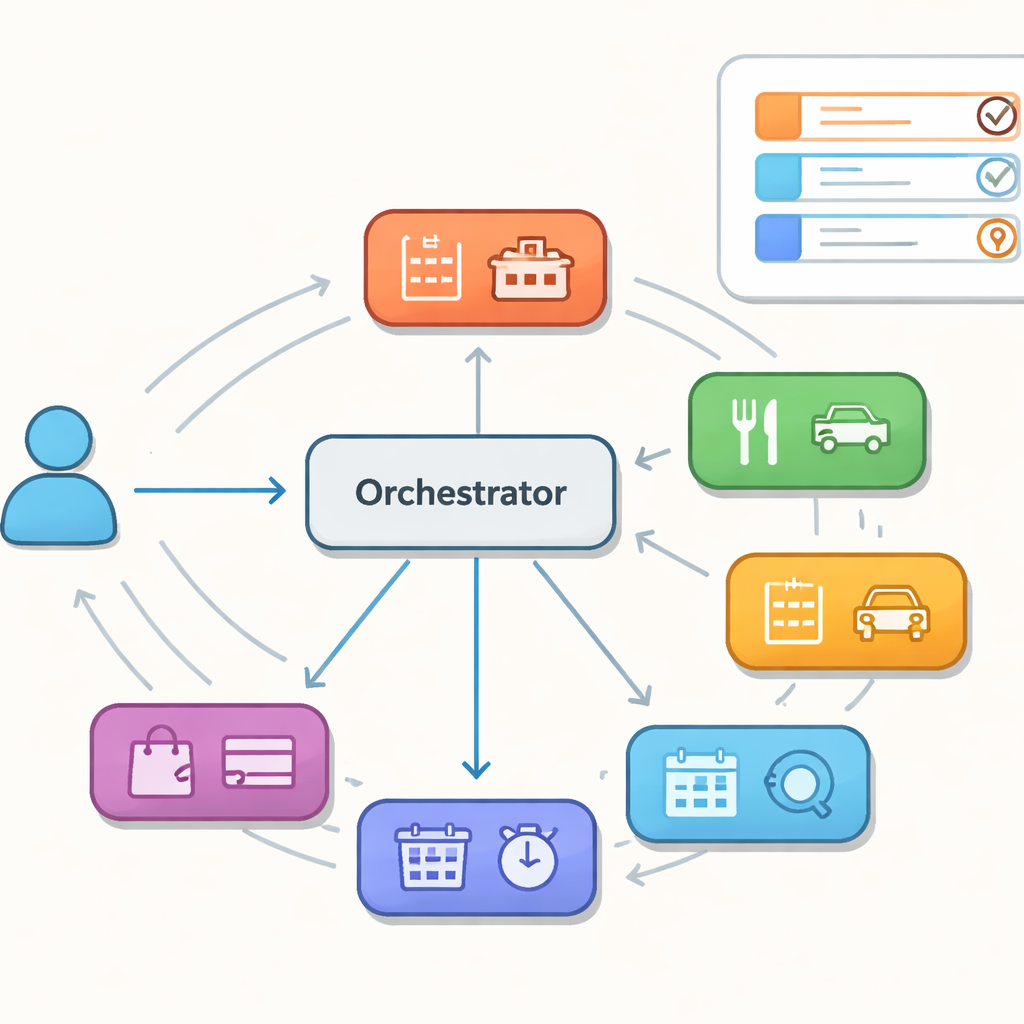
会話の量だけでなくチームワークを測る
逸話的なデモにとどまらないために、著者らは人気のあるマルチドメイン対話データセットであるMultiWOZ 2.2の上に「評価優先」のパイプラインを構築します。ルーティング(どの専門家を選ぶか)と、システムの行動を生成しユーザーの目標に関する共有信念を更新する言語モデルを意図的に分離することで、問題が誤った割り当てから生じるのか、言語生成の不備から生じるのかを特定できます。さらに、協調に焦点を当てた評価指標を定義します:選ばれた専門家がそのターンの真のドメインと一致するか、日付や場所など必要な詳細がどれだけ埋まるか、エージェント間の切り替えや跳ね返り(bounce)がどれくらい発生するか、ループに陥る頻度、初期のミスからの回復度合いなどです。
システムに負荷をかける
著者らは静的なテスト会話だけにとどまりません。ユーザーが言い換える、長いターンの後に情報を訂正する、ツールの応答が遅れるといった現実的な摩擦を模したストレステストを導入します。これらの摂動は元のタスク自体は変えずにルータが見る文脈を乱すため、データセットの整った注釈付きスクリプトから現実が逸脱したときにオーケストレーションがどれほど堅牢かを検証できます。また「連鎖的誤り」も追跡します——ルーティングや状態追跡の初期の小さな不手際が、後にタスク全体の崩壊につながり重要な制約が満たされなくなる状況です。
何がルーティングを安定させるか
ルータとしてDeBERTaベースのモデル、ジェネレータとしてFLAN-T5を用い、単純なルールから学習モデル(信頼度に基づく安全策あり/なし)まで複数のルーティング方針を比較します。重要な知見は、信頼度を意識したゲーティング(ルータが十分に確信している場合にのみ行動し、そうでなければより安全な振る舞いにフォールバックする)を導入すると、不安定な引き継ぎが大幅に減ることです。主要な設定ではルーティング精度が約0.77に上がり、エージェント間の切り替え率が下がり、システムが往復する「バウンス」パターンはほとんど消えます。一方で、過度に保守的になると記録される有用な状態更新が減り得るため、精度を高めることと着実にユーザーの目標に近づくことの間にトレードオフが存在することも明らかになりました。
なぜこれらの教訓は他でも通用するのか
これらの洞察の一般性を検証するために、著者らは同じオーケストレーション指標を別のベンチマークであるSchema-Guided Dialogueデータセットにも適用します。ドメインやスキーマが異なるため全体的な性能は低下しますが、基本的な協調問題は残ります:誤ったルーティングや状態更新の欠落が主要な原因であり、ループは比較的稀です。これは、観察されたパターンが単一のデータセットの特殊性ではなく、長く変動する会話における多数のエージェントの協調というより深い課題を反映していることを示唆します。
将来のアシスタントにとっての意味
非専門家向けの要点は、信頼できるマルチスキルなチャットボットを構築するには、より大きな言語モデルを訓練することと同じくらい内部のチームワークの組織化が重要だということです。本論文はオーケストレーション戦略を比較するための具体的な設計図と物差しを提示しており、初期のルーティング判断、状態追跡、ハンドオフの挙動がどのように組み合わさって会話が静かに逸脱するか、あるいは複雑なタスクを成功裏に完了するかを示します。精度と進展のトレードオフを浮き彫りにし、初期の小さな誤りがどのように雪だるま式に拡大するかを明らかにすることで、実運用の顧客対応システムに展開する前にエージェント群を調整・監視するための実践的なツールをシステム設計者に提供します。
引用: Khan, A., Masood, F., Iqbal, A. et al. Evaluating routing stability and coordination in swarm-based multi-agent task-oriented dialogue systems. Sci Rep 16, 11813 (2026). https://doi.org/10.1038/s41598-026-42158-y
キーワード: マルチエージェント対話, 会話型AI, タスク指向チャットボット, ルーティングの安定性, 対話状態追跡