Clear Sky Science · de
Bewertung der Routing-Stabilität und Koordination in schwarmbasierten Multi-Agenten-Aufgaben-Dialogsystemen
Warum intelligentere Chatbots wichtig sind
Chatbots werden immer häufiger zur ersten Anlaufstelle, wenn Sie ein Hotel buchen, einen Flug umbuchen oder sich an ein Unternehmen wenden. Sobald ein Gespräch jedoch zwischen Aufgaben hin- und herspringt – zum Beispiel ein Restaurant finden, eine Zugverbindung prüfen und eine Rechnung bezahlen – geraten heutige Systeme oft ins Wanken. Dieses Paper blickt unter die Haube von „schwarmähnlichen“ Assistenten, die aus vielen kleinen Spezialisten bestehen und von einem zentralen Steuerer geleitet werden, und stellt eine einfache, aber entscheidende Frage: Woran erkennen wir, ob dieses interne Zusammenspiel wirklich stabil und zuverlässig ist und nicht nur oberflächlich flüssig wirkt?
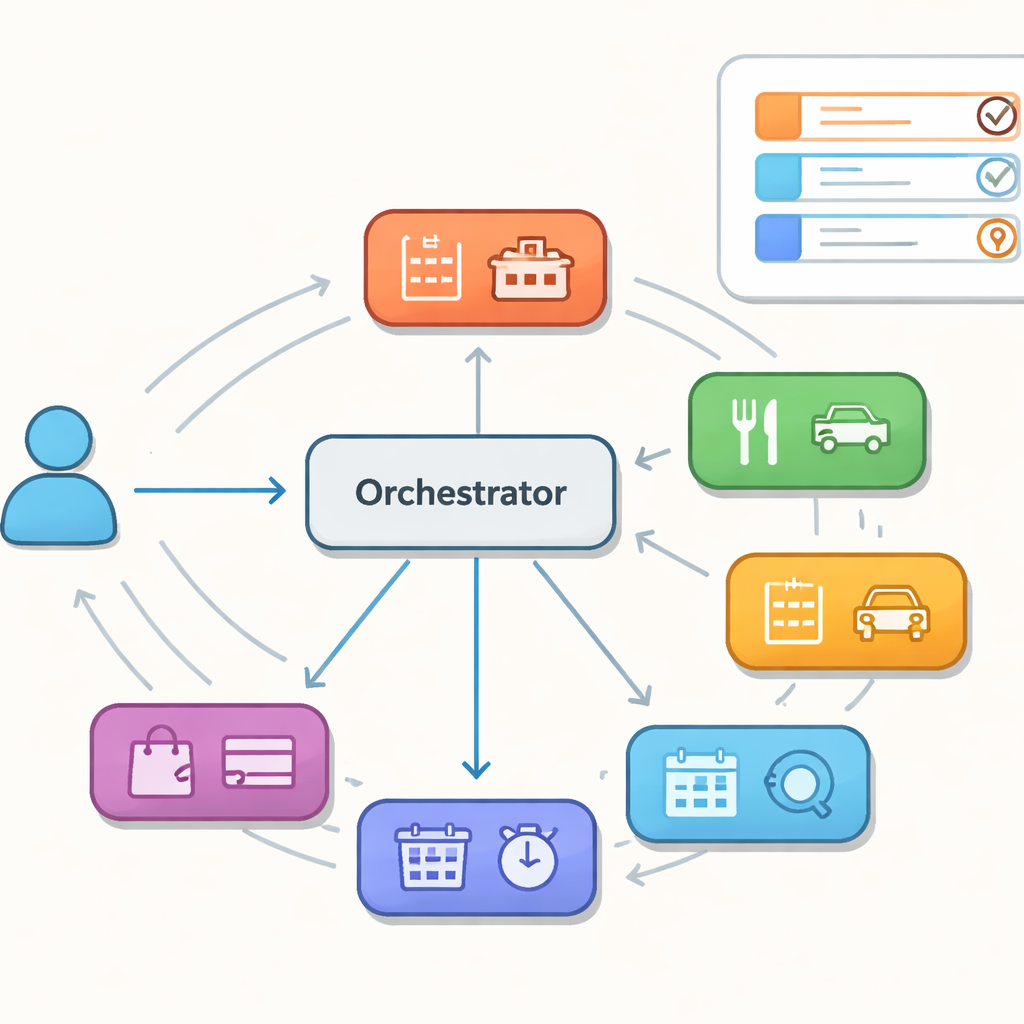
Viele Helfer, ein Dirigent
Statt eines einzigen großen Modells, das alles abwickelt, untersuchen die Autor:innen Assistenten, die aus einer Sammlung spezialisierter Agenten bestehen, von denen jeder in einem engen Bereich wie Hotels, Restaurants oder Taxis besonders versiert ist. Ein zentraler Orchestrator entscheidet Zug um Zug, welcher Spezialist als nächstes handeln soll, und führt einen gemeinsamen Speicher über die bisherigen Nutzerziele. Dieses Setup, das manchmal mit einem kooperierenden Schwarm verglichen wird, verspricht Flexibilität und einfachere Wartung. Gleichzeitig entstehen jedoch neue Fehlerquellen: Der Controller könnte einen Zug an den falschen Spezialisten schicken, zwischen Agenten im Kreis laufen oder es versäumen, den gemeinsamen Speicher beim Wechsel der Kontrolle konsistent zu halten. Solche versteckten Fehltritte zeigen sich vielleicht nicht in einer einzelnen Antwort, können aber längere Gespräche entgleisen lassen.
Teamwork messen, nicht nur Gespräch
Um über anekdotische Demos hinauszukommen, bauen die Autor:innen eine „Evaluation-first“-Pipeline auf Basis eines populären Multi-Domain-Dialogdatensatzes namens MultiWOZ 2.2. Sie trennen dabei bewusst zwei Komponenten: ein Routing-Modell, das den Spezialisten auswählt, und ein Sprachmodell, das die Systemaktionen generiert und den gemeinsamen Glaubenszustand über die Ziele des Nutzers aktualisiert. Durch diese Entkopplung können sie genau feststellen, ob Probleme durch schlechte Delegation oder durch mangelhafte Sprachgenerierung entstehen. Anschließend definieren sie koordinationsfokussierte Metriken: ob der gewählte Spezialist der tatsächlichen Domäne dieses Zugs entspricht, wie viel Fortschritt das System beim Ausfüllen erforderlicher Details wie Daten und Orte macht, wie oft es zwischen Agenten wechselt oder hin- und herspringt, ob es in Schleifen gerät und wie gut es sich nach frühen Fehlern erholt.
Das System unter Stress setzen
Das Team begnügt sich nicht mit statischen Testgesprächen. Sie führen Stresstests ein, die reale Reibung nachbilden: Nutzer formulieren Anfragen um, korrigieren frühere Angaben nach vielen Zügen oder Tools reagieren langsam. Diese Störungen lassen die ursprünglichen Aufgaben unverändert, stören jedoch den Kontext, den der Router sieht, sodass die Forschenden prüfen können, wie robust die Orchestrierung ist, wenn die Realität von den sauberen, annotierten Skripten im Datensatz abweicht. Außerdem verfolgen sie „kaskadierende Fehler“ — Situationen, in denen ein kleiner früher Ausrutscher beim Routing oder bei der Zustandsverfolgung die Wahrscheinlichkeit dramatisch erhöht, dass die gesamte Aufgabe später zusammenbricht und wichtige Vorgaben nicht erfüllt werden.
Was Routing stabiler macht
Mit einem DeBERTa-basierten Modell als Router und einem FLAN-T5-Modell als Generator vergleichen die Autor:innen mehrere Routing-Strategien, darunter einfache Regeln und gelernte Modelle mit und ohne vertrauensbasierte Sicherungen. Ein zentrales Ergebnis ist, dass das Hinzufügen eines vertrauensbewussten Gateings — also nur zu handeln, wenn der Router ausreichend sicher ist, und andernfalls auf sichereres Verhalten zurückzufallen — instabile Übergaben deutlich reduziert. In ihrem Hauptsetting steigt die Routing-Genauigkeit auf etwa 0,77, während die Wechselrate zwischen Agenten sinkt und „Bounce“-Muster, bei denen das System hin und her oszilliert, nahezu verschwinden. Gleichzeitig beobachten sie, dass zu konservatives Verhalten die Anzahl nützlicher Zustandsaktualisierungen verringern kann, was eine Spannung zwischen präzisen Entscheidungen und dem stetigen Fortschritt hin zum Nutzerziel offenbart.
Warum diese Erkenntnisse übertragbar sind
Um zu prüfen, wie allgemein diese Einsichten sind, wenden die Autor:innen dieselben Orchestrierungsmetriken auf einen anderen Benchmark an, den Schema-Guided Dialogue-Datensatz, der andere Domänen und Schemata enthält. Die Leistung fällt insgesamt ab, doch die grundlegenden Koordinationsprobleme bleiben bestehen: Fehlrouten und fehlende Zustandsaktualisierungen sind weiterhin die Hauptschuldigen, während Schleifen relativ selten sind. Das deutet darauf hin, dass die beobachteten Muster keine Eigenheiten eines einzelnen Datensatzes sind, sondern tiefere Herausforderungen bei der Koordination vieler Agenten über lange, sich verändernde Gespräche widerspiegeln.
Was das für zukünftige Assistenten bedeutet
Für Nicht-Spezialist:innen ist die Quintessenz: Vertrauenswürdige Multi-Skill-Chatbots zu bauen, dreht sich ebenso sehr um die Organisation ihrer internen Teamarbeit wie um das Training größerer Sprachmodelle. Das Paper liefert eine konkrete Blaupause und ein Messinstrument, um Orchestrierungsstrategien zu vergleichen, und zeigt, wie frühe Routing-Entscheidungen, Zustandsverfolgung und Übergabeverhalten gemeinsam bestimmen, ob ein Gespräch stillschweigend vom Kurs abkommt oder komplexe Aufgaben erfolgreich abschließt. Indem es den Zielkonflikt zwischen Genauigkeit und Fortschritt aufzeigt und darlegt, wie kleine frühe Fehler sich aufsummieren können, gibt die Arbeit Systemdesignern praktische Werkzeuge, um Agentenschwärme zu justieren und zu überwachen, bevor sie in kritischen Kundenanwendungen eingesetzt werden.
Zitation: Khan, A., Masood, F., Iqbal, A. et al. Evaluating routing stability and coordination in swarm-based multi-agent task-oriented dialogue systems. Sci Rep 16, 11813 (2026). https://doi.org/10.1038/s41598-026-42158-y
Schlüsselwörter: Multi-Agenten-Dialog, konversationelle KI, aufgabenorientierte Chatbots, Routing-Stabilität, Dialogzustandsverfolgung