Clear Sky Science · pt
Avaliação da estabilidade de roteamento e coordenação em sistemas de diálogo orientados a tarefas baseados em enxames de múltiplos agentes
Por que chatbots mais inteligentes importam
Chatbots estão rapidamente se tornando o primeiro ponto de contato quando você reserva um hotel, altera um voo ou solicita ajuda a uma empresa. Mas assim que uma conversa pula entre tarefas — por exemplo, encontrar um restaurante, checar o horário de um trem e pagar uma conta — os sistemas atuais frequentemente vacilam. Este artigo examina o funcionamento interno de assistentes “semelhantes a enxames” compostos por muitos pequenos bots especialistas guiados por um controlador central e faz uma pergunta simples, porém crucial: como saber se esse trabalho em equipe interno é realmente estável e confiável, e não apenas fluente superficialmente?
Muitos ajudantes, um maestro
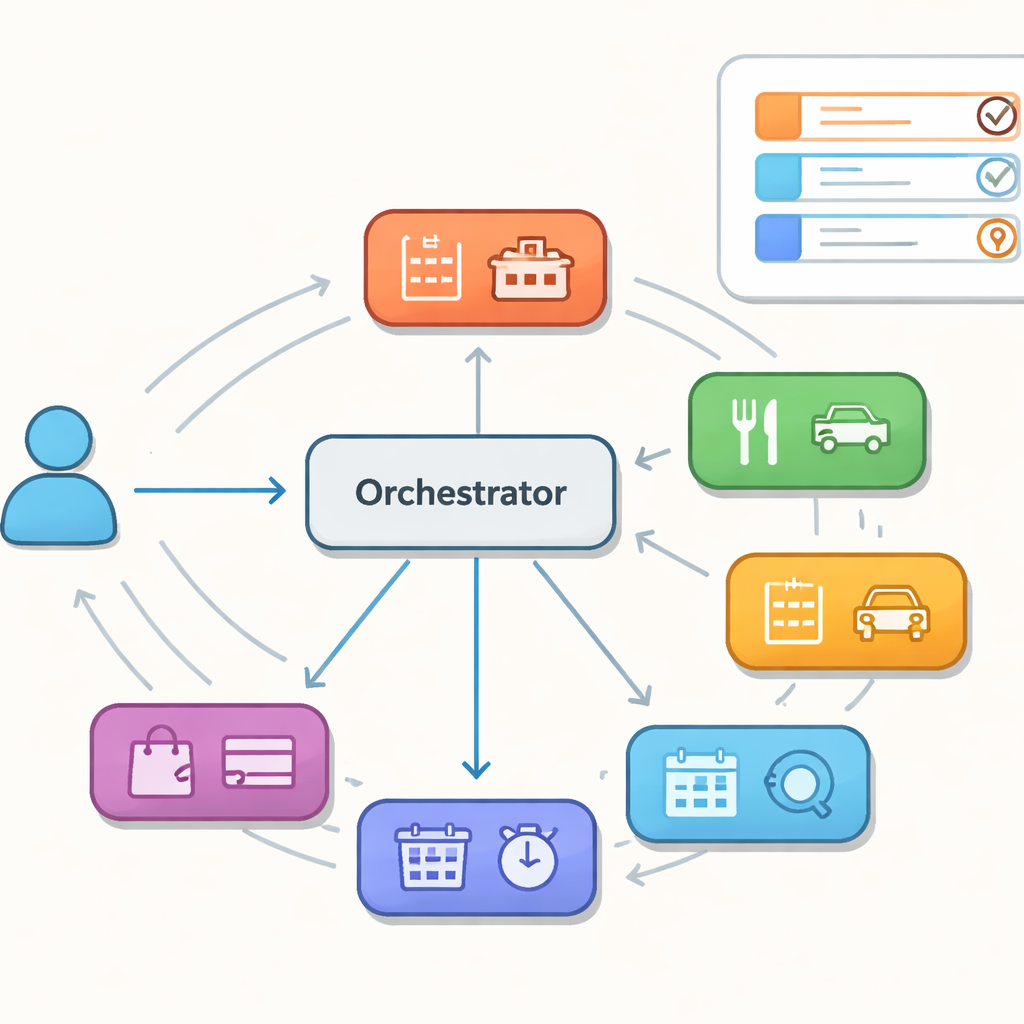
Em vez de um modelo gigante lidando com tudo, os autores estudam assistentes construídos a partir de uma coleção de agentes especialistas, cada um bom em um domínio estreito como hotéis, restaurantes ou táxis. Um orquestrador central decide, turno a turno, qual especialista deve agir a seguir e mantém uma memória compartilhada do que o usuário quer até então. Essa configuração, às vezes comparada a um enxame de agentes cooperantes, promete flexibilidade e manutenção mais fácil. Contudo, também cria novos modos de falha: o controlador pode encaminhar um turno ao especialista errado, girar em círculos entre agentes ou falhar em manter a memória compartilhada consistente quando o controle muda. Esses deslizes ocultos podem não aparecer em uma única resposta, mas podem comprometer conversas mais longas.
Medindo trabalho em equipe, não apenas fala
Para ir além de demonstrações anedóticas, os autores constroem um pipeline “orientado à avaliação” sobre um conjunto de dados de diálogo multdomínio popular chamado MultiWOZ 2.2. Eles separam deliberadamente duas peças: um modelo de roteamento que escolhe o especialista, e um modelo de linguagem que gera as ações do sistema e atualiza a crença compartilhada sobre os objetivos do usuário. Ao desacoplar esses componentes, eles podem apontar se os problemas surgem de delegação ruim ou de geração de linguagem deficiente. Em seguida, definem métricas focadas em coordenação: se o especialista escolhido corresponde ao domínio verdadeiro daquele turno, quanto progresso o sistema faz preenchendo detalhes necessários como datas e locais, com que frequência ele alterna ou “salta” entre agentes, se cai em ciclos, e quão bem se recupera após erros iniciais.
Colocando o sistema sob estresse
A equipe não se limita a conversas de teste estáticas. Eles introduzem testes de estresse que mimetizam atritos do mundo real: usuários reformulando pedidos, corrigindo informações anteriores após muitos turnos, ou ferramentas respondendo com lentidão. Essas perturbações mantêm as tarefas originais as mesmas, mas perturbam o contexto que o roteador vê, permitindo aos pesquisadores verificar quão robusta é a orquestração quando a realidade se desvia dos roteiros anotados e ordenados do conjunto de dados. Eles também acompanham “erros em cascata” — situações em que um pequeno deslize inicial no roteamento ou no rastreamento de estado aumenta dramaticamente a chance de que toda a tarefa desmorone mais adiante, deixando restrições importantes sem atendimento.
O que torna o roteamento mais estável
Usando um modelo baseado em DeBERTa como roteador e um FLAN-T5 como gerador, os autores comparam várias políticas de roteamento, incluindo regras simples e modelos aprendidos com e sem salvaguardas baseadas em confiança. Uma descoberta chave é que adicionar um mecanismo de filtragem sensível à confiança — agir apenas quando o roteador estiver suficientemente seguro e, caso contrário, recorrer a um comportamento mais seguro — reduz drasticamente as transferências instáveis. Em sua configuração principal, a precisão do roteamento sobe para cerca de 0,77, enquanto a taxa de alternância entre agentes diminui e os padrões de "salto", onde o sistema oscila de um lado para outro, praticamente desaparecem. Ao mesmo tempo, observam que ser conservador demais pode reduzir a quantidade de atualizações úteis de estado registradas, revelando uma tensão entre tomar decisões precisas e avançar de maneira estável em direção ao objetivo do usuário.
Por que essas lições se aplicam além do caso estudado
Para testar quão gerais são essas percepções, os autores aplicam as mesmas métricas de orquestração a outro benchmark, o conjunto de dados Schema-Guided Dialogue, que possui domínios e esquemas diferentes. O desempenho cai no geral, mas os problemas básicos de coordenação permanecem: roteamento incorreto e atualizações de estado faltantes continuam sendo os principais culpados, enquanto loops são relativamente raros. Isso sugere que os padrões observados não são peculiaridades de um único conjunto de dados, mas refletem desafios mais profundos na coordenação de muitos agentes ao longo de conversas longas e mutáveis.
O que isso significa para assistentes do futuro
Para não especialistas, a conclusão é que construir chatbots com múltiplas habilidades confiáveis diz tanto respeito a organizar o trabalho interno entre eles quanto a treinar modelos de linguagem maiores. O artigo oferece um plano concreto e um critério para comparar estratégias de orquestração, mostrando como decisões de roteamento iniciais, rastreamento de estado e comportamento de transferência moldam conjuntamente se uma conversa desvia silenciosamente do curso ou completa com sucesso tarefas complexas. Ao destacar o trade-off entre precisão e progresso e ao expor como pequenos erros iniciais podem se transformar em avalanche, o trabalho fornece aos projetistas de sistemas ferramentas práticas para ajustar e monitorar enxames de agentes antes de implantá-los em funções de alto risco voltadas ao cliente.
Citação: Khan, A., Masood, F., Iqbal, A. et al. Evaluating routing stability and coordination in swarm-based multi-agent task-oriented dialogue systems. Sci Rep 16, 11813 (2026). https://doi.org/10.1038/s41598-026-42158-y
Palavras-chave: diálogo multiagente, IA conversacional, chatbots orientados a tarefas, estabilidade de roteamento, rastreamento do estado do diálogo