Clear Sky Science · it
Valutare la stabilità del routing e il coordinamento in sistemi dialogici multi-agente orientati ai compiti basati su sciami
Perché i chatbot più intelligenti contano
I chatbot stanno rapidamente diventando il primo punto di contatto quando si prenota un hotel, si cambia un volo o si chiede assistenza a un’azienda. Ma non appena una conversazione salta tra compiti — per esempio trovare un ristorante, controllare l’orario di un treno e pagare una bolletta — i sistemi odierni spesso vacillano. Questo articolo guarda sotto il cofano degli assistenti “a sciame” composti da molti piccoli bot specialistici guidati da un controller centrale e pone una domanda semplice ma cruciale: come possiamo sapere se questo lavoro di squadra interno è davvero stabile e affidabile, e non solo scorrevole in superficie?
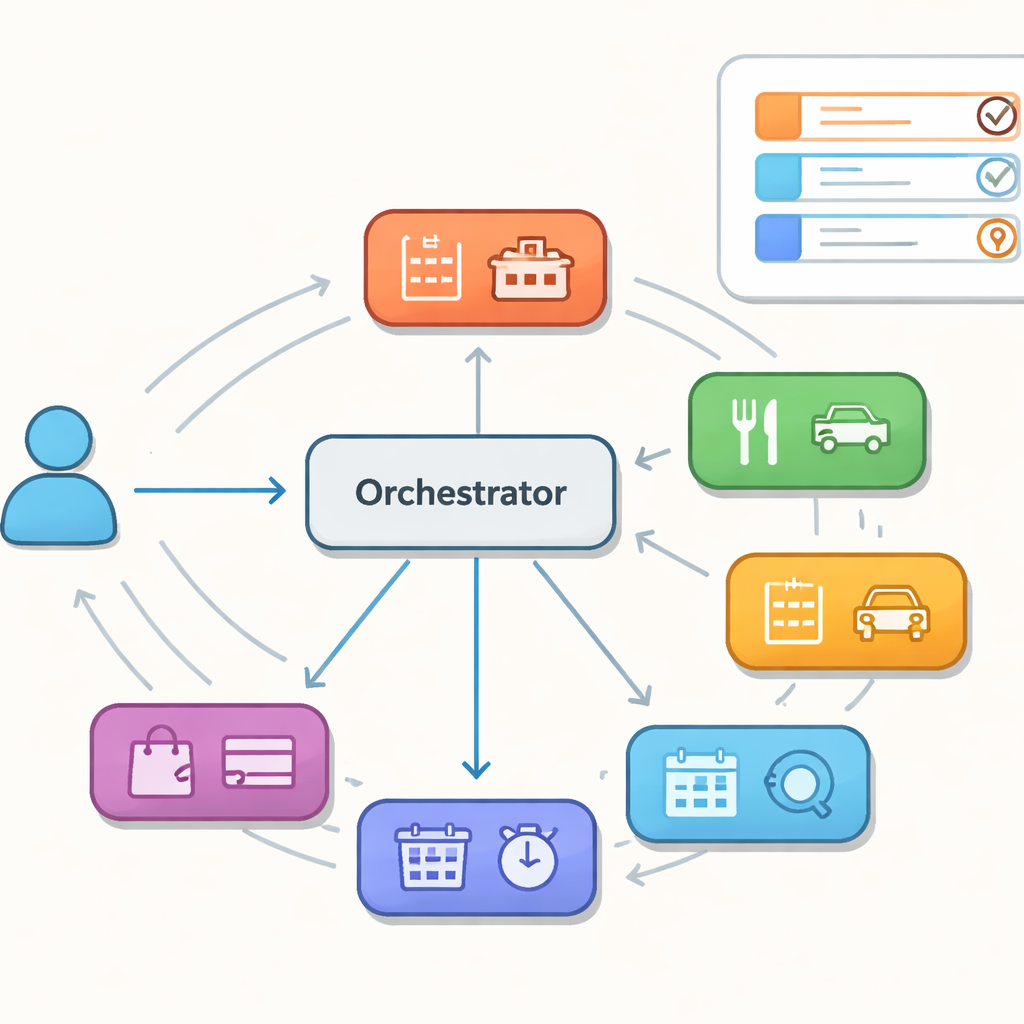
Molti aiutanti, un direttore d’orchestra
Invece di un unico modello gigante che gestisce tutto, gli autori studiano assistenti costruiti da una collezione di agenti specialistici, ciascuno esperto in un dominio ristretto come hotel, ristoranti o taxi. Un orchestratore centrale decide, turno dopo turno, quale specialista dovrebbe agire e mantiene una memoria condivisa di ciò che l’utente desidera finora. Questa configurazione, talvolta paragonata a uno sciame di agenti cooperanti, promette flessibilità e manutenzione più semplice. Tuttavia, crea anche nuove modalità di errore: il controller potrebbe inviare un turno allo specialista sbagliato, girare in tondo tra gli agenti o non riuscire a mantenere coerente la memoria condivisa quando cambia il controllo. Questi passi falsi nascosti potrebbero non emergere in una singola risposta, ma possono mandare fuori strada conversazioni più lunghe.
Misurare il lavoro di squadra, non solo il parlato
Per andare oltre demo aneddotiche, gli autori costruiscono una pipeline “valuation-first” su un popolare dataset multi-dominio chiamato MultiWOZ 2.2. Separano deliberatamente due componenti: un modello di routing che sceglie lo specialista e un modello linguistico che genera le azioni del sistema e aggiorna la credenza condivisa sugli obiettivi dell’utente. Decoupling queste parti permette di individuare se i problemi nascono da una cattiva delega o da una generazione linguistica difettosa. Definiscono quindi metriche focalizzate sul coordinamento: se lo specialista scelto corrisponde al dominio vero per quel turno, quanto progresso il sistema compie nel riempire i dettagli richiesti come date e luoghi, quanto spesso cambia o rimbalza tra agenti, se cade in loop e quanto bene si riprende dopo errori iniziali.
Sottoporre il sistema a stress
Il team non si ferma a conversazioni di test statiche. Introducono test di stress che imitano le frizioni del mondo reale: utenti che riformulano richieste, correggono informazioni precedenti dopo molti turni o strumenti che rispondono lentamente. Queste perturbazioni mantengono i compiti originali ma disturbano il contesto che il router vede, permettendo ai ricercatori di verificare quanto sia robusta l’orchestrazione quando la realtà si discosta dagli script annotati nel dataset. Tengono anche traccia degli “errori a catena” — situazioni in cui una piccola sbandata precoce nel routing o nel tracciamento dello stato aumenta drasticamente la probabilità che l’intero compito crolli in seguito, lasciando vincoli importanti insoddisfatti.
Cosa rende il routing più stabile
Utilizzando un modello basato su DeBERTa come router e un modello FLAN-T5 come generatore, gli autori confrontano diverse politiche di routing, incluse regole semplici e modelli appresi con e senza salvaguardie basate sulla confidenza. Un risultato chiave è che aggiungere un meccanismo di gating sensibile alla confidenza — agire solo quando il router è sufficientemente sicuro e altrimenti ricorrere a comportamenti più cauti — riduce nettamente i passaggi di consegna instabili. Nel loro setting principale, l’accuratezza del routing sale a circa 0,77, mentre il tasso di cambiamento tra agenti diminuisce e i pattern di “rimbalzo”, in cui il sistema oscilla avanti e indietro, quasi scompaiono. Allo stesso tempo, osservano che essere troppo conservativi può ridurre la quantità di aggiornamenti di stato utili registrati, rivelando una tensione tra prendere decisioni precise e avanzare costantemente verso l’obiettivo dell’utente.
Perché queste lezioni si trasferiscono
Per testare quanto siano generali queste intuizioni, gli autori applicano le stesse metriche di orchestrazione a un altro benchmark, il dataset Schema-Guided Dialogue, che ha domini e schemi differenti. Le prestazioni calano nel complesso, ma i problemi di coordinamento di base rimangono: il routing errato e gli aggiornamenti di stato mancanti sono ancora i principali colpevoli, mentre i loop sono relativamente rari. Ciò suggerisce che i pattern osservati non sono vezzi di un singolo dataset ma riflettono sfide più profonde nel coordinare molti agenti su conversazioni lunghe e mutevoli.
Cosa significa per i futuri assistenti
Per i non specialisti, la conclusione è che costruire chatbot multi-abilità affidabili riguarda tanto l’organizzazione del lavoro di squadra interno quanto l’addestramento di modelli linguistici più grandi. L’articolo offre un progetto concreto e un metro di giudizio per confrontare strategie di orchestrazione, mostrando come decisioni di routing precoci, tracciamento dello stato e comportamento nelle consegne congiunte plasmino se una conversazione si allontana silenziosamente dal percorso o completa con successo compiti complessi. Evidenziando il compromesso tra accuratezza e progresso e mostrando come piccoli errori iniziali possano ingigantirsi, il lavoro fornisce ai progettisti strumenti pratici per tarare e monitorare gli sciami di agenti prima di schierarli in ruoli di grande responsabilità verso i clienti.
Citazione: Khan, A., Masood, F., Iqbal, A. et al. Evaluating routing stability and coordination in swarm-based multi-agent task-oriented dialogue systems. Sci Rep 16, 11813 (2026). https://doi.org/10.1038/s41598-026-42158-y
Parole chiave: dialogo multi-agente, IA conversazionale, chatbot orientati ai compiti, stabilità del routing, tracciamento dello stato del dialogo