Clear Sky Science · sv
EEG-förbehandling av föreställd tal-neurosignal och klassificering med djupinlärning
Att förvandla tysta tankar till möjlig tal
Föreställ dig att kunna ”höra” vad någon tänker utan att personen rör sina läppar alls. För personer som är förlamade eller oförmögna att tala kan en sådan teknik vara livsförändrande och låta dem kommunicera enbart med sina tankar. Denna studie tar ett stort steg mot det målet genom att visa hur man kan läsa föreställda ord ur hjärnvågor mätta med en enkel, bärbar mössa. Genom att noggrant rengöra signalerna och använda modern djupinlärning visar författarna att tyst föreställda bokstäver, siffror och föremål kan kännas igen med anmärkningsvärd tillförlitlighet.
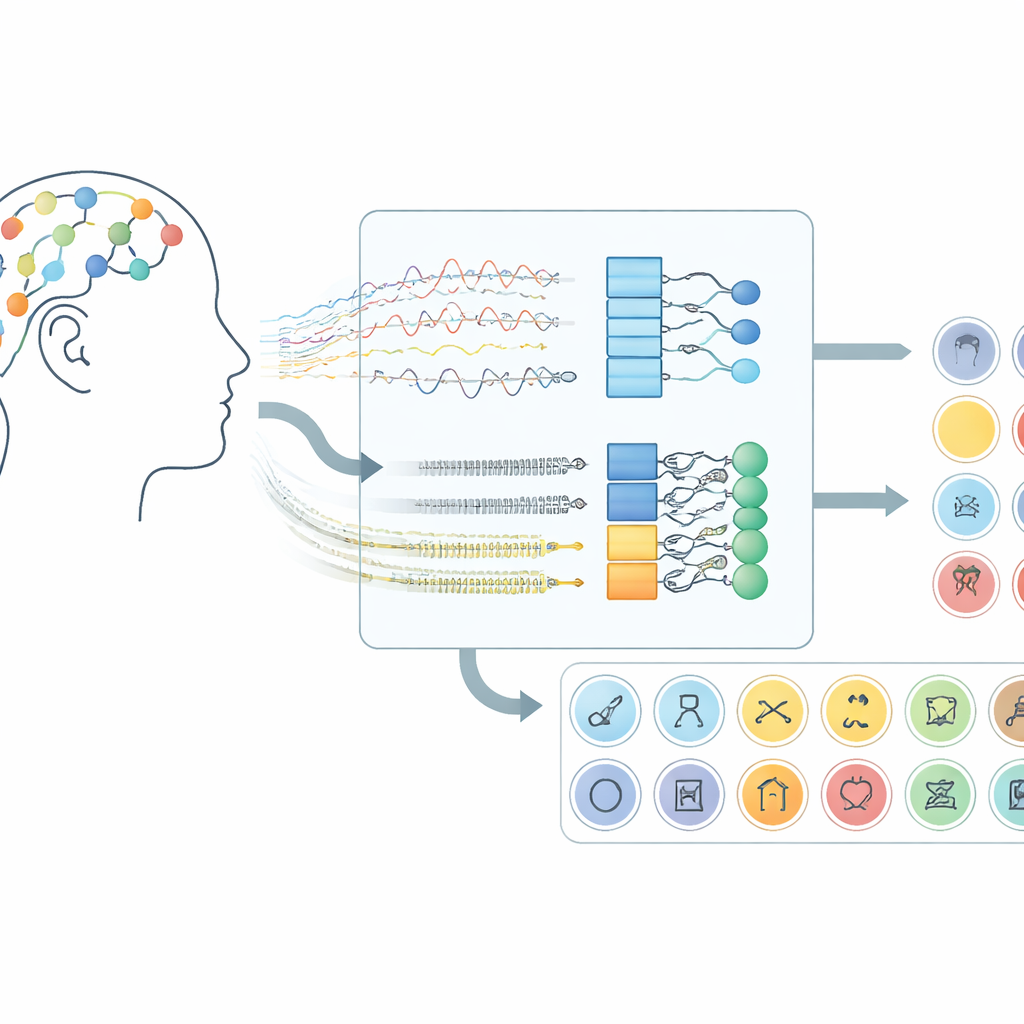
Hur hjärnsignaler blir en kommunikationskanal
Arbetet fokuserar på hjärn–datorgränssnitt som använder elektroencefalografi (EEG), en teknik som registrerar små spänningsförändringar från sensorer placerade på skalpen. Istället för att be deltagarna röra händerna eller föreställa sig rörelser lyssnar detta system efter den hjärnaktivitet som uppstår när människor tyst ”uttalar” ord i sitt sinne. I den dataset som används här föreställde frivilliga sig 30 olika objekt från tre grupper: alfabetets tecken, siffror och vardagsföremål. Varje försök varade i tio sekunder, och signaler från 14 skalppositioner fångades med ett trådlöst headset, vilket visar att detta tillvägagångssätt kan fungera med konsumenthårdvara istället för kirurgiskt implanterade enheter.
Rengöring av signalen innan tanken läses
Råa EEG-inspelningar är stökiga. De fångar inte bara hjärnaktivitet utan även ögonblinkningar, spänningar i ansiktsmuskler, hjärtslag samt elektriskt brus från omgivningen. Författarna utformade en sexstegs förbehandlingspipeline för att avlägsna så mycket av detta skräp som möjligt samtidigt som mönstren kopplade till föreställt tal bevaras. Först delar en matematisk metod upp signalen i oberoende komponenter så att artefaktlika delar kan tas bort automatiskt. Därefter konverteras data till frekvensdomänen, där vissa besvärliga rytmer dämpas med ett noggrant justerat filter som undviker att förvränga timing. De rengjorda signalerna konverteras tillbaka till tidsdomänen, delas upp i korta fönster och standardiseras så att alla kanaler får samma skala. Denna etappvisa ”tvätt och omformning” av data förvandlar kaotiska spår till välordnade snippets som en inlärningsalgoritm kan förstå.
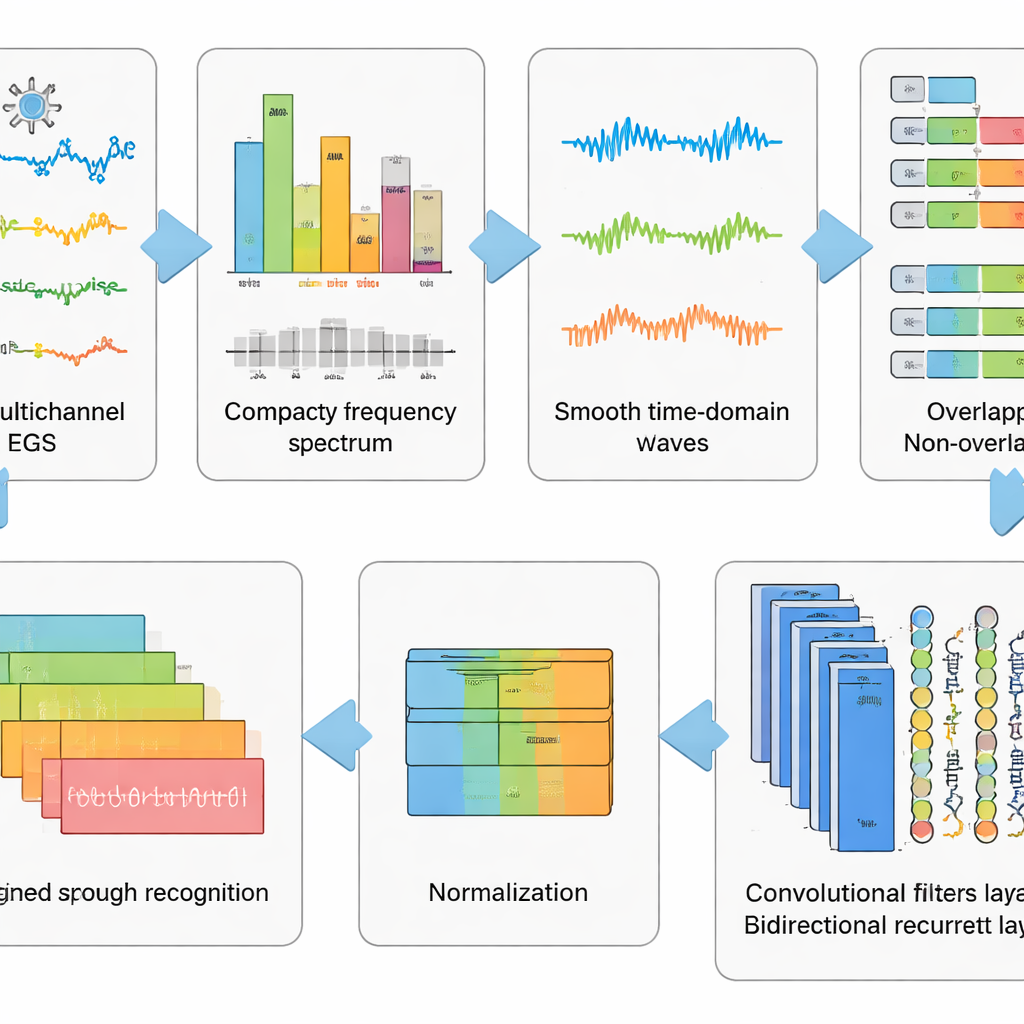
Låta djupa nätverk lära sig de dolda mönstren
Ovanpå denna förbehandling testade teamet fem närbesläktade djupinlärningsmodeller som kombinerar två typer av neurala nätverk. Konvolutionslager fungerar som små mönsterdetektorer som glider längs EEG-kanalerna och plockar upp rumslig och lokal-tidsstruktur. Long Short-Term Memory (LSTM)-lager följer sedan hur dessa mönster utvecklas över tid och fångar flödet av hjärnaktivitet under det föreställda ordet. Vissa versioner ser endast framåt i tiden, medan en nyckelvariant ser både framåt och bakåt och därigenom ger en mer komplett bild av signalens rytm. Genom att jämföra dessa nätverksdesigner visade forskarna att användning av både konvolution och en bidirektionell form av LSTM ger den mest kraftfulla representationen av föreställt tal.
Sätta systemet på realistiska tester
En avgörande fråga är inte bara om en modell kan avkoda tankar hos personer den redan sett, utan om den fungerar på nya individer. För att undersöka detta använde författarna flera teststrategier. Enkla slumpmässiga uppdelningar, som ofta använts i tidigare arbeten, målar en mycket optimistisk bild: med deras fullständiga pipeline klassificerade den bästa modellen alla 30 föreställda objekt med mer än 99 % noggrannhet. När de tillämpade striktare scheman som förhindrar att överlappande tidssegment läcker mellan tränings- och testdata höll sig prestandan hög. Mest krävande var ett "leave-one-subject-out"-test, där systemet tränades på många frivilliga och sedan utvärderades på en helt ny person, med endast ett litet kalibreringsprov. Även där identifierade det korrekt det föreställda objektet nästan fyra gånger oftare än en stark nyligen konkurrerande modell och gjorde det med mycket snabbare svarstider, vilket stöder interaktion i realtid.
Vad detta betyder för framtida tysta tal-enheter
För en icke-specialist är huvudslutsatsen att avkodning av föreställt tal inte längre är science fiction begränsat till små lek-vokabulärer. Genom att aggressivt rengöra EEG-signalerna och para dem med ett smart, bidirektionellt djupt nätverk visar denna studie att ett headset pålitligt kan skilja mellan 30 olika tyst föreställda objekt, även vid överföring till nya användare. Att omvandla fria, flytande tankar till tal i full skala kommer visserligen att kräva större vokabulärer och mer avancerade konstruktioner, men detta arbete ger en solid grund: det bevisar att med rätt förbehandling och inlärningsstrategi kan hjärnans viskande av ett outalat ord bli en tydlig, maskinläsbar signal.
Citering: Elwasify, F., Shaaban, E. & Abdelmoneem, R.M. EEG imagined speech neuro-signal preprocessing and deep learning classification. Sci Rep 16, 10604 (2026). https://doi.org/10.1038/s41598-026-39395-6
Nyckelord: föreställt tal, EEG hjärn–datorgränssnitt, djupinlärning, signalförbehandling, neural avkodning