Clear Sky Science · fr
Prétraitement des neuro-signaux EEG d’un discours imaginé et classification par apprentissage profond
Transformer des pensées silencieuses en parole potentielle
Imaginez pouvoir « entendre » ce que quelqu’un pense dire sans qu’il ne bouge les lèvres. Pour les personnes paralysées ou incapables de parler, une telle technologie pourrait changer la vie en leur permettant de communiquer uniquement par la pensée. Cette étude fait un pas important vers cet objectif en montrant comment lire des mots imaginés à partir d’ondes cérébrales mesurées avec une simple coiffe portable. En nettoyant soigneusement les signaux et en utilisant l’apprentissage profond moderne, les auteurs montrent que des lettres, chiffres et objets imaginés silencieusement peuvent être reconnus avec une fiabilité remarquable.
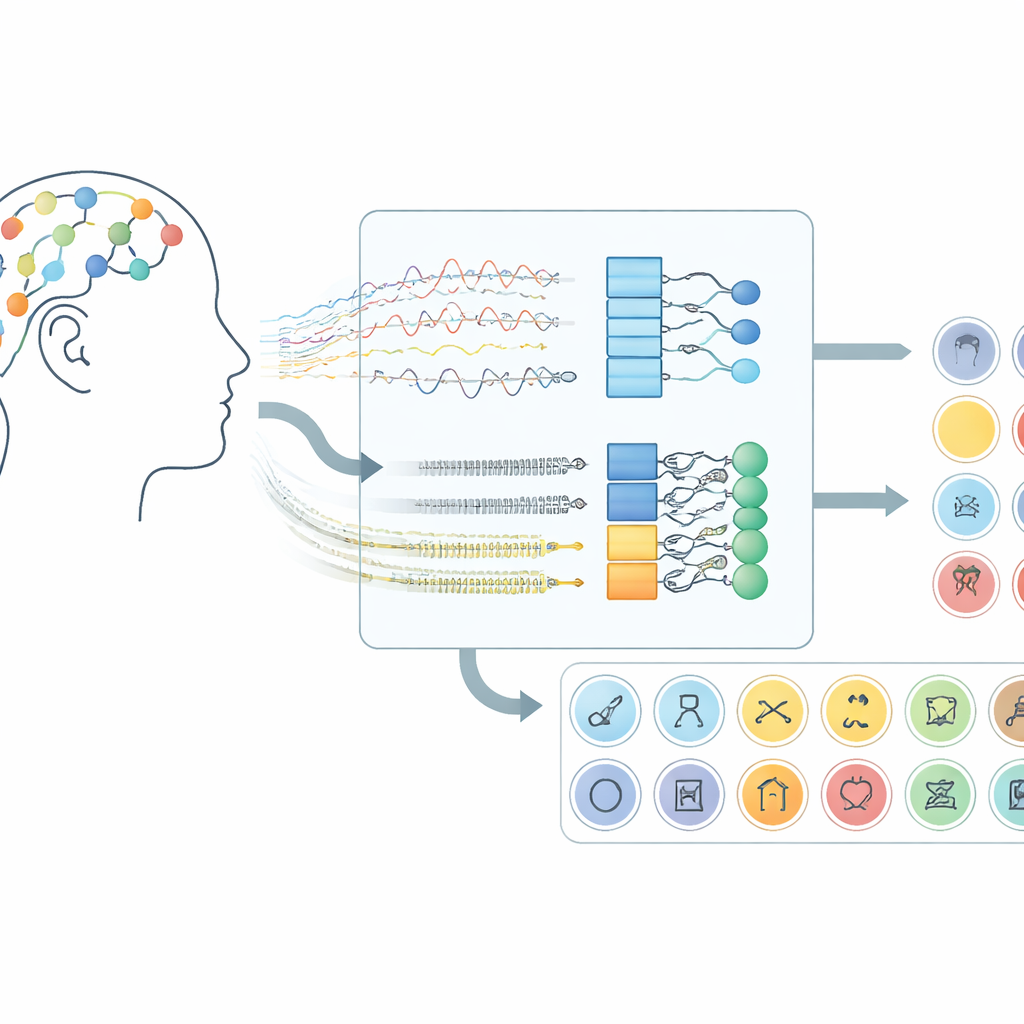
Comment les signaux cérébraux deviennent un canal de communication
Le travail porte sur des interfaces cerveau‑ordinateur utilisant l’électroencéphalographie (EEG), une technique qui enregistre de très faibles variations de tension à partir de capteurs placés sur le cuir chevelu. Plutôt que de demander aux participants de bouger les mains ou d’imaginer des gestes, ce système écoute l’activité cérébrale qui apparaît lorsque les personnes « prononcent » silencieusement des mots dans leur esprit. Dans le jeu de données utilisé ici, des volontaires ont imaginé 30 éléments différents répartis en trois groupes : caractères alphabétiques, chiffres et objets du quotidien. Chaque essai durait dix secondes, et les signaux de 14 positions scalpaires ont été capturés à l’aide d’un casque sans fil, montrant que cette approche fonctionne avec du matériel grand public plutôt qu’avec des dispositifs implantés chirurgicalement.
Nettoyer le signal avant de lire la pensée
Les enregistrements EEG bruts sont désordonnés. Ils captent non seulement l’activité cérébrale mais aussi les clignements des yeux, la tension des muscles du visage et les battements du cœur, ainsi que le bruit électrique ambiant. Les auteurs ont conçu une chaîne de prétraitement en six étapes pour éliminer autant que possible cet encombrement tout en conservant les motifs liés au discours imaginé. D’abord, une méthode mathématique sépare le signal en composantes indépendantes afin que les parties ressemblant à des artefacts puissent être retirées automatiquement. Ensuite, les données sont converties dans le domaine fréquentiel, où certains rythmes gênants sont atténués à l’aide d’un filtre finement réglé qui évite de déformer la temporisation. Les signaux nettoyés sont reconvertis dans le domaine temporel, découpés en courtes fenêtres et standardisés pour que tous les canaux partagent une échelle commune. Ce « lavage et remodelage » progressif des données transforme des traces chaotiques en extraits bien calibrés qu’un algorithme d’apprentissage peut comprendre.
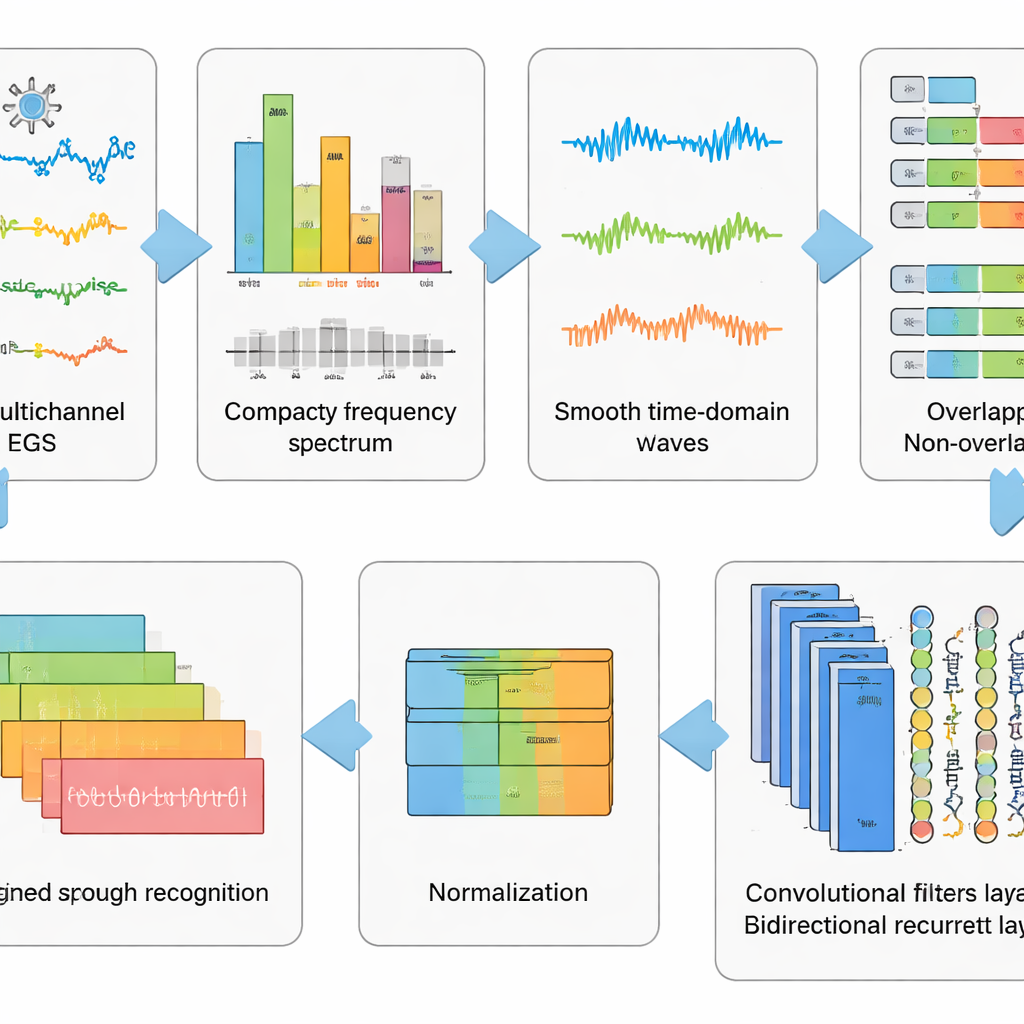
Laisser les réseaux profonds apprendre les motifs cachés
Par-dessus ce prétraitement, l’équipe a testé cinq modèles d’apprentissage profond apparentés qui combinent deux types de réseaux neuronaux. Les couches convolutionnelles agissent comme de petits détecteurs de motifs glissant le long des canaux EEG, captant la structure spatiale et temporelle locale. Les couches Long Short‑Term Memory (LSTM) suivent ensuite l’évolution de ces motifs au fil du temps, saisissant le flux d’activité cérébrale durant le mot imaginé. Certaines variantes ne regardent que vers l’avant dans le temps, tandis qu’un variant clé explore à la fois vers l’avant et vers l’arrière, offrant une vue plus complète du rythme du signal. En comparant ces architectures, les chercheurs ont montré que la combinaison de convolutions et d’un LSTM bidirectionnel fournit la représentation la plus puissante du discours imaginé.
Soumettre le système à des tests réalistes
Une question cruciale n’est pas seulement de savoir si un modèle peut décoder les pensées de personnes qu’il a déjà vues, mais s’il fonctionne sur de nouveaux individus. Pour l’explorer, les auteurs ont utilisé plusieurs stratégies de test. Les divisions aléatoires simples, souvent employées dans des travaux antérieurs, donnent un tableau très optimiste : avec leur chaîne complète, le meilleur modèle classifiait les 30 éléments imaginés avec plus de 99 % de précision. Lorsqu’ils ont appliqué des schémas plus stricts empêchant le chevauchement de segments temporels entre les ensembles d’entraînement et de test, la performance est restée élevée. Le plus exigeant, le test « leave-one-subject-out », consistait à entraîner le système sur de nombreux volontaires puis à l’évaluer sur une personne complètement nouvelle, avec seulement un petit échantillon d’étalonnage. Là encore, il identifiait correctement l’élément imaginé près de quatre fois plus souvent qu’un modèle concurrent récent et le faisait avec des temps de réponse beaucoup plus courts, soutenant une interaction en temps réel.
Ce que cela signifie pour les dispositifs de parole silencieuse à venir
Pour un non‑spécialiste, la conclusion principale est que le décodage du discours imaginé n’est plus une fantaisie de science‑fiction limitée à de petits vocabulaires ludiques. En nettoyant agressivement les signaux EEG et en les associant à un réseau profond bidirectionnel performant, cette étude montre qu’un casque peut distinguer de manière fiable 30 éléments différents imaginés silencieusement, même lors du passage à de nouveaux utilisateurs. Transformer des pensées en langage libre et fluide exigera des vocabulaires plus larges et des architectures plus avancées, mais ce travail fournit une base solide : il prouve qu’avec le bon prétraitement et la bonne stratégie d’apprentissage, le murmure cérébral d’un mot non prononcé peut être converti en un signal clair et lisible par machine.
Citation: Elwasify, F., Shaaban, E. & Abdelmoneem, R.M. EEG imagined speech neuro-signal preprocessing and deep learning classification. Sci Rep 16, 10604 (2026). https://doi.org/10.1038/s41598-026-39395-6
Mots-clés: discours imaginé, interface cerveau‑ordinateur EEG, apprentissage profond, prétraitement du signal, décodage neural