Clear Sky Science · ru
Предобработка нейросигналов ЭЭГ при воображаемой речи и их классификация глубоким обучением
Превращая молчаливые мысли в возможную речь
Представьте, что можно «услышать», что человек говорит, не шевеля губами. Для людей с параличом или неспособных говорить такая технология могла бы изменить жизнь, позволяя им общаться только силой мысли. Это исследование делает большой шаг к этой цели, показывая, как считывать воображаемые слова по мозговым волнам, измеренным с помощью простой носимой шапочки. Тщательно очистив сигналы и применив современные методы глубокого обучения, авторы демонстрируют, что молчаливо воображаемые буквы, цифры и предметы можно распознавать с впечатляющей достоверностью.
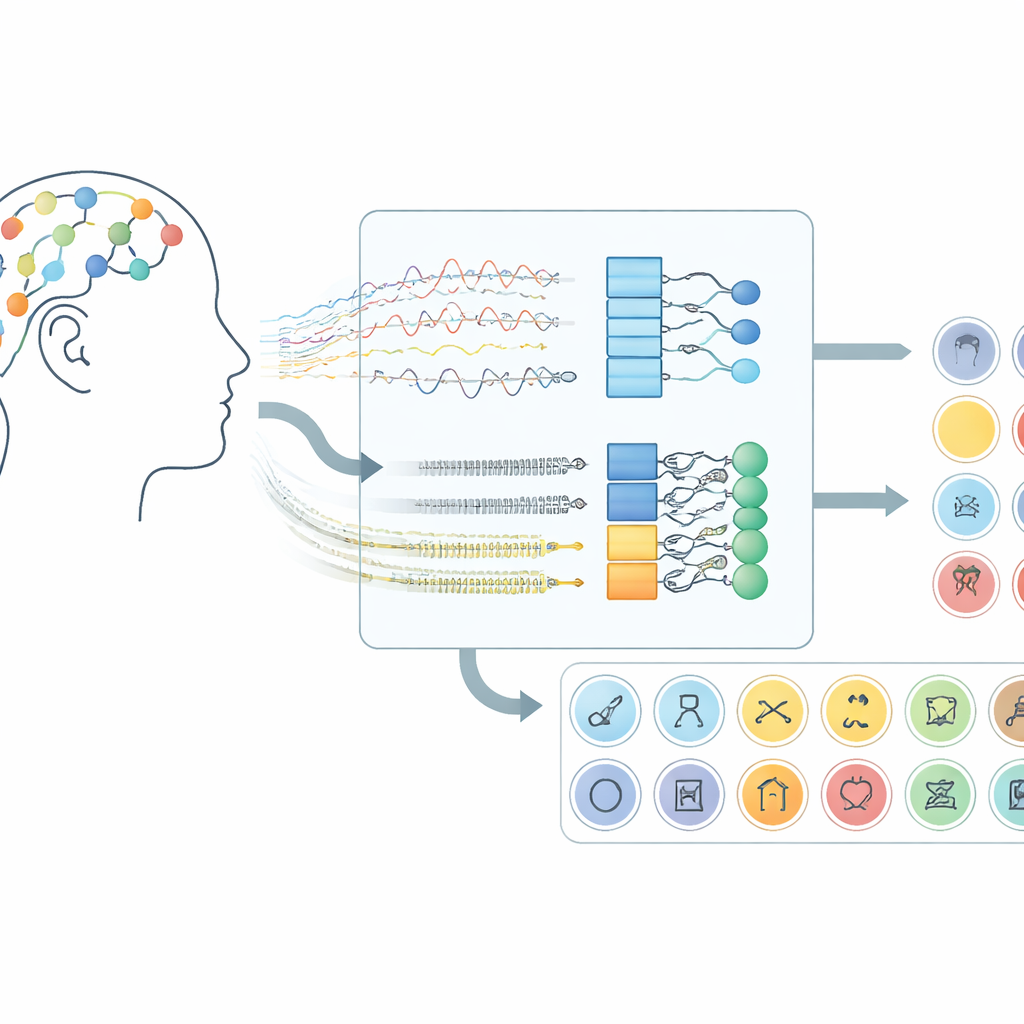
Как мозговые сигналы становятся каналом связи
Работа фокусируется на интерфейсах мозг–компьютер, использующих электроэнцефалографию (ЭЭГ) — метод регистрации крошечных изменений напряжения с датчиков на коже головы. Вместо того чтобы просить участников двигать руками или представлять движения, система «слушает» активность мозга, возникающую, когда люди молча «произносят» слова в уме. В используемом наборе данных добровольцы воображали 30 разных элементов из трёх групп: буквенные символы, цифры и предметы повседневного обихода. Каждый эксперимент длился десять секунд, и сигналы с 14 участков кожи головы регистрировались с помощью беспроводной гарнитуры, что показывает — подход работает на потребительском оборудовании, а не только на вживлённых устройствах.
Очистка сигнала перед чтением мысли
Сырые ЭЭГ-записи громоздки. Они захватывают не только активность мозга, но и моргания, напряжение лицевых мышц и сердечный ритм, а также электромагнитные помехи из окружения. Авторы разработали шестишаговый конвейер предобработки, чтобы убрать как можно больше этого шума, сохранив при этом паттерны, связанные с воображаемой речью. Сначала математический метод разделяет сигнал на независимые компоненты, чтобы артефактоподобные части можно было автоматически удалить. Затем данные переводятся в частотную область, где определённые проблемные ритмы подавляются с помощью тщательно настроенного фильтра, который не искажает временную структуру. Очищенные сигналы возвращаются во временную область, разбиваются на короткие окна и стандартизируются, чтобы все каналы имели общий масштаб. Это поэтапное «мытьё и перестройка» данных превращает хаотичные следы в аккуратные фрагменты, понятные алгоритму обучения.
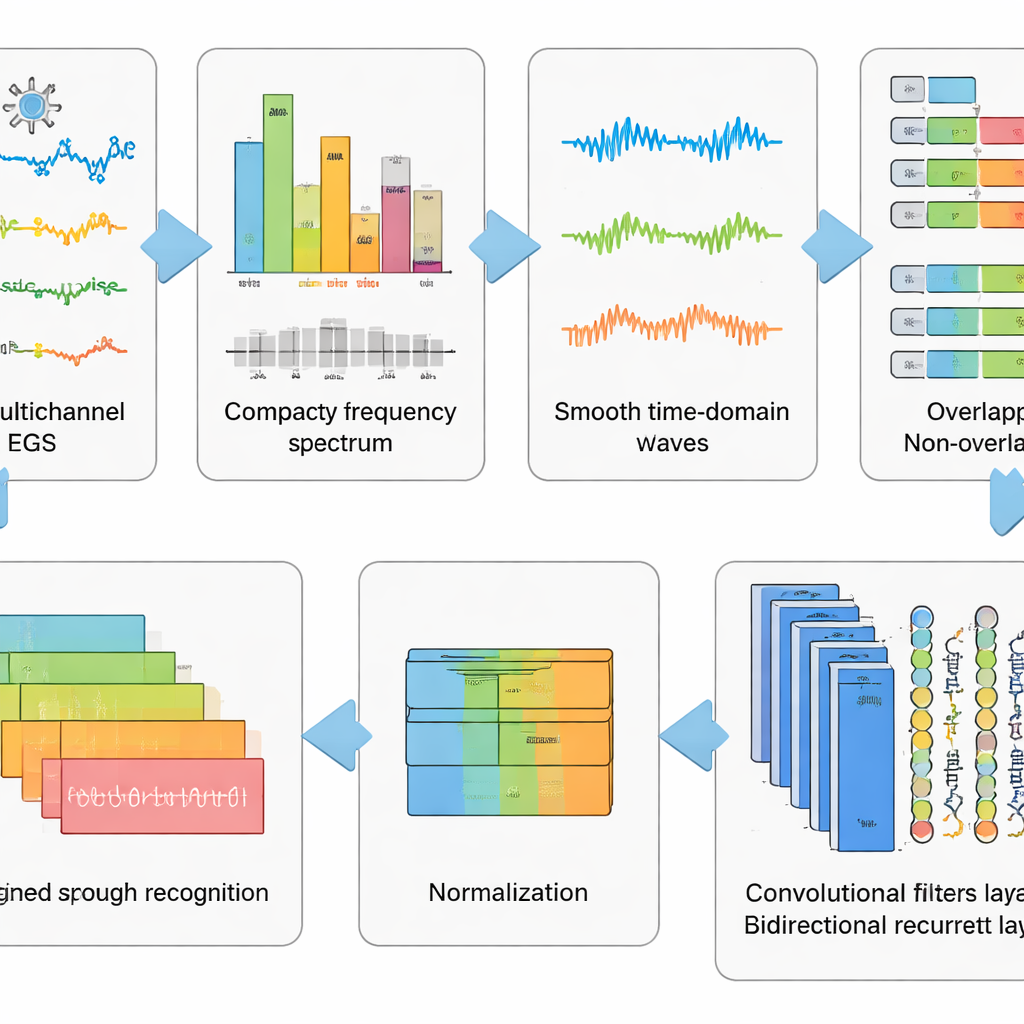
Давая глубоким сетям возможность выучить скрытые закономерности
Поверх предобработки команда протестировала пять родственных моделей глубокого обучения, сочетающих два типа нейросетей. Сверточные слои работают как мелкие детекторы шаблонов, скользящие по каналам ЭЭГ и улавливающие пространственную и локально-временную структуру. Слои Long Short-Term Memory (LSTM) затем отслеживают эволюцию этих паттернов во времени, фиксируя динамику мозговой активности во время воображаемого слова. Некоторые версии смотрят только в прямом временном направлении, тогда как ключевой вариант анализирует сигнал и вперёд, и назад, давая более полное представление о ритме. Сравнивая такие архитектуры, исследователи показали, что сочетание свёртки и двунаправленного LSTM даёт наиболее сильное представление воображаемой речи.
Проверка системы в реалистичных условиях
Крайне важный вопрос — работает ли модель не только на тех людях, которых она видела в обучении, но и на новых участниках. Чтобы проверить это, авторы применили несколько стратегий тестирования. Простые случайные разбиения, часто используемые в ранних работах, дают очень оптимистичную картину: с полным конвейером их лучшая модель классифицировала все 30 воображаемых элементов с точностью более 99%. При применении более строгих схем, исключающих утечку временных сегментов между обучением и тестом, производительность оставалась высокой. Самый требовательный режим — «оставить одного испытуемого в стороне» (leave-one-subject-out): систему обучали на множестве добровольцев, а затем оценивали на совершенно новом человеке, с использованием только небольшой калибровочной выборки. И там модель правильно определяла воображаемый элемент почти в четыре раза чаще, чем сильный недавний конкурент, при этом с гораздо более быстрым временем отклика, что подтверждает возможность интерактивной работы в реальном времени.
Что это значит для будущих устройств молчаливой речи
Для неспециалиста главный вывод таков: декодирование воображаемой речи перестало быть научно-фантастической идеей, ограниченной небольшими словарями. Агрессивно очистив ЭЭГ-сигналы и сочетая их с продуманной двунаправленной глубокой сетью, это исследование показывает, что гарнитура может надёжно различать 30 различных молчаливо воображаемых элементов, даже при переходе на новых пользователей. Хотя превращение произвольных мыслей в беглую речь потребует больших словарей и более сложных решений, эта работа закладывает прочную основу: она доказывает, что при правильной предобработке и стратегии обучения шёпот не произнесённого слова в мозге можно превратить в чёткий сигнал, читаемый машиной.
Цитирование: Elwasify, F., Shaaban, E. & Abdelmoneem, R.M. EEG imagined speech neuro-signal preprocessing and deep learning classification. Sci Rep 16, 10604 (2026). https://doi.org/10.1038/s41598-026-39395-6
Ключевые слова: воображаемая речь, интерфейс мозг–компьютер ЭЭГ, глубокое обучение, предобработка сигналов, нейронное декодирование