Clear Sky Science · de
EEG-Vorstellungsrede: Neuronale Signalvorverarbeitung und Deep-Learning-Klassifikation
Stille Gedanken in mögliche Sprache verwandeln
Stellen Sie sich vor, Sie könnten „hören“, was jemand sagt, ohne dass die Person ihre Lippen bewegt. Für Menschen, die gelähmt oder nicht in der Lage zu sprechen sind, könnte eine solche Technologie das Leben verändern, indem sie Kommunikation allein mit Gedanken ermöglicht. Diese Studie macht einen wichtigen Schritt in diese Richtung, indem sie zeigt, wie man vorgestellte Wörter aus Hirnwellen liest, die mit einer einfachen, tragbaren Haube gemessen wurden. Durch eine sorgfältige Bereinigung der Signale und den Einsatz moderner Deep-Learning-Verfahren zeigen die Autoren, dass still vorgestellte Buchstaben, Ziffern und Gegenstände mit bemerkenswerter Zuverlässigkeit erkannt werden können.
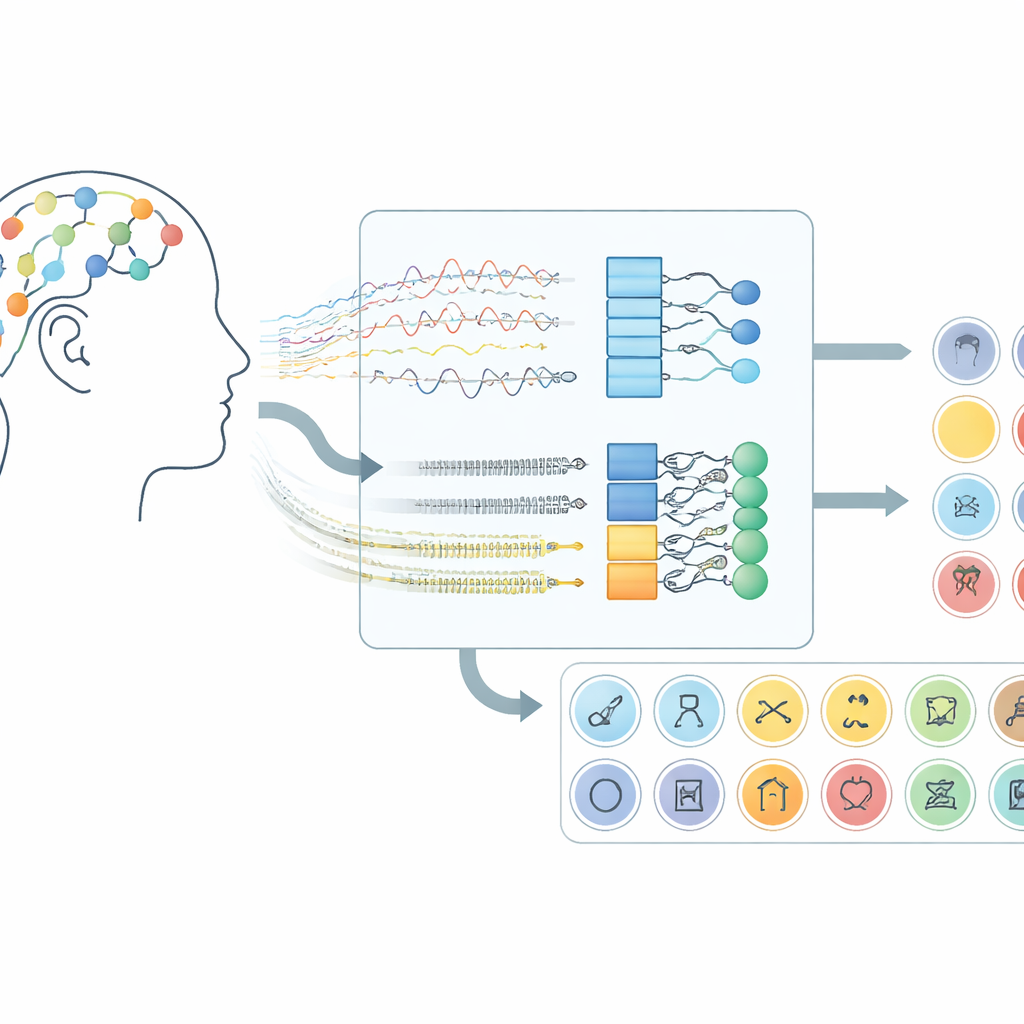
Wie Gehirnsignale zu einem Kommunikationskanal werden
Die Arbeit konzentriert sich auf Gehirn‑Computer‑Schnittstellen, die Elektroenzephalografie (EEG) verwenden, eine Technik, die winzige Spannungsänderungen mit Sensoren auf der Kopfhaut aufzeichnet. Anstatt die Teilnehmenden zu bitten, Hände zu bewegen oder Bewegungen vorzustellen, lauscht dieses System der Gehirnaktivität, die auftritt, wenn Menschen im Stillen Wörter in ihrem Geist „aussprechen“. Im hier verwendeten Datensatz stellten sich Freiwillige 30 verschiedene Elemente aus drei Gruppen vor: Buchstaben des Alphabets, Ziffern und Alltagsgegenstände. Jeder Versuch dauerte zehn Sekunden, und Signale von 14 Kopfhautpositionen wurden mit einem drahtlosen Headset erfasst, was zeigt, dass dieser Ansatz mit Consumer‑Hardware statt mit chirurgisch implantierten Geräten funktionieren kann.
Das Signal reinigen, bevor der Gedanke gelesen wird
Roh‑EEG‑Aufzeichnungen sind unordentlich. Sie erfassen nicht nur Gehirnaktivität, sondern auch Augenblinzeln, Gesichtsmuskulatur, Herzschlag sowie elektrische Störungen aus der Umgebung. Die Autoren entwarfen eine sechsphasige Vorverarbeitungspipeline, um dieses Rauschen so weit wie möglich zu entfernen und gleichzeitig die Muster zu erhalten, die mit vorgestellter Sprache zusammenhängen. Zuerst trennt eine mathematische Methode das Signal in unabhängige Komponenten, sodass artefaktähnliche Teile automatisch entfernt werden können. Anschließend werden die Daten in den Frequenzbereich überführt, wo bestimmte störende Rhythmen mit einem sorgfältig abgestimmten Filter unterdrückt werden, das Verzerrungen in der Zeitverteilung vermeidet. Die bereinigten Signale werden zurück in den Zeitbereich konvertiert, in kurze Fenster zerlegt und standardisiert, sodass alle Kanäle eine gemeinsame Skala haben. Diese gestufte „Wäsche und Umformung“ der Daten verwandelt chaotische Spuren in gut handhabbare Ausschnitte, die ein Lernalgorithmus verarbeiten kann.
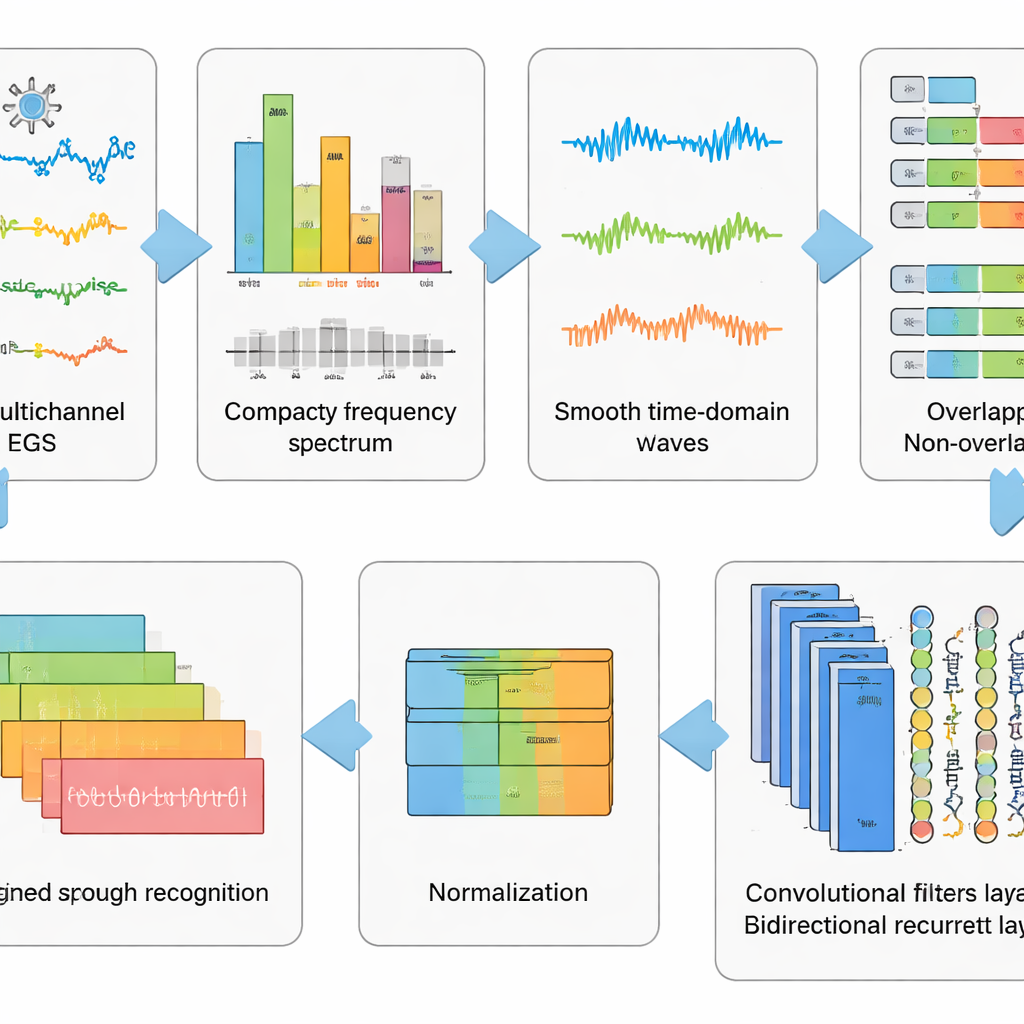
Die verborgenen Muster mit tiefen Netzen lernen lassen
Aufbauend auf dieser Vorverarbeitung testete das Team fünf verwandte Deep‑Learning‑Modelle, die zwei Arten neuronaler Netze kombinieren. Faltungsschichten (Convolutional Layers) agieren wie kleine Musterdetektoren, die entlang der EEG‑Kanäle gleiten und räumliche sowie lokale Zeitstrukturen erkennen. Long Short‑Term Memory (LSTM)‑Schichten folgen anschließend, um zu verfolgen, wie sich diese Muster über die Zeit entwickeln, und erfassen den Ablauf der Gehirnaktivität während des vorgestellten Wortes. Manche Varianten blicken nur vorwärts in der Zeit, während eine zentrale Variante sowohl vorwärts als auch rückwärts schaut und so ein vollständigeres Bild des Signalrhythmus liefert. Durch den Vergleich dieser Netzwerkdesigns zeigten die Forschenden, dass die Kombination aus Faltung und einer bidirektionalen LSTM die leistungsfähigste Darstellung vorgestellter Sprache liefert.
Das System realistisch testen
Eine entscheidende Frage ist nicht nur, ob ein Modell die Gedanken bereits bekannter Personen dekodieren kann, sondern ob es auch bei neuen Individuen funktioniert. Um dies zu prüfen, nutzten die Autoren mehrere Teststrategien. Einfache zufällige Aufteilungen, wie sie in früheren Arbeiten oft verwendet wurden, zeichnen ein sehr optimistisches Bild: Mit ihrer vollständigen Pipeline klassifizierte das beste Modell alle 30 vorgestellten Items mit über 99 % Genauigkeit. Als sie strengere Schemata anwendeten, die verhindern, dass sich zeitlich überlappende Segmente zwischen Trainings‑ und Testdaten vermischen, blieb die Leistung hoch. Am anspruchsvollsten war ein „Leave‑one‑subject‑out“-Test: Das System wurde an vielen Freiwilligen trainiert und dann an einer völlig neuen Person evaluiert, mit nur einer kleinen Kalibrierungsprobe. Auch dort identifizierte es das vorgestellte Item nahezu viermal so häufig wie ein starker, aktueller Konkurrenzansatz und erreichte dies mit deutlich schnelleren Reaktionszeiten, was Echtzeitinteraktion unterstützt.
Was das für künftige Silent‑Speech‑Geräte bedeutet
Für Nicht‑Spezialisten ist die wichtigste Erkenntnis, dass das Dekodieren vorgestellter Sprache nicht länger eine Science‑Fiction‑Vorstellung ist, beschränkt auf kleine „Spielzeug“-Vokabulare. Durch konsequente Bereinigung der EEG‑Signale und die Kombination mit einem schlauen, bidirektionalen Deep‑Net zeigt diese Studie, dass ein Headset zuverlässig zwischen 30 verschiedenen still vorgestellten Items unterscheiden kann, selbst beim Wechsel zu neuen Nutzern. Während die Umwandlung freier, flüssiger Gedanken in gesprochene Sprache ein größeres Vokabular und weiterentwickelte Designs erfordert, liefert diese Arbeit eine solide Grundlage: Sie beweist, dass man mit der richtigen Vorverarbeitung und Lernstrategie das Flüstern eines unausgesprochenen Wortes in ein klares, maschinenlesbares Signal verwandeln kann.
Zitation: Elwasify, F., Shaaban, E. & Abdelmoneem, R.M. EEG imagined speech neuro-signal preprocessing and deep learning classification. Sci Rep 16, 10604 (2026). https://doi.org/10.1038/s41598-026-39395-6
Schlüsselwörter: vorgestellte Sprache, EEG Gehirn‑Computer‑Schnittstelle, Deep Learning, Signalvorverarbeitung, neurale Dekodierung