Clear Sky Science · es
Preprocesamiento de neuroseñales EEG de habla imaginada y clasificación mediante aprendizaje profundo
Convertir pensamientos silenciosos en posible habla
Imagínese poder “escuchar” lo que alguien está diciendo sin que mueva los labios. Para personas paralizadas o incapaces de hablar, una tecnología así podría cambiarles la vida, permitiéndoles comunicarse usando solo sus pensamientos. Este estudio da un paso importante hacia ese objetivo al mostrar cómo leer palabras imaginadas a partir de las ondas cerebrales medidas con una simple gorra portátil. Mediante una limpieza cuidadosa de las señales y el uso de técnicas modernas de aprendizaje profundo, los autores demuestran que letras, números y objetos imaginados en silencio pueden reconocerse con una fiabilidad notable.
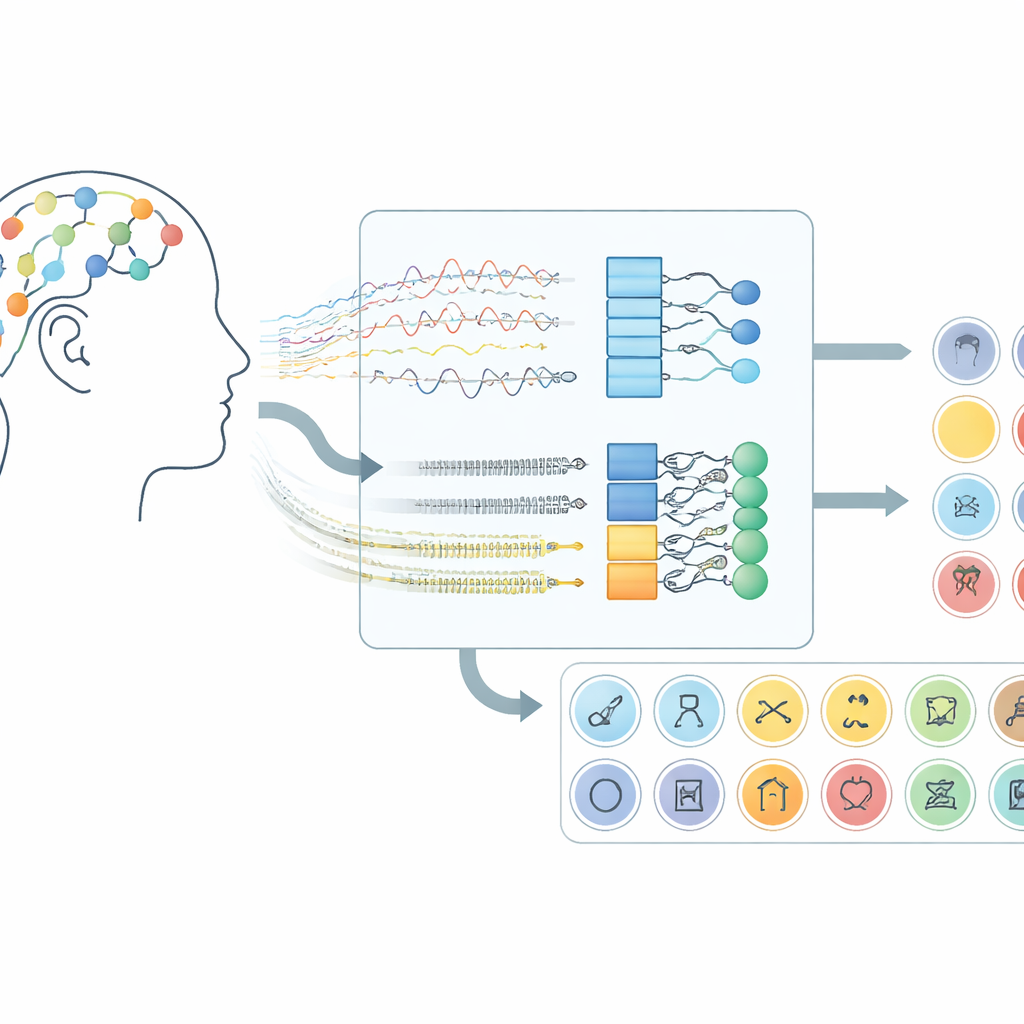
Cómo las señales cerebrales se convierten en un canal de comunicación
El trabajo se centra en interfaces cerebro–ordenador que emplean electroencefalografía (EEG), una técnica que registra pequeños cambios de voltaje mediante sensores colocados en el cuero cabelludo. En lugar de pedir a los participantes que muevan las manos o imaginen movimientos, este sistema escucha la actividad cerebral que aparece cuando las personas “pronuncian” silenciosamente palabras en su mente. En el conjunto de datos utilizado aquí, los voluntarios imaginaron 30 ítems diferentes de tres grupos: caracteres del alfabeto, dígitos y objetos cotidianos. Cada ensayo duró diez segundos y se capturaron señales de 14 ubicaciones en el cuero cabelludo usando una diadema inalámbrica, lo que demuestra que este enfoque puede funcionar con hardware de consumo en lugar de dispositivos implantados quirúrgicamente.
Limpiar la señal antes de leer el pensamiento
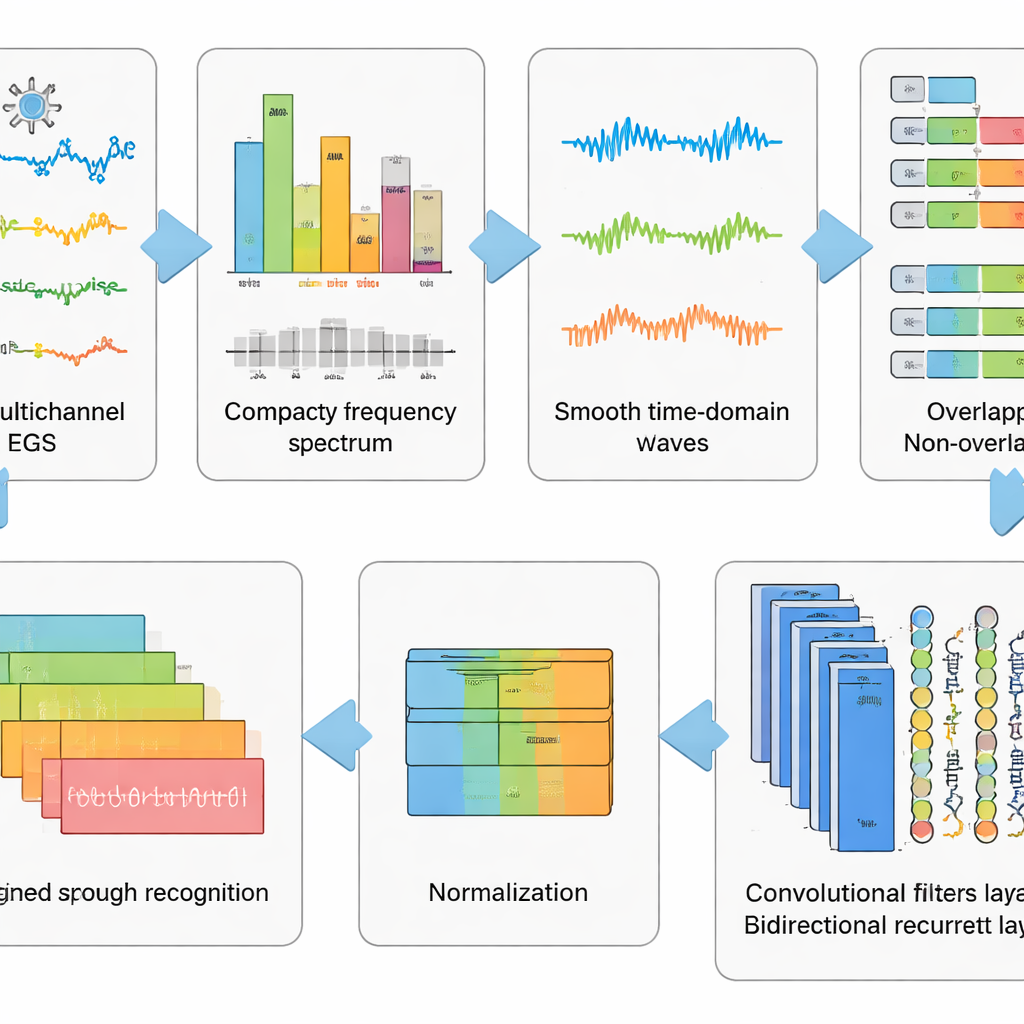
Las grabaciones EEG sin procesar son desordenadas. Capturan no solo la actividad cerebral, sino también parpadeos, tensión de los músculos faciales y el latido del corazón, además de ruido eléctrico del entorno. Los autores diseñaron una tubería de preprocesamiento de seis pasos para eliminar la mayor parte de este ruido posible mientras conservan los patrones vinculados al habla imaginada. Primero, un método matemático separa la señal en componentes independientes para que las partes con apariencia de artefacto puedan eliminarse automáticamente. Luego los datos se convierten al dominio de la frecuencia, donde ciertos ritmos problemáticos se suprimen usando un filtro afinado que evita distorsionar la sincronización. Las señales limpias se convierten de nuevo al dominio temporal, se fragmentan en ventanas cortas y se estandarizan para que todos los canales compartan una escala común. Esta etapa de “lavado y reconfiguración” convierte trazas caóticas en fragmentos ordenados que un algoritmo de aprendizaje puede comprender.
Permitir que las redes profundas aprendan los patrones ocultos
Sobre este preprocesamiento, el equipo probó cinco modelos relacionados de aprendizaje profundo que combinan dos tipos de redes neuronales. Las capas convolucionales actúan como pequeños detectores de patrones que se deslizan a lo largo de los canales EEG, captando estructura espacial y en el tiempo local. Capas Long Short-Term Memory (LSTM) siguen cómo evolucionan estos patrones a lo largo del tiempo, capturando el flujo de la actividad cerebral durante la palabra imaginada. Algunas versiones miran solo hacia adelante en el tiempo, mientras que una variante clave lo hace hacia adelante y hacia atrás, ofreciendo una visión más completa del ritmo de la señal. Al comparar estos diseños de red, los investigadores mostraron que usar tanto convolución como una forma bidireccional de LSTM proporciona la representación más potente del habla imaginada.
Poner el sistema a pruebas realistas
Una cuestión crucial no es solo si un modelo puede decodificar los pensamientos de personas que ya ha visto, sino si funciona con nuevos individuos. Para explorar esto, los autores usaron varias estrategias de prueba. Divisiones aleatorias simples, frecuentemente empleadas en trabajos anteriores, ofrecen una imagen muy optimista: con su tubería completa, el mejor modelo clasificó los 30 ítems imaginados con más del 99 % de precisión. Cuando aplicaron esquemas más estrictos que evitan la filtración entre segmentos temporales superpuestos de entrenamiento y prueba, el rendimiento se mantuvo alto. Lo más exigente de todo, en una prueba de “dejar-afuera-un-participante”, el sistema se entrenó con muchos voluntarios y luego se evaluó en una persona completamente nueva, con solo una pequeña muestra de calibración. Incluso allí, identificó correctamente el ítem imaginado casi cuatro veces más a menudo que un modelo competidor reciente y lo hizo con tiempos de respuesta mucho más rápidos, lo que respalda la interacción en tiempo real.
Qué significa esto para futuros dispositivos de habla silenciosa
Para un público general, la conclusión principal es que la decodificación del habla imaginada ya no es una fantasía de ciencia ficción limitada a vocabularios muy reducidos. Al limpiar agresivamente las señales EEG y combinarlas con una red profunda bidireccional inteligente, este estudio muestra que una diadema puede distinguir de forma fiable entre 30 ítems diferentes imaginados en silencio, incluso al trasladarse a nuevos usuarios. Aunque convertir pensamientos libres y de forma fluida en habla requerirá vocabularios mayores y diseños más avanzados, este trabajo aporta una base sólida: demuestra que, con el preprocesamiento y la estrategia de aprendizaje adecuados, el susurro cerebral de una palabra no pronunciada puede transformarse en una señal clara y legible por máquina.
Cita: Elwasify, F., Shaaban, E. & Abdelmoneem, R.M. EEG imagined speech neuro-signal preprocessing and deep learning classification. Sci Rep 16, 10604 (2026). https://doi.org/10.1038/s41598-026-39395-6
Palabras clave: habla imaginada, interfaz cerebro–ordenador EEG, aprendizaje profundo, preprocesamiento de señales, decodificación neural