Clear Sky Science · he
עיבוד מקדים של אותות עצביים מדמיינת דיבור ב-EEG וסיווג בלמידה עמוקה
להפוך מחשבות שקטות לדיבור אפשרי
דמיינו היכולת "לשמוע" מה אדם אומר מבלי להזיז את השפתיים כלל. עבור אנשים משותקים או שאינם יכולים לדבר, טכנולוגיה כזו יכולה להיות משנת חיים, ולהעניק להם דרך לתקשר רק באמצעות מחשבותיהם. מחקר זה עושה צעד משמעותי לעבר המטרה על ידי הצגת שיטה לקריאת מילים מדומיינות מתוך גלי מוח שנמדדו באמצעות כובע נוח ונישא. באמצעות ניקוי זהיר של האותות ושימוש בלמידה עמוקה מודרנית, המחברים מראים שניתן לזהות באופן אמין אותיות, מספרים וחפצים המיוחלים בשקט במחשבה.
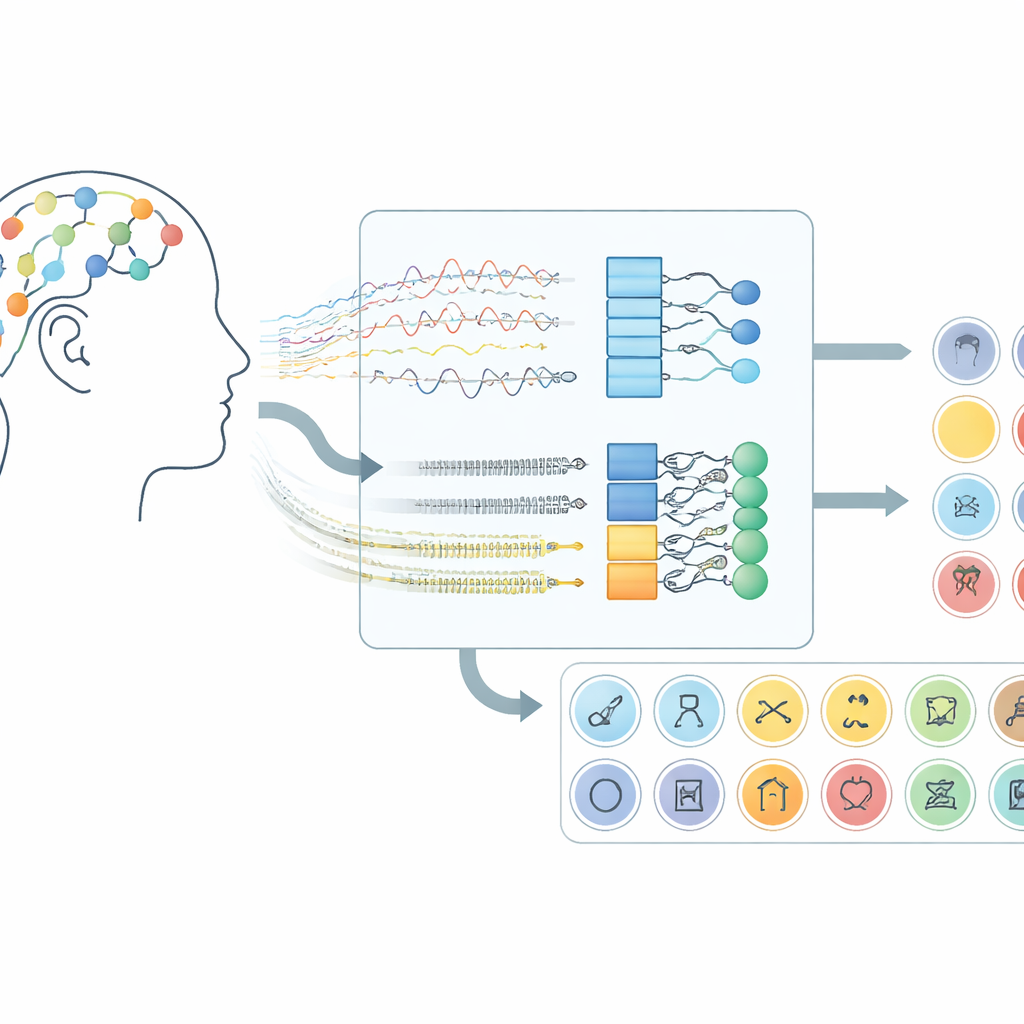
כיצד אותות המוח הופכים לערוץ תקשורת
העבודה מתמקדת בממשקי מוח־מחשב המשתמשים באלקטרואנצפלוגרפיה (EEG), טכניקה המקליטה שינויים קטנים במתח מחיישנים הממוקמים על הקרקפת. במקום לבקש מהנבדקים להזיז ידיים או לדמיין תנועות, המערכת מאזינה לפעילות המוח המתעוררת כאשר אנשים "מוללים" מילים בראשם בשקט. בערכת הנתונים שבשימוש כאן, המתנדבים דמיינו 30 פריטים שונים משלוש קבוצות: תווי האלפבית, ספרות וחפצים יומיומיים. כל ניסוי ארך עשר שניות, והאותות נלקחו מ-14 מקומות על הקרקפת באמצעות קסדה אלחוטית, דבר המדגים שניתן להפעיל את הגישה הזו באמצעות חומרה לצרכן ולא רק באמצעות מכשירים מושתלים בניתוח.
ניקוי האות לפני קריאת המחשבה
הקלטות EEG גולמיות הן מבולגנות. הן קולטות לא רק פעילות מוחית אלא גם מצמוצים, מתח בשרירי הפנים ודופק, וכן רעש חשמלי מהסביבה. המחברים תכננו צינור עיבוד מקדים בן שישה שלבים כדי להסיר כמה שיותר מהמטרד הזה תוך שמירה על הדפוסים הקשורים לדיבור מדומיין. ראשית, שיטה מתמטית מפרקת את האות לרכיבים בלתי תלויים כך שניתן להסיר באופן אוטומטי חלקים הדומים לארטיפקטים. לאחר מכן המידע מומר לתחום התדרים, שבו קוצצים קצבים מפריעים בעזרת מסנן מכויל באופן שמימנע עיוותי תזמון. האותות המנוקים מומרלים חזרה לזמן, נחתכים לחלונות קצרים וממויינים כדי שכל הערוצים ישתפו סקאלה משותפת. ה"כביסה ויצירת הצורה" המשכית של הנתונים הופכת עקבות כאוטיות לחתיכות מסודרות שהאלגוריתם הלומד יכול להבין.
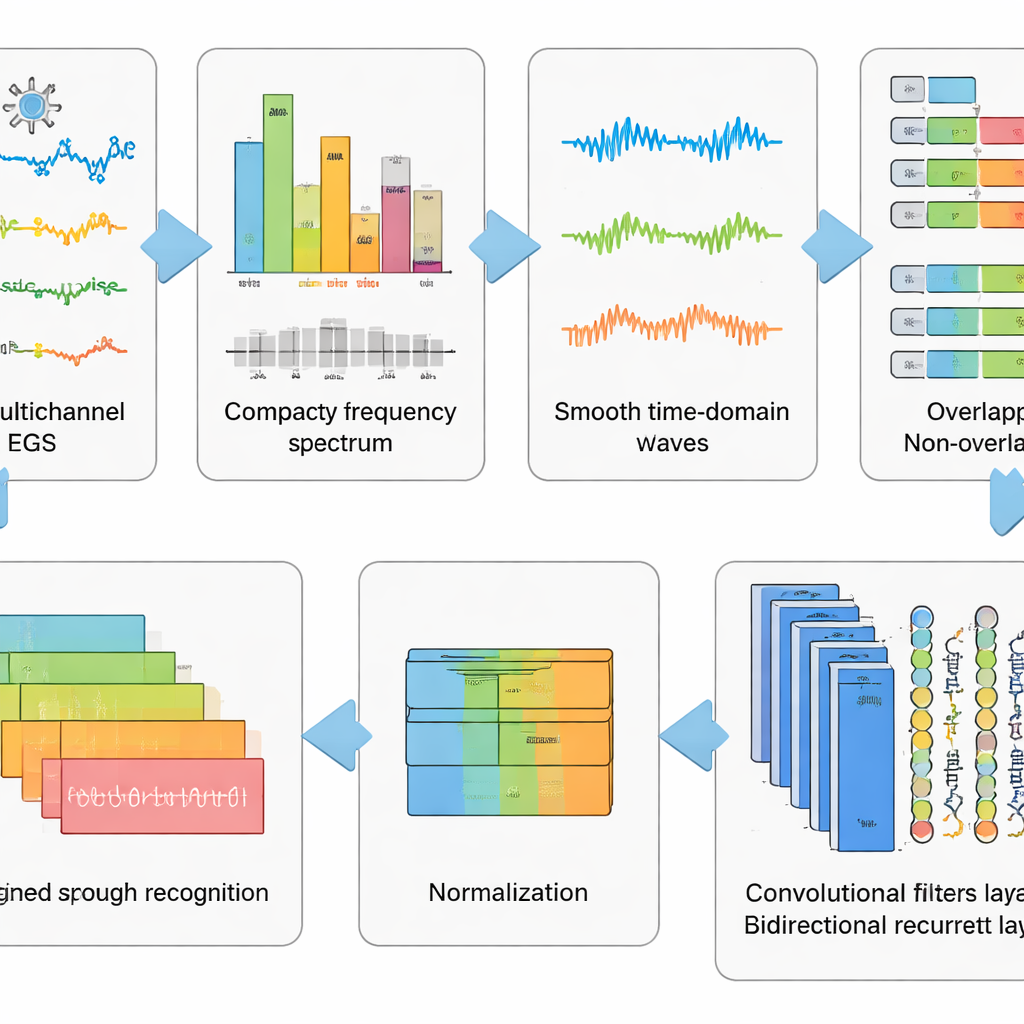
לתת לרשתות עמוקות ללמוד את הדפוסים הנסתרים
בנוסף לעיבוד המקדים, הצוות בחן חמישה מודלים של למידה עמוקה קרובים שמשלבים שני סוגי רשתות עצביות. שכבות קונבולוציה פועלות כמו גלאי דפוסים קטנים החולפים לאורך ערוצי ה-EEG, ותופסות מבנה מרחבי ומקומי בזמן. שכבות LSTM (זיכרון לטווח ארוך וקצר) עוקבות אחר התפתחות הדפוסים הללו לאורך זמן, ותופסות את רצף הפעילות המוחית במהלך המילה המדומיינת. כמה גרסאות מסתכלות רק קדימה בזמן, בעוד שגרסה מרכזית מסתכלת גם קדימה וגם אחורה, ומספקת תמונה שלמה יותר של הקצב האות. בהשוואת עיצובים אלה הראו החוקרים ששילוב קונבולוציה וצורת LSTM דו־כיוונית נותן את הייצוג החזק ביותר של דיבור מדומיין.
להעמיד את המערכת במבחנים ריאליסטיים
שאלה מרכזית היא לא רק האם מודל יכול לפענח את מחשבות אנשים שראה קודם, אלא האם הוא עובד על נבדקים חדשים. כדי לבדוק זאת, המחברים השתמשו בכמה אסטרטגיות בדיקה. החלוקות האקראיות הפשוטות, הנפוצות במחקרים קודמים, מציירות תמונה אופטימית מאוד: עם הצינור המלא שלהם, המודל הטוב ביותר סיווג את כל 30 הפריטים המדומיינים בדיוק של מעל 99%. כאשר יישמו סכמות קשוחות יותר שמונעות דליפה של מקטעי זמן חופפים בין נתוני האימון והבדיקה, הביצועים נשארו גבוהים. הקשה ביותר, במבחן "השאר-נבדק-אחד-מחוץ", המערכת אומנה על מתנדבים רבים ואז הוערכה על אדם חדש לגמרי, עם רק מדגם קליברציה קטן. גם שם היא זיהתה נכון את הפריט המדומיין כמעט פי ארבעה יותר מאשר מודל מתחרה חזק מהשנים האחרונות ועשתה זאת עם זמני תגובה הרבה יותר מהירים, תומכת באינטראקציה בזמן אמת.
מה משמעות הדבר עבור מכשירי דיבור שקט עתידיים
עבור הקורא שאינו מומחה, המסקנה העיקרית היא שפענוח דיבור מדומיין כבר אינו פנטזיה מדע בדיוני המוגבלת לאוצר מילים קטן. באמצעות ניקוי אגרסיבי של אותות ה-EEG וזיווגם עם רשת עמוקה דו־כיוונית וחכמה, מחקר זה מראה שקסדה יכולה להבחין באופן אמין בין 30 פריטים מדומיינים בשקט, אפילו כאשר עוברים למשתמשים חדשים. בעוד הפיכת מחשבות חופשיות לגמרי לדיבור שוטף תדרוש אוצר מילים גדול יותר ועיצובים מתקדמים יותר, עבודה זו מספקת בסיס איתן: היא מוכיחה שבעם עיבוד מקדים ואסטרטגיית למידה נכונים, לחישת המוח של מילה שלא הושמעה יכולה להפוך לאות ברור וקריא על ידי מכונה.
ציטוט: Elwasify, F., Shaaban, E. & Abdelmoneem, R.M. EEG imagined speech neuro-signal preprocessing and deep learning classification. Sci Rep 16, 10604 (2026). https://doi.org/10.1038/s41598-026-39395-6
מילות מפתח: דיבור מדומיין, ממשק מוח־מחשב EEG, למידה עמוקה, עיבוד מקדים של אותות, פענוח עצבי