Clear Sky Science · pt
Pré-processamento de sinais neurais de fala imaginada em EEG e classificação por deep learning
Transformando Pensamentos Silenciosos em Possível Fala
Imagine poder “ouvir” o que alguém está dizendo sem que essa pessoa mova os lábios. Para pessoas paralisadas ou incapazes de falar, essa tecnologia poderia ser transformadora, permitindo comunicação apenas por meio do pensamento. Este estudo dá um passo importante nessa direção ao mostrar como ler palavras imaginadas a partir de ondas cerebrais medidas com uma simples touca portátil. Ao limpar cuidadosamente os sinais e empregar deep learning moderno, os autores mostram que letras, números e objetos imaginados silenciosamente podem ser reconhecidos com notável confiabilidade.
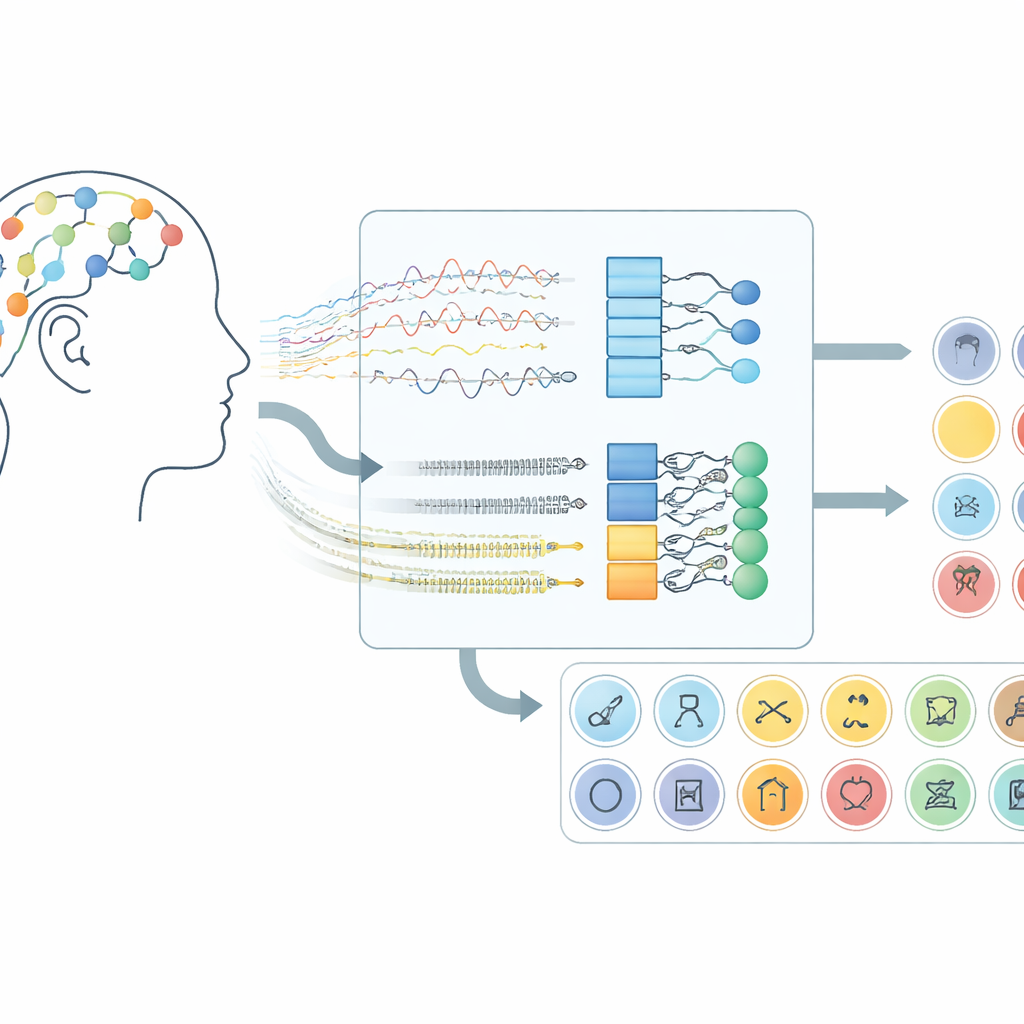
Como os Sinais Cerebrais Viram um Canal de Comunicação
O trabalho concentra-se em interfaces cérebro–computador que usam eletroencefalografia (EEG), técnica que registra pequenas variações de voltagem por sensores colocados no couro cabeludo. Em vez de pedir aos participantes que movam as mãos ou imaginem movimentos, esse sistema escuta a atividade cerebral que surge quando as pessoas “dizem” palavras silenciosamente em sua mente. No conjunto de dados usado aqui, voluntários imaginaram 30 itens diferentes de três grupos: caracteres do alfabeto, dígitos e objetos do cotidiano. Cada ensaio durou dez segundos, e sinais de 14 locais do couro cabeludo foram capturados com um fone de cabeça sem fio, demonstrando que essa abordagem pode funcionar com hardware de consumo em vez de dispositivos cirurgicamente implantados.
Limpeza do Sinal Antes de Ler o Pensamento
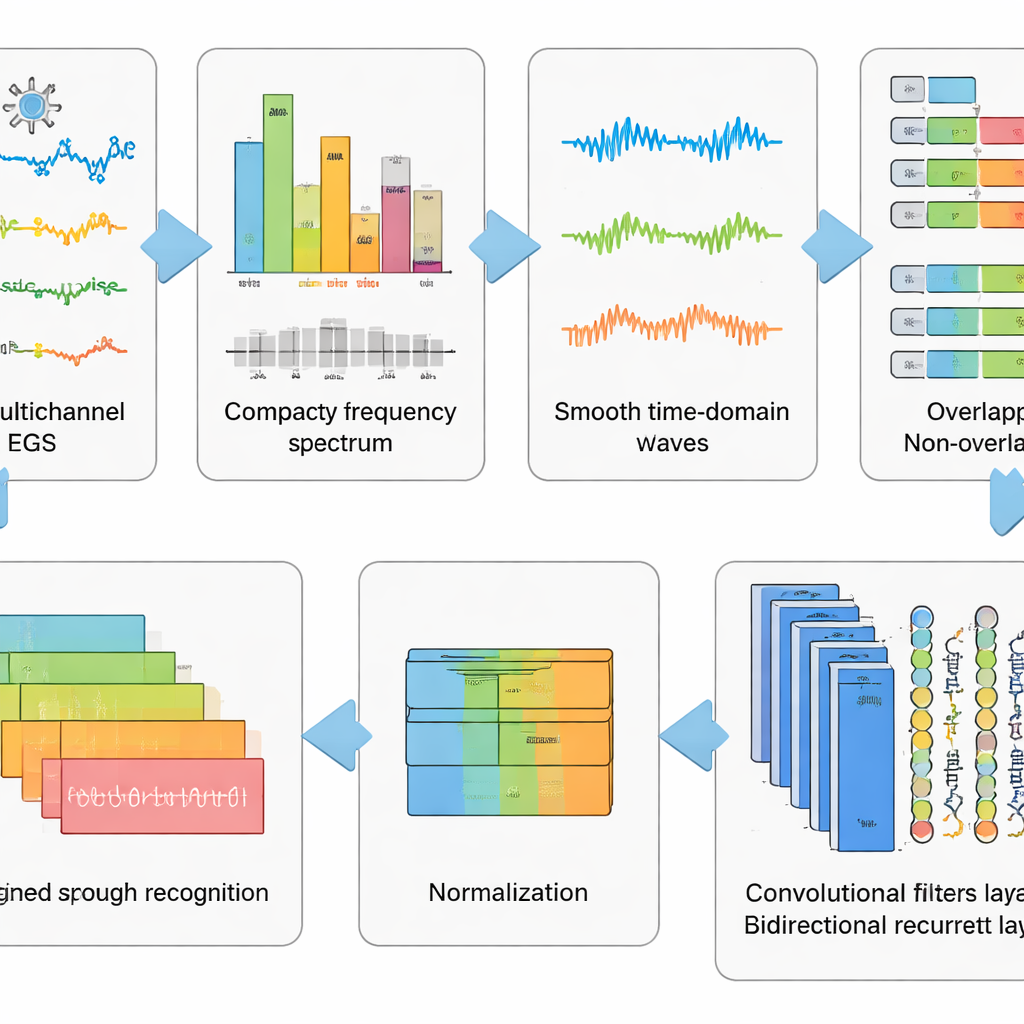
Registros brutos de EEG são confusos. Eles capturam não só a atividade cerebral, mas também piscadas, tensão muscular facial e batimentos cardíacos, além de ruído elétrico do ambiente. Os autores projetaram um pipeline de pré-processamento em seis etapas para remover o máximo possível dessa sujeira enquanto preservam os padrões ligados à fala imaginada. Primeiro, um método matemático separa o sinal em componentes independentes para que partes semelhantes a artefatos possam ser removidas automaticamente. Em seguida, os dados são convertidos para o domínio da frequência, onde certos ritmos problemáticos são suprimidos usando um filtro cuidadosamente ajustado que evita distorcer o tempo. Os sinais limpos são convertidos de volta para o domínio temporal, recortados em janelas curtas e padronizados para que todos os canais compartilhem uma mesma escala. Essa “lavagem e remodelagem” em etapas transforma traços caóticos em trechos bem comportados que um algoritmo de aprendizagem pode compreender.
Deixando Redes Profundas Aprenderem os Padrões Ocultos
Sobre esse pré-processamento, a equipe testou cinco modelos de deep learning relacionados que combinam dois tipos de redes neurais. Camadas convolucionais atuam como pequenos detectores de padrão deslizando pelos canais de EEG, captando estrutura espacial e local no tempo. Camadas Long Short-Term Memory (LSTM) então acompanham como esses padrões evoluem ao longo do tempo, capturando o fluxo de atividade cerebral durante a palavra imaginada. Algumas versões olham apenas para frente no tempo, enquanto uma variante chave olha para frente e para trás, oferecendo uma visão mais completa do ritmo do sinal. Ao comparar esses desenhos de rede, os pesquisadores mostraram que combinar convolução com uma LSTM bidirecional oferece a representação mais poderosa da fala imaginada.
Testando o Sistema em Condições Realistas
Uma questão crucial não é apenas se um modelo consegue decodificar os pensamentos de pessoas que já viu antes, mas se ele funciona em novos indivíduos. Para investigar isso, os autores usaram várias estratégias de teste. Divisões aleatórias simples, frequentemente usadas em trabalhos anteriores, pintam um quadro muito otimista: com o pipeline completo, o melhor modelo classificou os 30 itens imaginados com mais de 99% de acurácia. Quando aplicaram esquemas mais rigorosos que impedem o vazamento por sobreposição de segmentos de tempo entre treino e teste, o desempenho permaneceu alto. O mais exigente de todos, no teste “leave-one-subject-out”, o sistema foi treinado com muitos voluntários e então avaliado em uma pessoa completamente nova, com apenas uma pequena amostra de calibração. Mesmo aí, ele identificou corretamente o item imaginado quase quatro vezes mais frequentemente que um modelo concorrente recente e o fez com tempos de resposta muito mais rápidos, compatíveis com interação em tempo real.
O Que Isso Significa para Dispositivos de Fala Silenciosa no Futuro
Para um público não especializado, a principal conclusão é que a decodificação da fala imaginada não é mais uma fantasia de ficção científica limitada a vocabulários pequenos. Ao limpar agressivamente os sinais de EEG e emparelhá-los com uma rede profunda bidirecional inteligente, este estudo mostra que uma touca pode distinguir de forma confiável entre 30 itens diferentes imaginados silenciosamente, mesmo ao migrar para novos usuários. Embora transformar pensamentos livres e em grande vocabulário em fala fluida exija vocabulários maiores e projetos mais avançados, este trabalho fornece uma base sólida: prova que, com o pré-processamento e a estratégia de aprendizagem corretos, o sussurro cerebral de uma palavra não dita pode ser convertido em um sinal claro e legível por máquina.
Citação: Elwasify, F., Shaaban, E. & Abdelmoneem, R.M. EEG imagined speech neuro-signal preprocessing and deep learning classification. Sci Rep 16, 10604 (2026). https://doi.org/10.1038/s41598-026-39395-6
Palavras-chave: fala imaginada, interface cérebro–computador por EEG, deep learning, pré-processamento de sinais, decodificação neural