Clear Sky Science · pl
Wstępne przetwarzanie sygnałów EEG wyobrażonej mowy i klasyfikacja z użyciem głębokiego uczenia
Przekształcanie milczących myśli w potencjalną mowę
Wyobraź sobie, że możesz „usłyszeć”, co ktoś mówi, nawet jeśli wcale nie porusza ustami. Dla osób sparaliżowanych lub niemogących mówić taka technologia mogłaby zmienić życie, pozwalając komunikować się wyłącznie myślami. To badanie stanowi ważny krok w tym kierunku, pokazując, jak odczytywać wyobrażone słowa z fal mózgowych zmierzonych za pomocą prostego, noszonego czepka. Poprzez staranne oczyszczenie sygnałów i zastosowanie nowoczesnego głębokiego uczenia autorzy pokazują, że cicho wyobrażone litery, cyfry i przedmioty można rozpoznawać z niezwykłą niezawodnością.
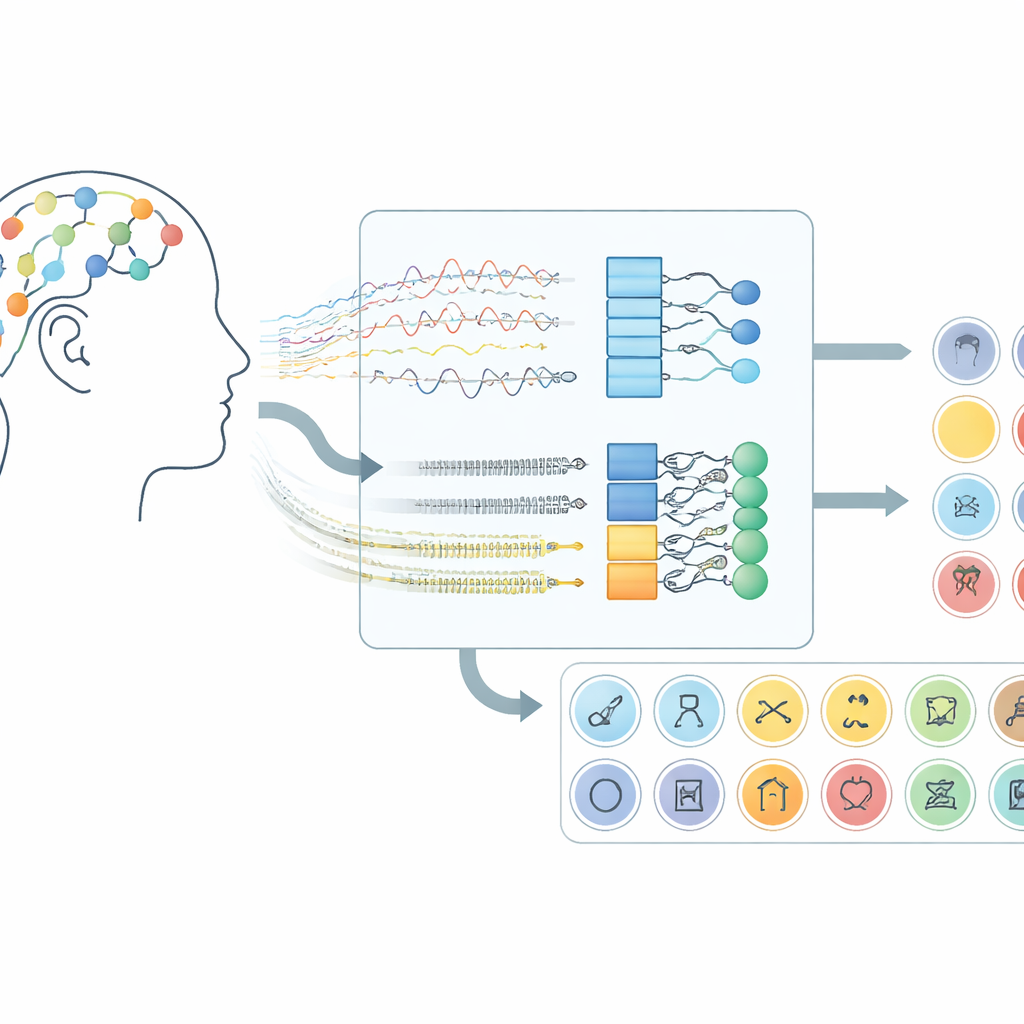
Jak sygnały mózgowe stają się kanałem komunikacji
Praca koncentruje się na interfejsach mózg–komputer wykorzystujących elektroencefalografię (EEG), technikę rejestrującą drobne zmiany napięcia z czujników umieszczonych na skórze głowy. Zamiast prosić uczestników o poruszanie rękami czy wyobrażanie sobie ruchu, system nasłuchuje aktywności mózgu pojawiającej się, gdy ludzie cicho „wypowiadają” słowa w myślach. W użytym tu zbiorze danych ochotnicy wyobrażali sobie 30 różnych elementów z trzech grup: znaki alfabetu, cyfry i przedmioty codziennego użytku. Każde zadanie trwało dziesięć sekund, a sygnały z 14 lokalizacji na skórze głowy były rejestrowane za pomocą bezprzewodowego zestawu, co pokazuje, że podejście to może działać na sprzęcie konsumenckim, a nie tylko na urządzeniach wszczepianych chirurgicznie.
Oczyszczanie sygnału przed odczytem myśli
Surowe zapisy EEG są chaotyczne. Rejestrują nie tylko aktywność mózgu, ale także mrugnięcia oczu, napięcie mięśni twarzy i rytm serca, a także zakłócenia elektryczne z otoczenia. Autorzy zaprojektowali sześciostopniowy pipeline wstępnego przetwarzania, aby usunąć jak najwięcej tego bałaganu, zachowując jednocześnie wzorce związane z wyobrażoną mową. Najpierw matematyczna metoda rozdziela sygnał na niezależne składowe, tak aby części przypominające artefakty można było automatycznie usunąć. Następnie dane są konwertowane do dziedziny częstotliwości, gdzie pewne problematyczne rytmy są tłumione przy użyciu starannie dostrojonego filtra, który nie zniekształca informacji o czasie. Oczyszczone sygnały są przekształcane z powrotem do postaci czasowej, dzielone na krótkie okna i standaryzowane, tak by wszystkie kanały miały wspólną skalę. Ta etapowa „płukanka i przekształcenie” danych zmienia chaotyczne przebiegi w uporządkowane fragmenty, które algorytm uczący się potrafi zrozumieć.
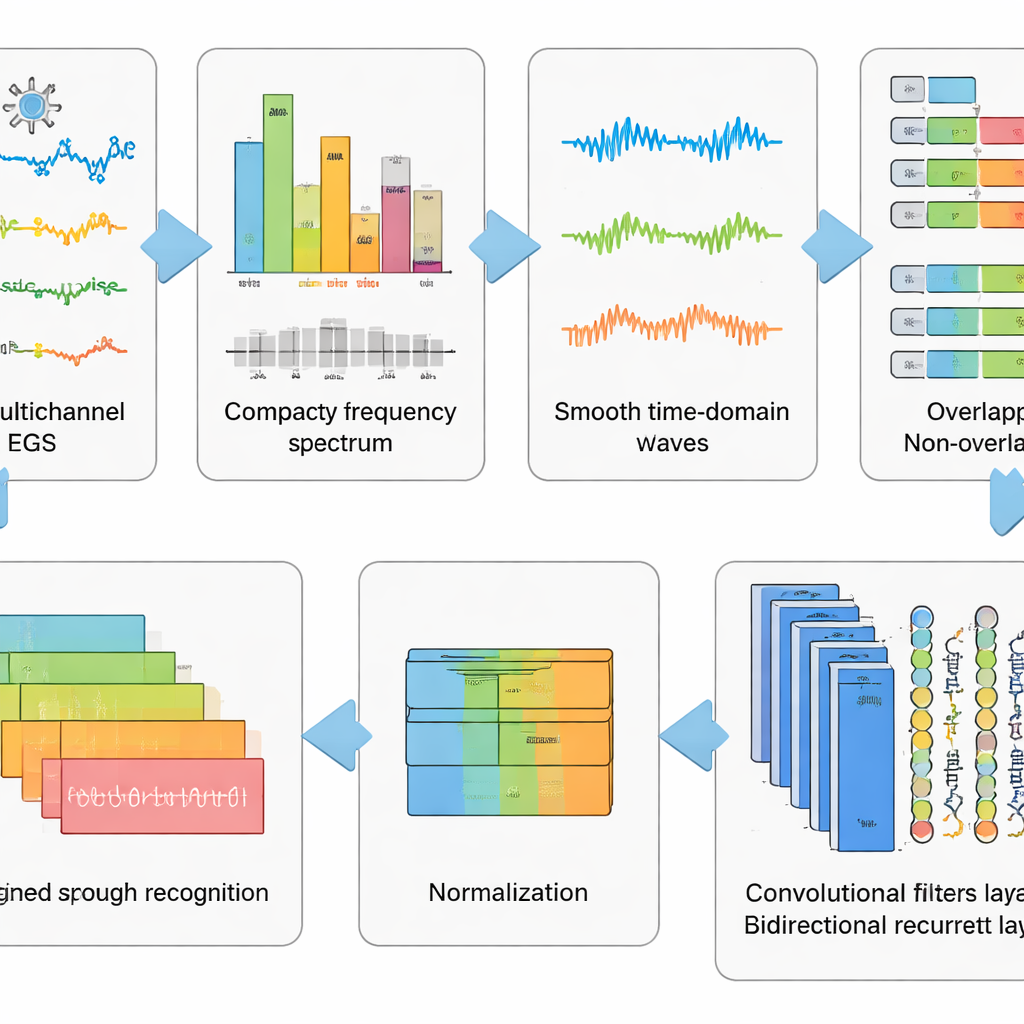
Pozwalanie głębokim sieciom uczyć się ukrytych wzorców
Na bazie tego przetwarzania zespół przetestował pięć powiązanych modeli głębokiego uczenia łączących dwa typy sieci neuronowych. Warstwy splotowe działają jak małe detektory wzorców przesuwające się wzdłuż kanałów EEG, wychwytując strukturę przestrzenną i lokalną w czasie. Warstwy typu Long Short-Term Memory (LSTM) następnie śledzą, jak te wzorce zmieniają się w czasie, rejestrując przepływ aktywności mózgowej podczas wyobrażonego słowa. Niektóre wersje patrzą tylko w przód w czasie, podczas gdy kluczowy wariant analizuje sygnał zarówno w przód, jak i w tył, dając pełniejszy obraz rytmu sygnału. Porównując te konstrukcje sieci, badacze wykazali, że połączenie splotów z dwukierunkową postacią LSTM daje najsilniejszą reprezentację wyobrażonej mowy.
Testowanie systemu w realistycznych warunkach
Kluczowe pytanie nie brzmi tylko, czy model potrafi zdekomponować myśli osób, które widział w treningu, ale czy działa też u nowych osób. Aby to zbadać, autorzy zastosowali kilka strategii testowych. Proste losowe podziały, często stosowane we wcześniejszych pracach, dają bardzo optymistyczny obraz: z pełnym pipeline’em najlepszy model sklasyfikował wszystkie 30 wyobrażonych elementów z ponad 99% dokładnością. Gdy zastosowano surowsze schematy zapobiegające przeciekowi nakładających się segmentów czasowych między danymi treningowymi i testowymi, wydajność pozostała wysoka. Najtrudniejszym testem był scenariusz „leave-one-subject-out”, w którym system trenowano na wielu ochotnikach, a następnie oceniano na zupełnie nowej osobie, dysponując tylko niewielką próbą kalibracyjną. Nawet tam poprawnie identyfikował wyobrażony element prawie cztery razy częściej niż silny, niedawny model konkurencyjny i robił to z dużo szybszym czasem reakcji, co sprzyja interakcji w czasie rzeczywistym.
Co to oznacza dla przyszłych urządzeń mowy bez dźwięku
Dla osoby niebędącej specjalistą główny wniosek jest taki, że dekodowanie wyobrażonej mowy nie jest już fantazją science fiction ograniczoną do małych, zabawkowych słowników. Poprzez agresywne oczyszczanie sygnałów EEG i połączenie ich z inteligentną, dwukierunkową siecią głęboką, badanie to pokazuje, że zestaw na głowę może wiarygodnie rozróżnić 30 różnych cicho wyobrażonych elementów, nawet przy przechodzeniu do nowych użytkowników. Choć przekształcenie pełnych, swobodnych myśli w płynną mowę będzie wymagać większych słowników i bardziej zaawansowanych rozwiązań, praca ta dostarcza solidnych podstaw: dowodzi, że przy odpowiednim przetwarzaniu wstępnym i strategii uczenia szept mózgu niezamówionego słowa może zostać zamieniony w wyraźny, czytelny dla maszyn sygnał.
Cytowanie: Elwasify, F., Shaaban, E. & Abdelmoneem, R.M. EEG imagined speech neuro-signal preprocessing and deep learning classification. Sci Rep 16, 10604 (2026). https://doi.org/10.1038/s41598-026-39395-6
Słowa kluczowe: wyobrażona mowa, interfejs mózg–komputer EEG, głębokie uczenie, przetwarzanie sygnału, dekodowanie neuronowe