Clear Sky Science · nl
EEG-voorstellingsspraak neurosignaalvoorbewerking en deep learning-classificatie
Stiltegedachten omzetten in mogelijke spraak
Stel je voor dat je kunt “horen” wat iemand zegt zonder dat diegene zijn of haar lippen beweegt. Voor mensen die verlamd zijn of niet kunnen spreken, zou zo’n technologie levensveranderend kunnen zijn en hen in staat stellen te communiceren met alleen hun gedachten. Deze studie zet een belangrijke stap richting dat doel door te laten zien hoe men voorgestelde woorden kan aflezen uit hersengolven gemeten met een eenvoudige, draagbare cap. Door de signalen zorgvuldig op te schonen en moderne deep learning toe te passen, tonen de onderzoekers aan dat stil voorgestelde letters, cijfers en objecten met opmerkelijke betrouwbaarheid kunnen worden herkend.
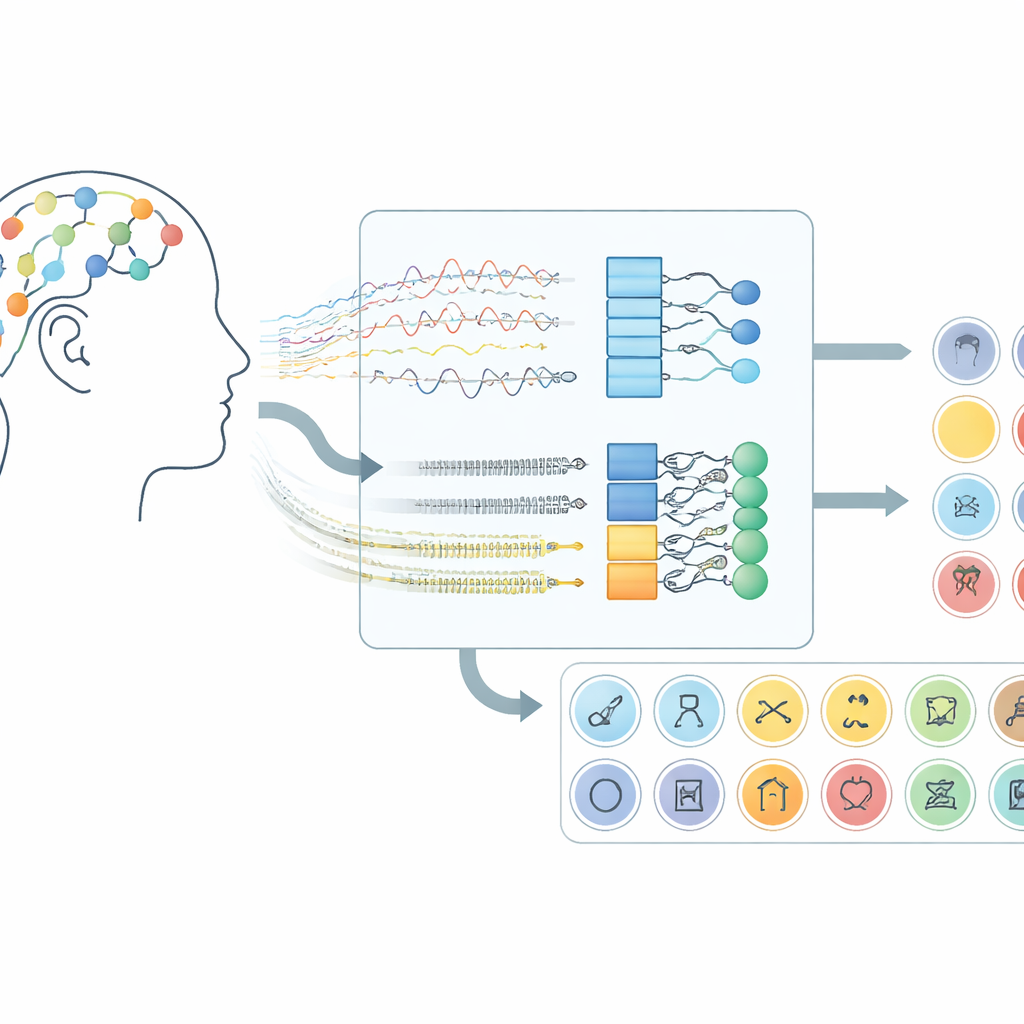
Hoe hersensignalen een communicatiekanaal worden
Het werk richt zich op hersen-computerinterfaces die elektro-encefalografie (EEG) gebruiken, een techniek die kleine spanningsveranderingen registreert met sensoren op de hoofdhuid. In plaats van deelnemers te vragen hun handen te bewegen of bewegingen voor te stellen, luistert dit systeem naar de hersenactiviteit die optreedt wanneer mensen stil “woorden” in hun gedachten uitspreken. In de hier gebruikte dataset stelden vrijwilligers zich 30 verschillende items voor uit drie groepen: alfabettekens, cijfers en alledaagse voorwerpen. Elke proef duurde tien seconden en signalen van 14 op de hoofdhuid geplaatste locaties werden vastgelegd met een draadloze headset, wat aantoont dat deze aanpak kan werken met consumentenhardware in plaats van chirurgisch geïmplanteerde apparaten.
Het signaal reinigen voordat je de gedachte leest
Ruwe EEG-opnames zijn rommelig. Ze vangen niet alleen hersenactiviteit, maar ook oogknipperingen, spanning in gelaatsspieren en de hartslag, samen met elektrische ruis uit de omgeving. De auteurs ontwierpen een zes-stappen voorbewerkingspipeline om zoveel mogelijk van deze rommel te verwijderen terwijl de patronen die met voorgestelde spraak samenhangen behouden blijven. Eerst scheidt een wiskundige methode het signaal in onafhankelijke componenten zodat artefactachtige delen automatisch kunnen worden verwijderd. Daarna worden de gegevens naar het frequentiedomein geconverteerd, waar bepaalde storende ritmes worden onderdrukt met een zorgvuldig afgestelde filter die timingvervorming vermijdt. De gereinigde signalen worden teruggezet naar de tijdsdomein, in korte vensters gehakt en gestandaardiseerd zodat alle kanalen een gemeenschappelijke schaal delen. Deze gefaseerde “wassen en hervormen” van de data verandert chaotische sporen in goedgedisciplineerde fragmenten die een leeralgoritme kan interpreteren.
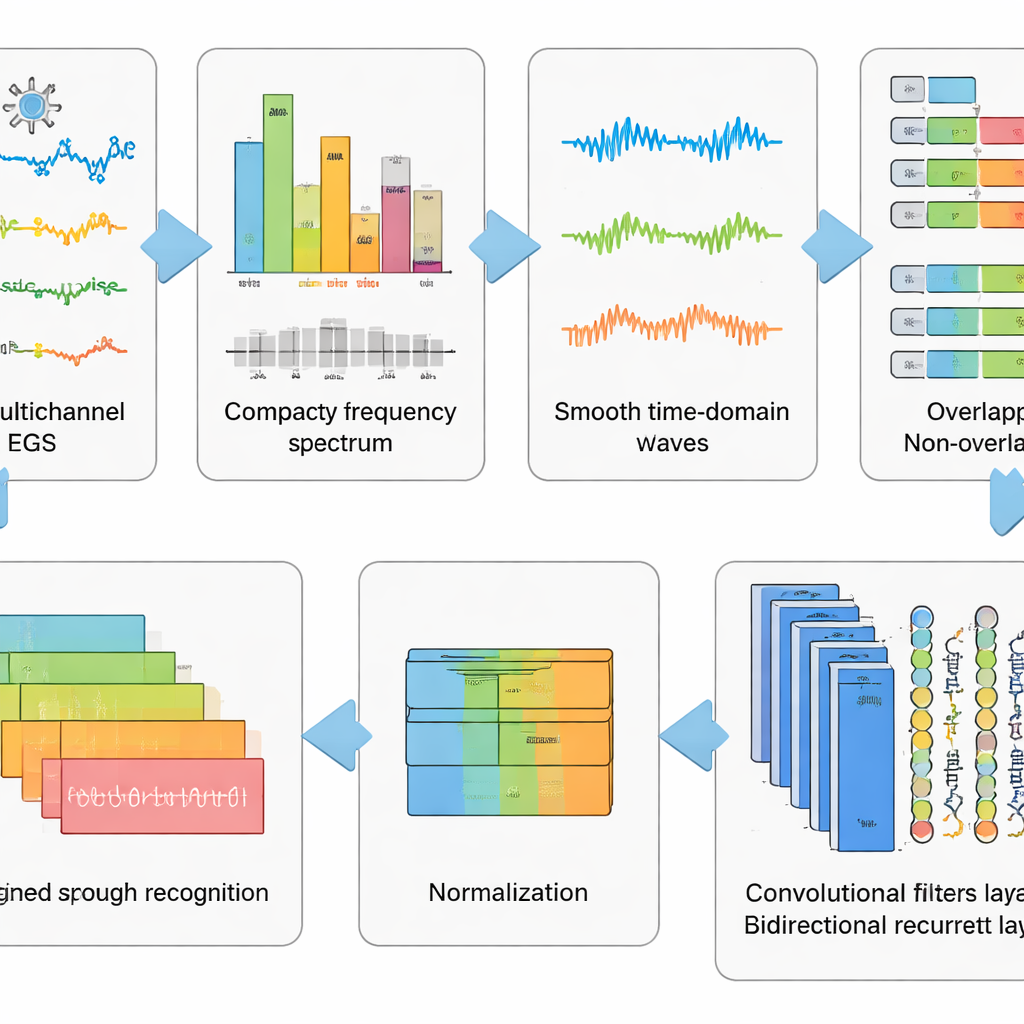
Diepe netwerken laten de verborgen patronen leren
Bovenop deze voorbewerking testte het team vijf verwante deep learning-modellen die twee typen neurale netwerken combineren. Convolutionele lagen werken als kleine patroondetectoren die langs de EEG-kanalen schuiven en ruimtelijke en lokale-tijdstructuur oppikken. Long Short-Term Memory (LSTM)-lagen volgen vervolgens hoe deze patronen in de tijd evolueren en leggen de stroom van hersenactiviteit tijdens het voorgestelde woord vast. Sommige versies kijken alleen vooruit in de tijd, terwijl een belangrijke variant zowel vooruit als achteruit kijkt, wat een vollediger beeld van het ritme in het signaal geeft. Door deze netwerkontwerpen te vergelijken, lieten de onderzoekers zien dat het combineren van convolutie en een bidirectionele vorm van LSTM de krachtigste representatie van voorgestelde spraak oplevert.
Het systeem realistisch testen
Een cruciale vraag is niet alleen of een model de gedachten van personen die het eerder heeft gezien kan decoderen, maar of het werkt bij nieuwe individuen. Om dit te onderzoeken gebruikten de auteurs meerdere teststrategieën. Eenvoudige willekeurige splitsingen, vaak gebruikt in eerder werk, schetsen een zeer optimistisch beeld: met hun volledige pipeline classificeerde het beste model alle 30 voorgestelde items met meer dan 99% nauwkeurigheid. Wanneer ze striktere schema’s toepasten die voorkomen dat overlappende tijdsegmenten tussen trainings- en testgegevens lekken, bleef de prestatie hoog. Het meest veeleisend was de "leave-one-subject-out"-test, waarbij het systeem werd getraind op veel vrijwilligers en vervolgens geëvalueerd op een volledig nieuwe persoon, met slechts een kleine kalibratiemonster. Zelfs daar identificeerde het bijna vier keer zo vaak het voorgestelde item als een sterke recente concurrerende model en deed dat met veel snellere reactietijden, wat real-time interactie ondersteunt.
Wat dit betekent voor toekomstige stille spraakapparaten
Voor de niet-specialist is de belangrijkste conclusie dat decodering van voorgestelde spraak niet langer een sciencefictionfantasie is die beperkt blijft tot kleine oefenwoordenschatten. Door EEG-signalen agressief te reinigen en ze te koppelen aan een slim, bidirectioneel diep netwerk, toont deze studie aan dat een headset betrouwbaar kan onderscheiden tussen 30 verschillende stil voorgestelde items, zelfs bij nieuwe gebruikers. Hoewel het omzetten van volledige vrije-vormgedachten naar vloeiende spraak grotere woordenschatten en geavanceerdere ontwerpen zal vereisen, biedt dit werk een solide basis: het bewijst dat, met de juiste voorbewerking en leermethode, het gefluister van een onuitgesproken woord in de hersenen kan worden omgezet in een duidelijk, machine-leesbaar signaal.
Bronvermelding: Elwasify, F., Shaaban, E. & Abdelmoneem, R.M. EEG imagined speech neuro-signal preprocessing and deep learning classification. Sci Rep 16, 10604 (2026). https://doi.org/10.1038/s41598-026-39395-6
Trefwoorden: voorstellingsspraak, EEG hersen-computerinterface, deep learning, signaalvoorbewerking, neurale decodering