Clear Sky Science · en
EEG imagined speech neuro-signal preprocessing and deep learning classification
Turning Silent Thoughts into Possible Speech
Imagine being able to “hear” what someone is saying without them moving their lips at all. For people who are paralyzed or unable to speak, such a technology could be life-changing, allowing them to communicate using only their thoughts. This study takes a major step toward that goal by showing how to read imagined words from brain waves measured with a simple, wearable cap. By carefully cleaning up the signals and using modern deep learning, the authors show that silently imagined letters, numbers, and objects can be recognized with remarkable reliability.
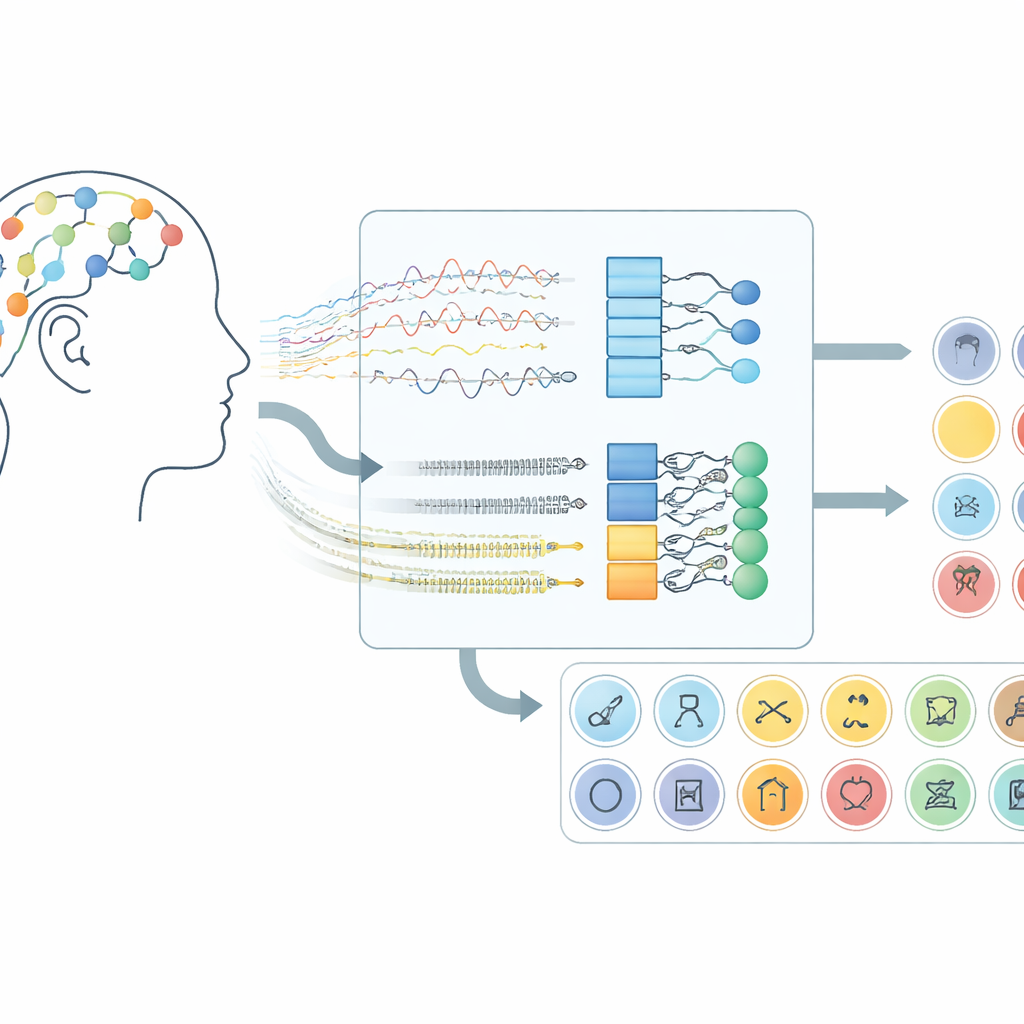
How Brain Signals Become a Communication Channel
The work focuses on brain–computer interfaces that use electroencephalography (EEG), a technique that records tiny voltage changes from sensors placed on the scalp. Instead of asking participants to move their hands or imagine motions, this system listens for the brain activity that appears when people silently “say” words in their mind. In the dataset used here, volunteers imagined 30 different items from three groups: alphabet characters, digits, and everyday objects. Each trial lasted ten seconds, and signals from 14 scalp locations were captured using a wireless headset, demonstrating that this approach can work with consumer-grade hardware rather than surgically implanted devices.
Cleaning the Signal Before Reading the Thought
Raw EEG recordings are messy. They capture not only brain activity but also eye blinks, facial muscle tension, and the heartbeat, along with electrical noise from the environment. The authors designed a six-step preprocessing pipeline to strip away as much of this clutter as possible while keeping the patterns linked to imagined speech. First, a mathematical method separates the signal into independent components so that artifact-like parts can be automatically removed. Then the data are converted into the frequency domain, where certain troublesome rhythms are suppressed using a carefully tuned filter that avoids distorting timing. The cleaned signals are converted back into time, chopped into short windows, and standardized so that all channels share a common scale. This staged “wash and reshape” of the data turns chaotic traces into well-behaved snippets that a learning algorithm can understand.
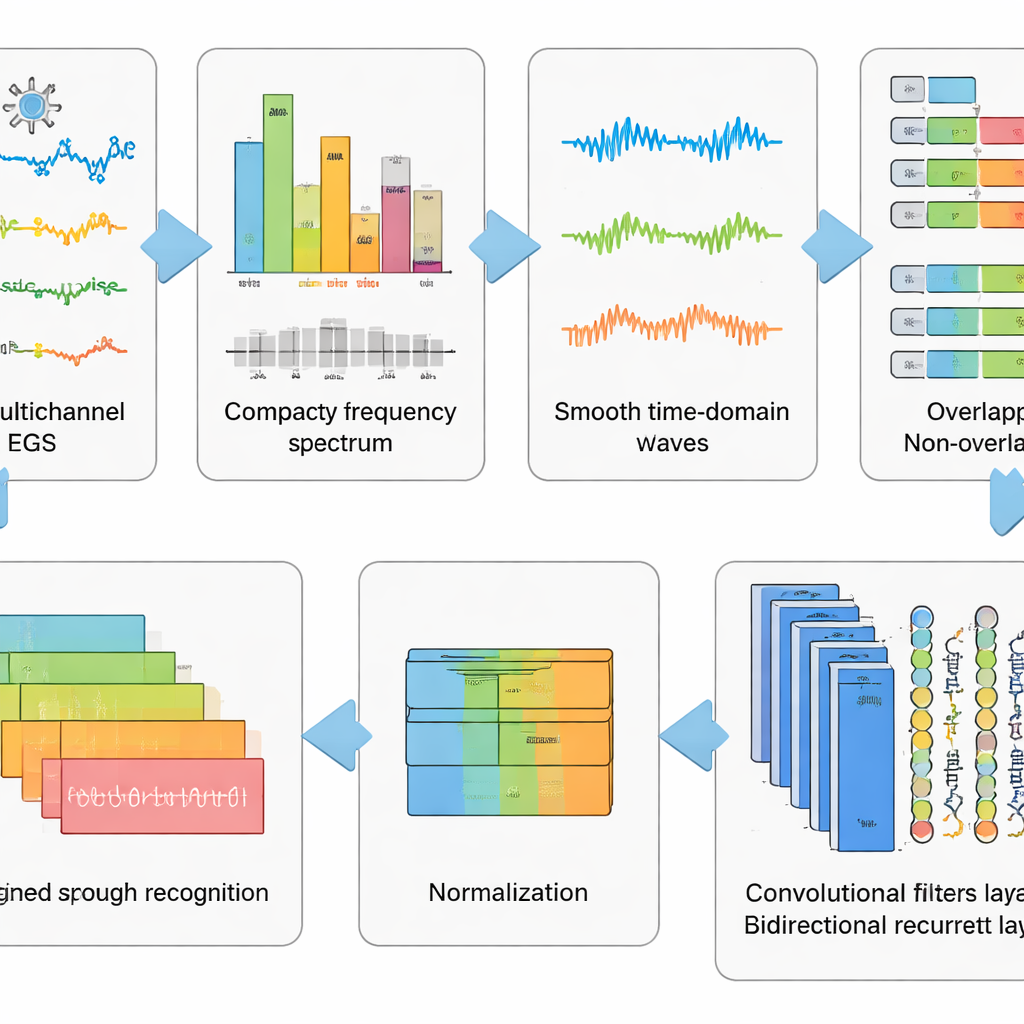
Letting Deep Networks Learn the Hidden Patterns
On top of this preprocessing, the team tested five related deep learning models that combine two types of neural networks. Convolutional layers act like small pattern detectors sliding along the EEG channels, picking up spatial and local-time structure. Long Short-Term Memory (LSTM) layers then track how these patterns evolve across time, capturing the flow of brain activity during the imagined word. Some versions look only forward in time, while a key variant looks both forward and backward, giving a more complete view of the signal’s rhythm. By comparing these network designs, the researchers showed that using both convolution and a bidirectional form of LSTM gives the most powerful representation of imagined speech.
Putting the System to Realistic Tests
A crucial question is not just whether a model can decode the thoughts of people it has seen before, but whether it works on new individuals. To probe this, the authors used several testing strategies. Simple random splits, often used in past work, paint a very optimistic picture: with their full pipeline, the best model classified all 30 imagined items with more than 99% accuracy. When they applied stricter schemes that prevent overlapping time segments from leaking between training and testing data, performance stayed high. Most demanding of all, in a “leave-one-subject-out” test, the system was trained on many volunteers and then evaluated on a completely new person, with only a small calibration sample. Even there, it correctly identified the imagined item nearly four times as often as a strong recent competitor model and did so with much faster response times, supporting real-time interaction.
What This Means for Future Silent Speech Devices
For a non-specialist, the main takeaway is that imagined speech decoding is no longer a science-fiction fantasy limited to small toy vocabularies. By aggressively cleaning the EEG signals and pairing them with a smart, bidirectional deep network, this study shows that a headset can reliably distinguish among 30 different silently imagined items, even when moving to new users. While turning full free-form thoughts into fluid speech will require larger vocabularies and more advanced designs, this work provides a solid foundation: it proves that, with the right preprocessing and learning strategy, the brain’s whisper of an unspoken word can be turned into a clear, machine-readable signal.
Citation: Elwasify, F., Shaaban, E. & Abdelmoneem, R.M. EEG imagined speech neuro-signal preprocessing and deep learning classification. Sci Rep 16, 10604 (2026). https://doi.org/10.1038/s41598-026-39395-6
Keywords: imagined speech, EEG brain–computer interface, deep learning, signal preprocessing, neural decoding