Clear Sky Science · it
Preprocessamento dei neuro-segnali EEG del linguaggio immaginato e classificazione tramite deep learning
Trasformare i pensieri silenziosi in possibile linguaggio
Immagina di riuscire a “sentire” ciò che una persona sta dicendo senza che muova le labbra. Per chi è paralizzato o incapace di parlare, una tecnologia del genere potrebbe cambiare la vita, permettendo di comunicare usando solo il pensiero. Questo studio compie un passo importante verso quell’obiettivo mostrando come leggere parole immaginate dalle onde cerebrali misurate con un semplice copricapo indossabile. Pulendo accuratamente i segnali e applicando moderne reti neurali profonde, gli autori dimostrano che lettere, numeri e oggetti immaginati in modo silenzioso possono essere riconosciuti con notevole affidabilità.
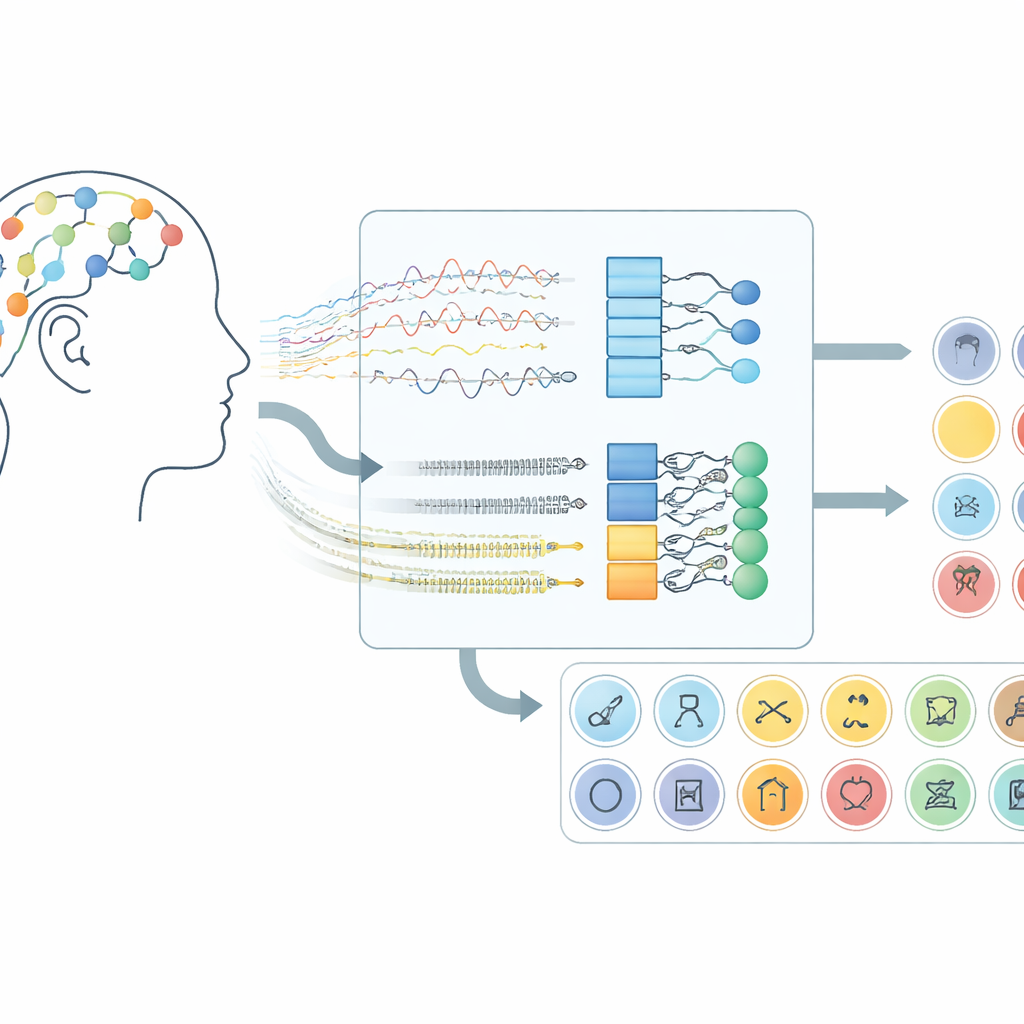
Come i segnali cerebrali diventano un canale di comunicazione
Il lavoro si concentra sulle interfacce cervello–computer che impiegano l’elettroencefalografia (EEG), una tecnica che registra piccole variazioni di tensione tramite sensori posti sul cuoio capelluto. Invece di chiedere ai partecipanti di muovere le mani o immaginare movimenti, questo sistema ascolta l’attività cerebrale che compare quando le persone “dicono” parole silenziosamente nella loro mente. Nel dataset utilizzato qui, i volontari hanno immaginato 30 elementi diversi appartenenti a tre gruppi: caratteri alfabetici, cifre e oggetti di uso quotidiano. Ogni prova durava dieci secondi e i segnali da 14 posizioni sul cuoio capelluto sono stati acquisiti con un casco wireless, dimostrando che questo approccio può funzionare con hardware di consumo anziché dispositivi impiantati chirurgicamente.
Pulire il segnale prima di leggere il pensiero
Le registrazioni EEG grezze sono caotiche. Catturano non solo l’attività cerebrale ma anche i battiti di ciglia, la tensione dei muscoli facciali e il battito cardiaco, oltre al rumore elettrico ambientale. Gli autori hanno progettato una pipeline di preprocessamento in sei fasi per rimuovere il più possibile questo rumore mantenendo i pattern legati al linguaggio immaginato. Per prima cosa, un metodo matematico separa il segnale in componenti indipendenti in modo che le parti simili ad artefatti possano essere rimosse automaticamente. Poi i dati vengono convertiti nel dominio delle frequenze, dove certi ritmi disturbanti sono soppressi tramite un filtro accuratamente tarato che evita di deformare la temporizzazione. I segnali ripuliti sono riconvertiti nel dominio del tempo, suddivisi in finestre brevi e standardizzati affinché tutti i canali condividano una scala comune. Questa operazione a tappe di “lavaggio e rimodellamento” trasforma tracciati caotici in frammenti ordinati che un algoritmo di apprendimento può interpretare.
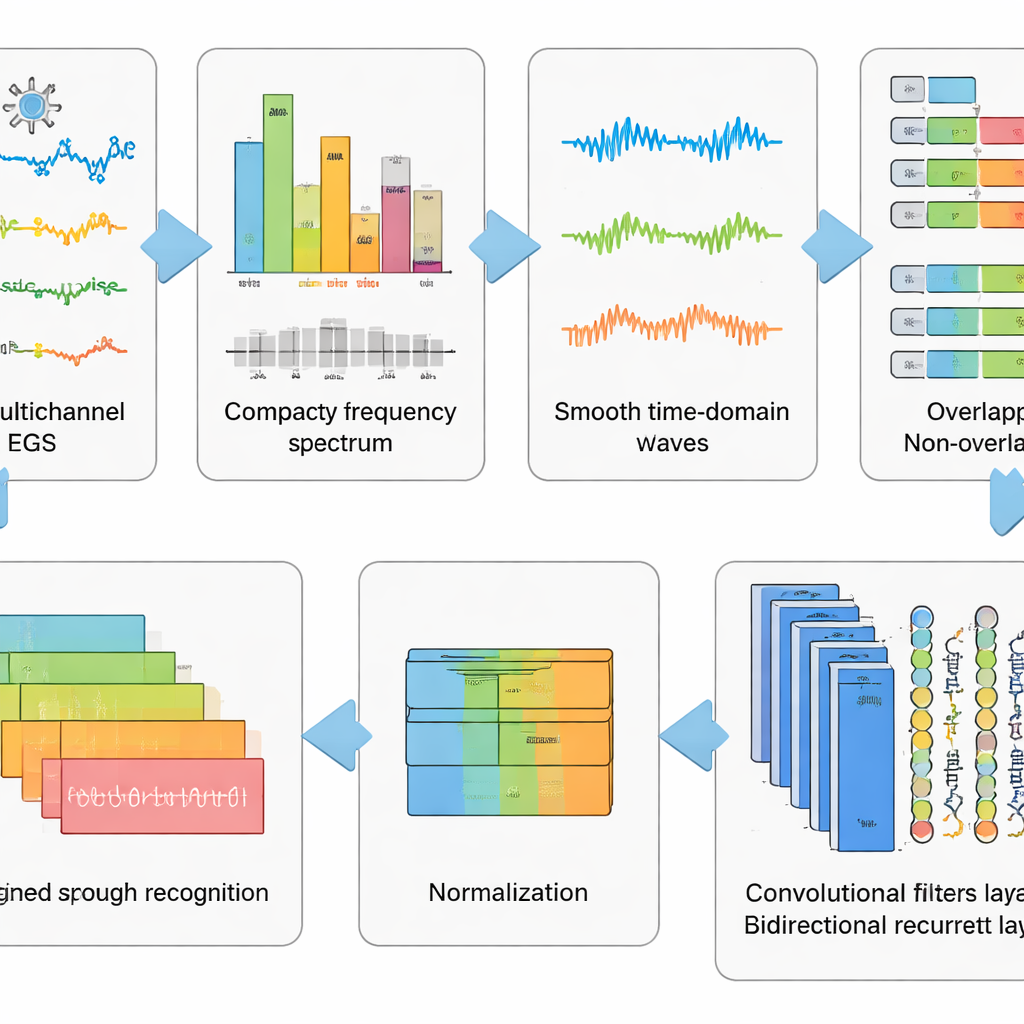
Lasciare che le reti profonde apprendano i pattern nascosti
Sopra questo preprocessamento, il team ha testato cinque modelli di deep learning correlati che combinano due tipi di reti neurali. Gli strati convolutional agiscono come piccoli rivelatori di pattern che scorrono lungo i canali EEG, cogliendo strutture spaziali e temporali locali. Gli strati Long Short-Term Memory (LSTM) seguono quindi l’evoluzione di questi pattern nel tempo, catturando il flusso dell’attività cerebrale durante la parola immaginata. Alcune versioni guardano solo in avanti nel tempo, mentre una variante chiave guarda sia avanti sia indietro, offrendo una visione più completa del ritmo del segnale. Confrontando questi progetti di rete, i ricercatori hanno mostrato che l’uso combinato di convoluzione e di una LSTM bidirezionale fornisce la rappresentazione più efficace del linguaggio immaginato.
Mettere il sistema alla prova in scenari realistici
Una domanda cruciale non è solo se un modello può decodificare i pensieri di persone già viste durante l’addestramento, ma se funziona su individui nuovi. Per verificarlo, gli autori hanno usato diverse strategie di test. Suddivisioni casuali semplici, spesso impiegate in lavori passati, dipingono un quadro molto ottimistico: con la pipeline completa, il miglior modello ha classificato tutti i 30 elementi immaginati con oltre il 99% di accuratezza. Quando hanno applicato schemi più rigorosi che impediscono la contaminazione tra segmenti temporali sovrapposti di addestramento e test, le prestazioni sono rimaste elevate. La prova più impegnativa, un test “leave-one-subject-out”, ha visto il sistema addestrato su molti volontari e poi valutato su una persona completamente nuova, con solo un piccolo campione di calibrazione. Anche in quel caso, il modello ha identificato correttamente l’elemento immaginato quasi quattro volte più spesso rispetto a un recente modello concorrente di alto livello e lo ha fatto con tempi di risposta molto più rapidi, a supporto dell’interazione in tempo reale.
Cosa significa questo per i futuri dispositivi di linguaggio silenzioso
Per un non specialista, la conclusione principale è che la decodifica del linguaggio immaginato non è più una fantasia di fantascienza limitata a vocabolari ridotti. Pulendo aggressivamente i segnali EEG e abbinandoli a una rete profonda bidirezionale intelligente, questo studio dimostra che un casco può distinguere in modo affidabile tra 30 diversi elementi immaginati silenziosamente, anche passando a nuovi utenti. Sebbene trasformare pensieri completamente liberi in linguaggio fluido richiederà vocabolari più ampi e soluzioni più avanzate, questo lavoro fornisce una base solida: dimostra che, con il giusto preprocessamento e una strategia di apprendimento adeguata, il sussurro cerebrale di una parola non detta può essere trasformato in un segnale chiaro e leggibile dalla macchina.
Citazione: Elwasify, F., Shaaban, E. & Abdelmoneem, R.M. EEG imagined speech neuro-signal preprocessing and deep learning classification. Sci Rep 16, 10604 (2026). https://doi.org/10.1038/s41598-026-39395-6
Parole chiave: linguaggio immaginato, interfaccia cervello-computer EEG, deep learning, preprocessamento del segnale, decodifica neurale