Clear Sky Science · sv
Kritisk utvärdering av modeller för att förutsäga läkemedelsrespons med DrEval
Varför smartare tester av cancerläkemedel är viktiga
När läkare väljer cancerläkemedel förlitar de sig ofta på breda kategorier som tumörtyp och ett fåtal genetiska markörer. Under det senaste decenniet har forskare börjat testa hundratals läkemedel på hundratals laboratorieodlade cancercellinjer samtidigt som de mäter varje cellinjens gener och andra molekylära egenskaper. Många datormodeller påstår sig kunna förutsäga vilka läkemedel som kommer att fungera baserat på dessa data. Den här artikeln granskar dessa påståenden noggrant och presenterar DrEval, ett nytt utvärderingsverktyg som testar hur väl sådana modeller faktiskt presterar i situationer som liknar verkliga medicinska beslut. 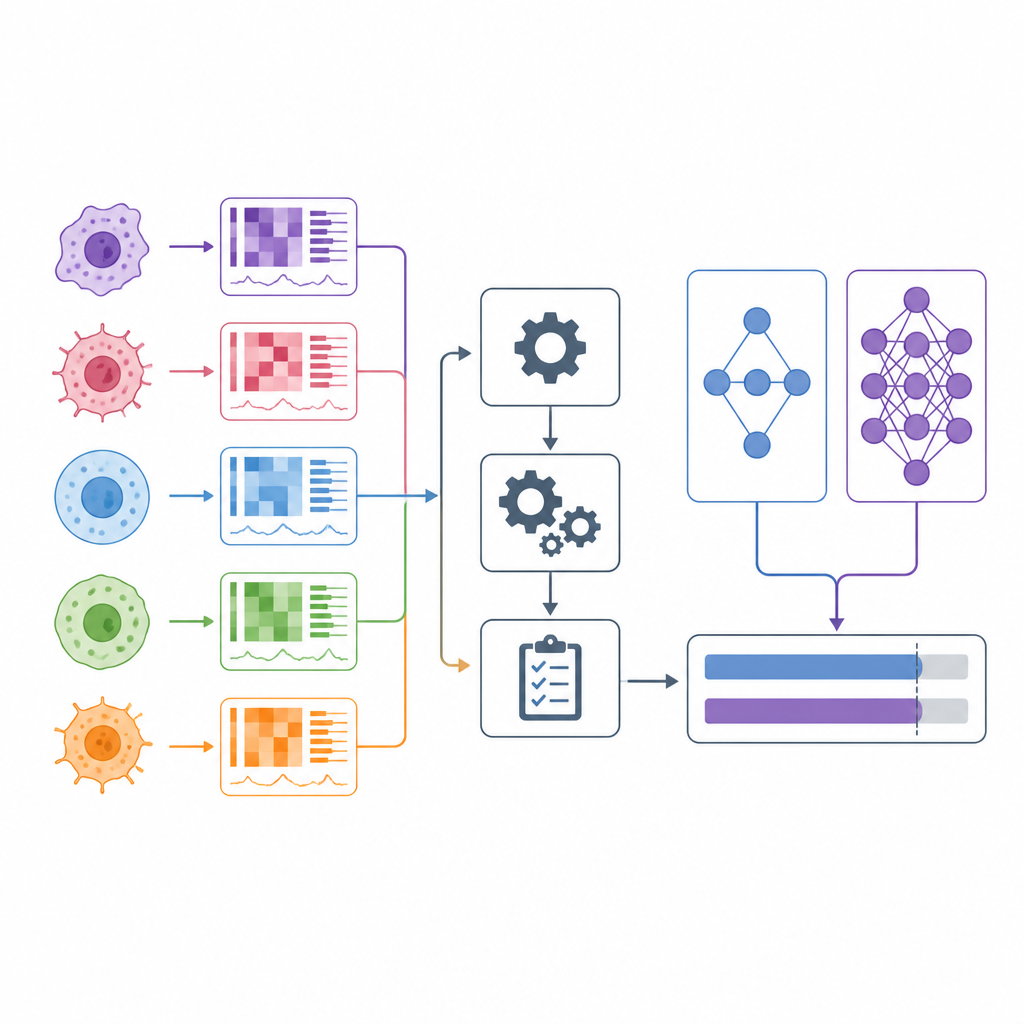
Hur datorer försöker gissa läkemedelssuccé
Modeller för förutsägelse av läkemedelsrespons lär sig från stora screeningsprojekt där cancercellinjer utsätts för många läkemedel vid olika doser och deras överlevnad mäts. Forskare matar varje modell med detaljerade molekylära profiler av cellinjerna och olika beskrivningar av läkemedlen, och ber den sedan förutsäga standardiserade sammanfattningsmått för hur starkt varje läkemedel hämmar celltillväxt. Vissa angreppssätt tränar en modell per läkemedel, medan andra tränar en enda modell över många läkemedel i förhoppningen att den även ska kunna uppskatta responser för nya läkemedel. På papperet rapporterar dessa metoder ofta imponerande noggrannhetstal, vilket ger intrycket att personlig cancerbehandling kan vara inom räckhåll.
Dolda fallgropar i nuvarande utvärderingar
Författarna visar att dessa optimistiska resultat ofta beror på hur data delas upp och poängsätts, snarare än på verklig insikt i cancerbiologi. Om samma cellinje eller läkemedel förekommer i både tränings- och testuppsättningen kan modellen enkelt memorera typiskt beteende istället för att lära sig djupare mönster. Eftersom olika läkemedel verkar inom mycket olika dosområden kan en modell som bara memorerar genomsnittlig respons per läkemedel redan förklara mycket av variationen i data. Detta skapar en statistisk illusion där den globala noggrannheten ser hög ut, även om modellen misslyckas med att skilja vilka specifika cellinjer som är mer eller mindre känsliga för ett visst läkemedel.
Vad DrEval gör annorlunda
DrEval är ett öppet benchmarkingramverk som standardiserar hur modeller för läkemedelsrespons testas. Det tillhandahåller harmoniserade dataset, noggrann datarensning och flera realistiska testsituationer som speglar vanliga mål: att förutsäga responser för nya patienter (nya cellinjer), för nya cancertyper (nya vävnader) eller för helt nya läkemedel. Det inkluderar också enkla baslinjemetoder, såsom en prediktor som bara använder genomsnittseffekterna för varje läkemedel och cellinje, samt träd-baserade modeller som är mycket enklare att träna än djupa neurala nätverk. DrEval kör alla modeller under samma korsvaliderings- och finjusteringsschema och rapporterar sedan resultat med mått som tar bort den vilseledande påverkan från genomsnittliga läkemedels- och cellinjeeffekter. 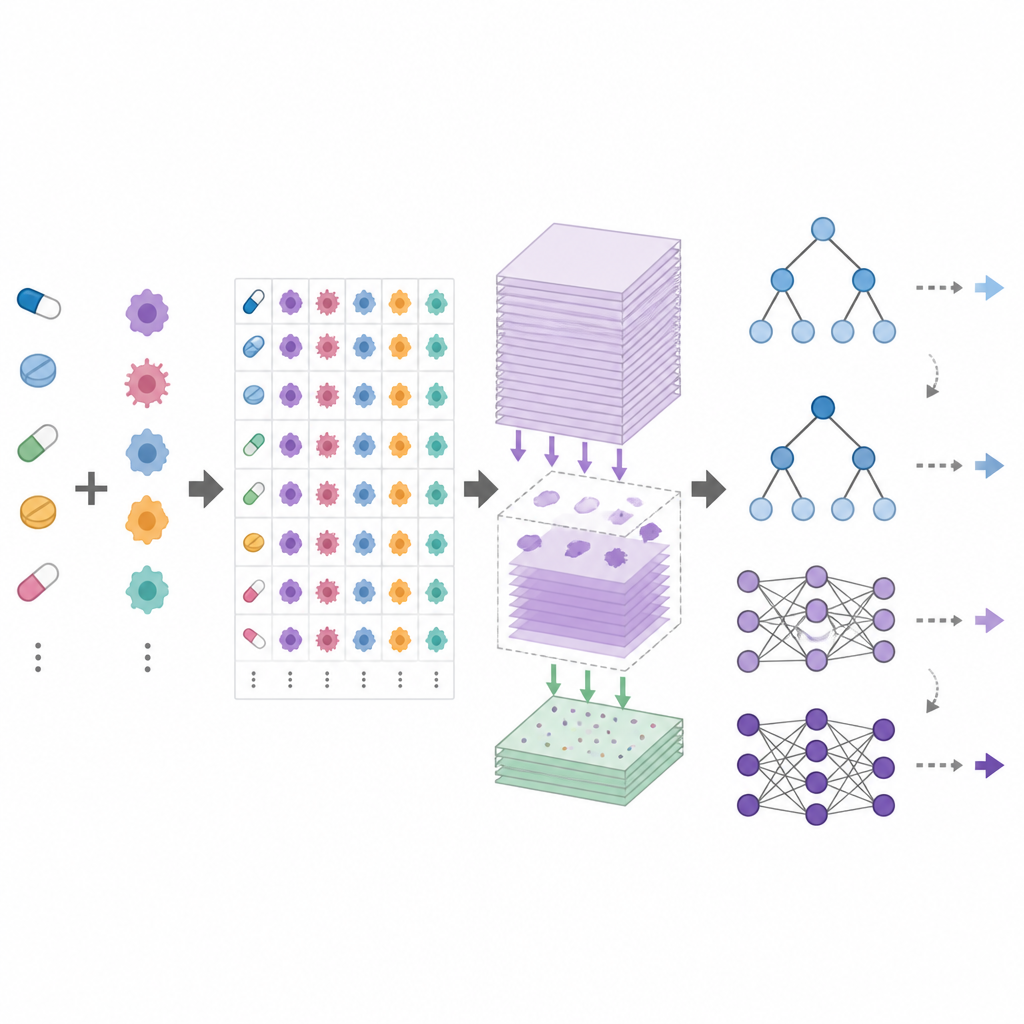
Vad testen avslöjar om dagens modeller
När författarna testade ett brett spektrum av moderna modeller med DrEval fann de att många knappt slog den naiva prediktorn som endast använder medelbeteendet hos läkemedel och cellinjer. I scenarier som är mest relevanta för patienter, där modeller måste hantera cellinjer de aldrig sett tidigare, presterade finjusterade träd-baserade ensemblemetoder som random forests lika bra eller bättre än komplexa djupa nätverk. Alla metoder misslyckades när de ombads förutsäga effekten av läkemedel som inte ingick i deras träningsdata, och prestandan föll kraftigt vid övergång från en screeningsstudie till en annan eller från cellinjer till mer realistiska patientprover. Noggranna "ablation"-experiment visade att majoriteten av den användbara signalen kommer från grundläggande mätningar av genaktivitet, medan ytterligare datalager och sofistikerade läkemedelskodningar ofta tillför lite.
Varför detta spelar roll för framtida cancerbehandling
Studiens huvudbudskap är att pålitlig förutsägelse av cancerläkemedelsrespons fortfarande är ett olöst problem. Många tidigare framgångsberättelser var överdrivna på grund av partisk utvärdering snarare än verklig prediktiv förmåga. Genom att synliggöra dessa problem och erbjuda en delad, reproducerbar testbädd hjälper DrEval fältet att fokusera på metoder som verkligen lär sig hur cancer svarar på behandling istället för att utnyttja genvägar i data. För patienter innebär detta att datorbaserade modeller ännu inte är redo att vägleda rutinmässiga läkemedelsval, men vägen mot trovärdiga verktyg är klarare: bättre data, striktare testning och rättvisa jämförelser mellan enkla och komplexa modeller.
Citering: Bernett, J., Iversen, P., Picciani, M. et al. Critical evaluation of drug response prediction models with DrEval. Nat Commun 17, 4238 (2026). https://doi.org/10.1038/s41467-026-72903-w
Nyckelord: förutsägelse av läkemedelsrespons, cancercellinjer, maskininlärning, benchmarking, modelevaluering