Clear Sky Science · ru
Критическая оценка моделей прогнозирования ответа на лекарства с помощью DrEval
Почему важны более точные тесты противораковых препаратов
Когда врачи выбирают противораковые препараты, они часто опираются на широкие категории вроде типа опухоли и на несколько генетических маркёров. За последнее десятилетие учёные начали тестировать сотни препаратов на сотнях вырощенных в лаборатории раковых клеточных линий, одновременно измеряя генетические и другие молекулярные характеристики каждой линии. Многие компьютерные модели утверждают, что могут предсказывать, какие препараты сработают, на основе этих данных. Эта статья критически рассматривает такие утверждения и представляет DrEval, новую систему оценки, которая проверяет, насколько хорошо такие модели действительно работают в сценариях, близких к реальным медицинским решениям. 
Как компьютеры пытаются угадать успех препарата
Модели прогнозирования ответа на препараты обучаются на больших скрининговых проектах, где раковые клеточные линии подвергаются воздействию многих препаратов в разных дозах, и измеряется их выживаемость. Исследователи подают каждой модели подробные молекулярные профили клеточных линий и различные описания препаратов, а затем просят предсказать стандартные сводные показатели того, насколько сильно каждый препарат замедляет рост клеток. Некоторые подходы обучают по одной модели на каждый препарат, другие — одну модель на многие препараты в надежде, что она даже сможет оценивать ответы для новых лекарств. На бумаге эти методы часто сообщают впечатляющие показатели точности, создавая впечатление, что персонализированное лечение рака становится достижимым.
Скрытые подводные камни в существующих оценках
Авторы показывают, что эти оптимистичные результаты часто являются следствием того, как данные делятся и оцениваются, а не истинного понимания биологии рака. Если одна и та же клеточная линия или препарат встречается и в обучающем, и в тестовом наборах, модель может просто запомнить типичное поведение вместо того, чтобы выучить более глубокие закономерности. Поскольку разные препараты действуют в очень разных диапазонах доз, модель, которая только запоминает средний отклик по препарату, уже может объяснить большую часть вариации в данных. Это создаёт статистическую иллюзию: глобальная точность выглядит высокой, хотя модель не в состоянии различить, какие конкретные клеточные линии более или менее чувствительны к данному препарату.
Чем DrEval отличается
DrEval — это открытый фреймворк для бенчмаркинга, который стандартизирует процедуру тестирования моделей прогнозирования ответа на препараты. Он предоставляет согласованные наборы данных, аккуратную очистку данных и несколько реалистичных сценариев тестирования, отражающих распространённые цели: прогнозирование ответов для новых пациентов (новых клеточных линий), для новых типов рака (новых тканей) или для совершенно новых препаратов. Он также включает простые базовые методы, такие как предиктор, использующий только средние эффекты каждого препарата и каждой клеточной линии, и древовидные модели, которые намного проще обучать, чем глубокие нейронные сети. DrEval выполняет все модели в единой схеме кросс-валидации и настройки, а затем отчёты содержит метрики, устраняющие вводящее в заблуждение влияние усреднённых эффектов препарата и клеточной линии. 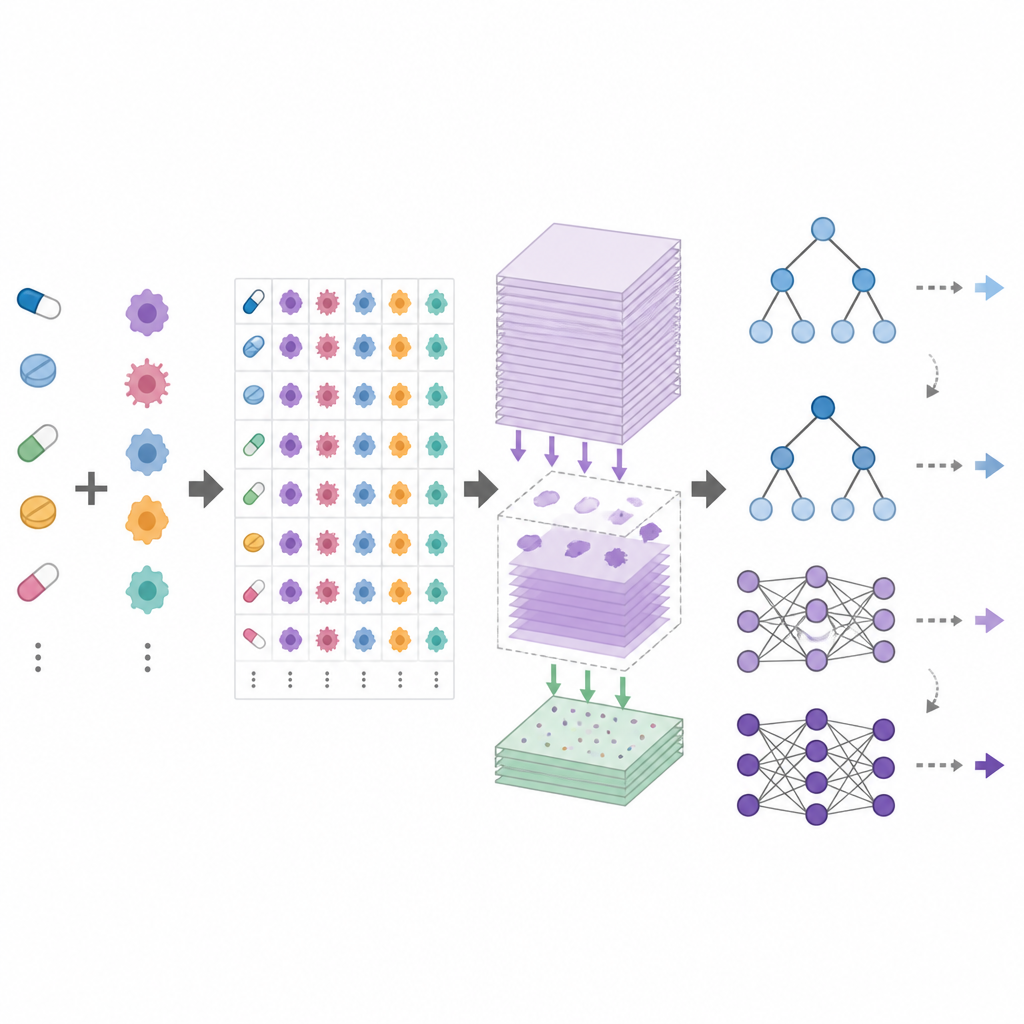
Что тесты показывают о современных моделях
Когда авторы пропустили широкий набор современных моделей через DrEval, они обнаружили, что многие едва превосходят наивный предиктор, использующий только среднее поведение препарата и клеточной линии. В сценариях, наиболее релевантных для пациентов, где модели должны работать с клеточными линиями, которых они ранее не видели, настроенные ансамбли на основе деревьев, такие как случайный лес, работали не хуже и иногда лучше сложных глубоких сетей. Все методы терпели неудачу при попытке предсказать эффект препаратов, не входивших в обучающую выборку, а производительность резко падала при переходе от одного скринингового исследования к другому или от клеточных линий к более реалистичным образцам от пациентов. Тщательные «абляционные» эксперименты показали, что большая часть полезного сигнала исходит из базовых измерений активности генов, тогда как дополнительные слои данных и сложные кодировки препаратов часто вносят мало вклада.
Почему это важно для будущего лечения рака
Главный вывод исследования в том, что надёжное прогнозирование ответа на противораковую терапию остаётся нерешённой задачей. Многие ранние успешные истории были преувеличены из‑за смещённых оценок, а не реальной предсказательной силы. Делая эти проблемы видимыми и предоставляя общий, воспроизводимый тестовый стенд, DrEval помогает полю сосредоточиться на методах, которые действительно учатся тому, как опухоли реагируют на лечение, вместо того чтобы эксплуатировать «короткие пути» в данных. Для пациентов это означает, что компьютерные модели ещё не готовы руководить рутинным выбором препаратов, но путь к доверенным инструментам стал яснее: лучшие данные, более строгие проверки и честное сравнение простых и сложных моделей.
Цитирование: Bernett, J., Iversen, P., Picciani, M. et al. Critical evaluation of drug response prediction models with DrEval. Nat Commun 17, 4238 (2026). https://doi.org/10.1038/s41467-026-72903-w
Ключевые слова: прогнозирование ответа на лекарства, раковые клеточные линии, машинное обучение, бенчмаркинг, оценка моделей