Clear Sky Science · pt
Avaliação crítica de modelos de predição de resposta a medicamentos com DrEval
Por que testes mais inteligentes para medicamentos contra o câncer importam
Quando os médicos escolhem medicamentos contra o câncer, costumam basear-se em categorias amplas como tipo de tumor e alguns marcadores genéticos. Na última década, cientistas começaram a testar centenas de fármacos em centenas de linhagens celulares cancerosas cultivadas em laboratório, enquanto também medem os genes e outras características moleculares de cada linhagem. Muitos modelos computacionais afirmam prever quais medicamentos serão eficazes com base nesses dados. Este texto analisa criticamente essas alegações e apresenta o DrEval, um novo kit de avaliação que testa o desempenho real desses modelos em situações que se assemelham a decisões médicas reais. 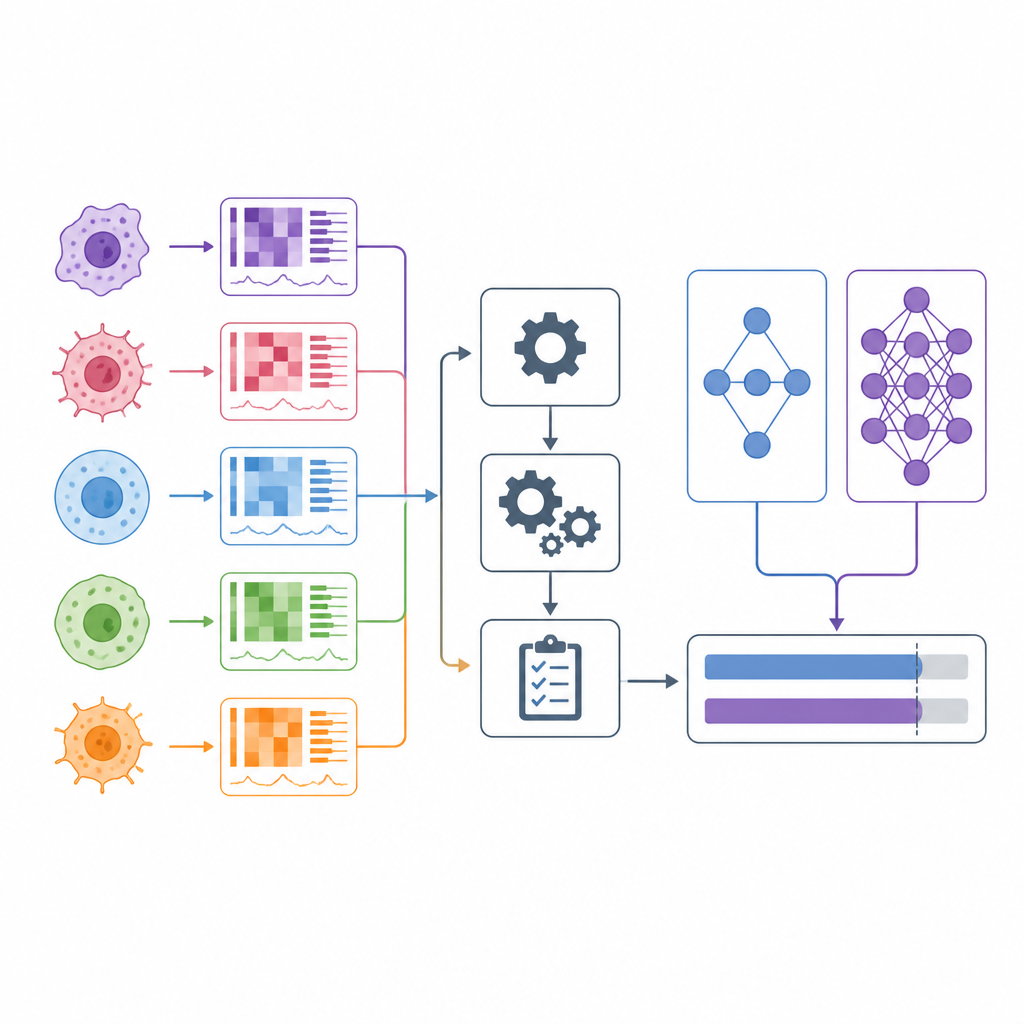
Como os computadores tentam adivinhar o sucesso de um medicamento
Modelos de predição de resposta a medicamentos aprendem a partir de grandes projetos de triagem nos quais linhagens celulares são expostas a vários fármacos em diferentes dosagens e sua sobrevivência é medida. Pesquisadores fornecem a cada modelo perfis moleculares detalhados das linhagens e diversas descrições dos fármacos, e então pedem para que preveja medidas resumo padrão de quanto cada fármaco reduz o crescimento celular. Algumas abordagens treinam um modelo por fármaco, enquanto outras treinam um único modelo para muitos medicamentos na esperança de estimar respostas para remédios novos. No papel, esses métodos frequentemente relatam números de acurácia impressionantes, sugerindo que tratamentos personalizados contra o câncer podem estar ao alcance.
Armadihas ocultas nas avaliações atuais
Os autores mostram que esses resultados otimistas frequentemente decorrem de como os dados são divididos e avaliados, e não de um entendimento genuíno da biologia do câncer. Se a mesma linhagem celular ou o mesmo fármaco aparece nos conjuntos de treino e teste, o modelo pode simplesmente memorizar comportamentos típicos em vez de aprender padrões mais profundos. Como diferentes medicamentos atuam em faixas de dose muito distintas, um modelo que apenas memoriza a resposta média por fármaco já pode explicar grande parte da variação nos dados. Isso cria uma ilusão estatística onde a acurácia global parece alta, mesmo que o modelo não consiga distinguir quais linhagens específicas são mais ou menos sensíveis a um dado fármaco.
O que o DrEval faz de diferente
DrEval é um framework aberto de benchmark que padroniza como modelos de resposta a medicamentos são testados. Ele fornece conjuntos de dados harmonizados, limpeza cuidadosa dos dados e vários cenários de teste realistas que espelham objetivos comuns: prever respostas para novos pacientes (novas linhagens), para novos tipos de câncer (novos tecidos) ou para fármacos totalmente novos. Inclui também métodos de baseline simples, como um preditor que usa apenas os efeitos médios de cada fármaco e cada linhagem, e modelos baseados em árvores que são muito mais fáceis de treinar do que redes neurais profundas. O DrEval executa todos os modelos sob o mesmo esquema de validação cruzada e ajuste de hiperparâmetros, e então reporta resultados com métricas que removem a influência enganosa dos efeitos médios de fármaco e linhagem celular. 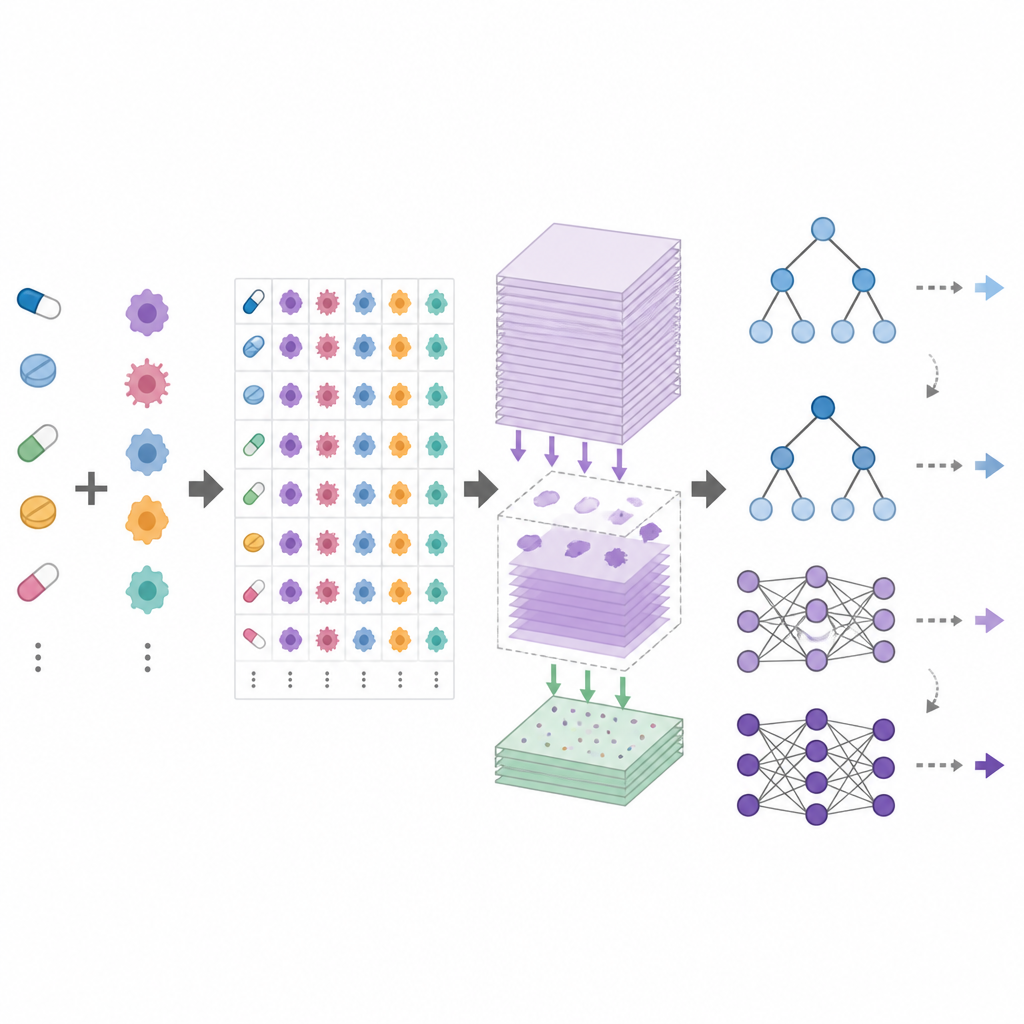
O que os testes revelam sobre os modelos atuais
Quando os autores submeteram uma ampla gama de modelos modernos ao DrEval, descobriram que muitos mal superam o preditor ingênuo que usa apenas o comportamento médio de fármacos e linhagens. Em cenários mais relevantes para pacientes, nos quais os modelos precisam lidar com linhagens que nunca viram antes, ensembles baseados em árvores ajustados, como florestas aleatórias, tiveram desempenho igual ou superior ao de redes profundas complexas. Todos os métodos falharam quando solicitados a prever o efeito de fármacos que não faziam parte dos dados de treino, e o desempenho caiu acentuadamente ao mudar de um estudo de triagem para outro ou de linhagens celulares para amostras mais realistas de pacientes. Experimentos de “ablação” cuidadosos mostraram que a maior parte do sinal útil vem de medições básicas da atividade gênica, enquanto camadas de dados adicionais e codificações sofisticadas de fármacos frequentemente contribuem pouco.
Por que isso importa para o tratamento futuro do câncer
A mensagem principal do estudo é que a predição confiável da resposta a medicamentos contra o câncer permanece um problema não resolvido. Muitas histórias de sucesso anteriores foram infladas por avaliações enviesadas em vez de verdadeiro poder preditivo. Ao tornar essas questões visíveis e fornecer um banco de testes compartilhado e reproduzível, o DrEval ajuda o campo a focar em métodos que realmente aprendem como os cânceres respondem ao tratamento em vez de explorar atalhos nos dados. Para os pacientes, isso significa que modelos computacionais ainda não estão prontos para orientar escolhas rotineiras de medicamentos, mas o caminho para ferramentas confiáveis fica mais claro: melhores dados, testes mais rigorosos e comparações justas entre modelos simples e complexos.
Citação: Bernett, J., Iversen, P., Picciani, M. et al. Critical evaluation of drug response prediction models with DrEval. Nat Commun 17, 4238 (2026). https://doi.org/10.1038/s41467-026-72903-w
Palavras-chave: predição de resposta a medicamentos, linhagens celulares de câncer, aprendizado de máquina, benchmarking, avaliação de modelos