Clear Sky Science · it
Valutazione critica dei modelli di predizione della risposta ai farmaci con DrEval
Perché test più intelligenti sui farmaci per il cancro sono importanti
Quando i medici scelgono i farmaci oncologici si affidano spesso a categorie ampie come il tipo di tumore e a pochi marcatori genetici. Nell’ultimo decennio, gli scienziati hanno iniziato a testare centinaia di farmaci su centinaia di linee cellulari tumorali coltivate in laboratorio, misurando nel contempo i profili genetici e altre caratteristiche molecolari di ciascuna linea. Molti modelli computazionali dichiarano di poter prevedere quali farmaci funzioneranno sulla base di questi dati. Questo articolo esamina criticamente tali affermazioni e presenta DrEval, un nuovo kit di valutazione che testa quanto questi modelli funzionino realmente in scenari che assomigliano a decisioni mediche reali. 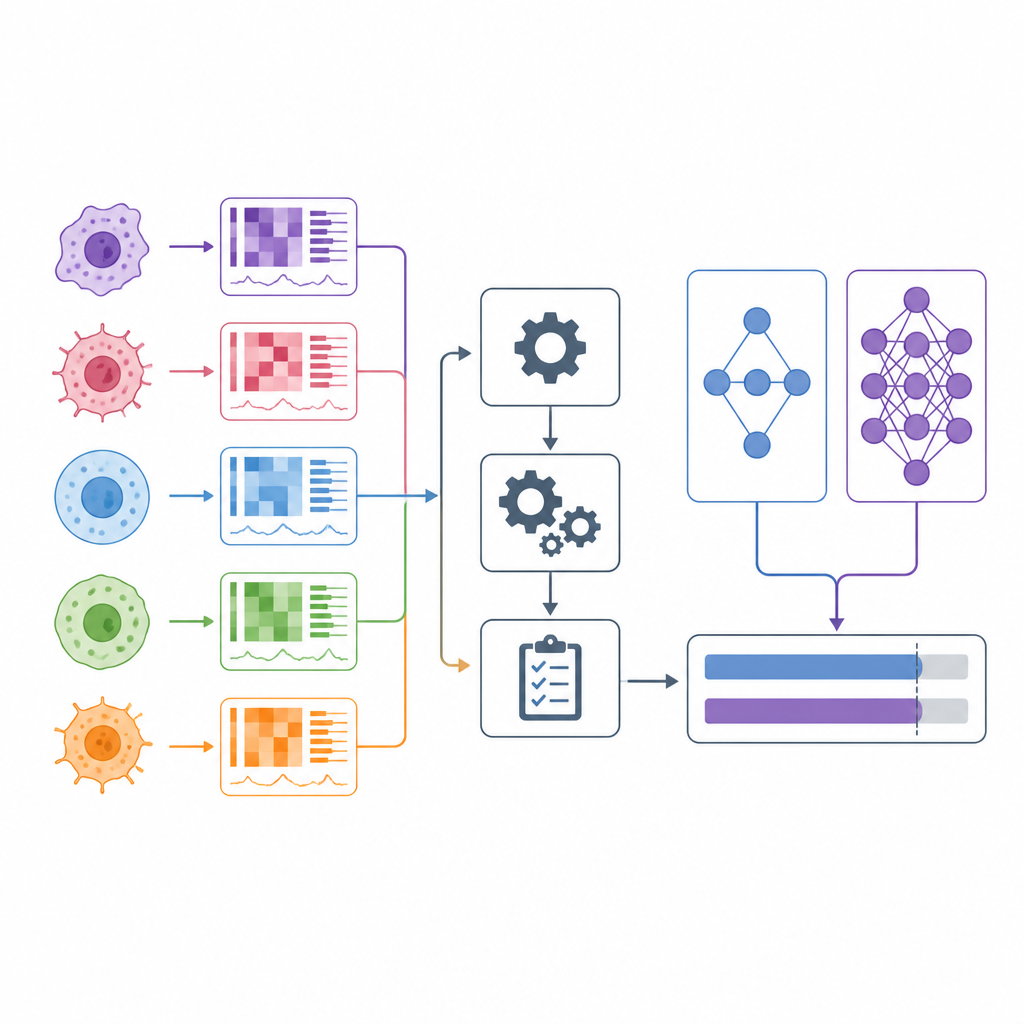
Come i computer cercano di indovinare il successo di un farmaco
I modelli di predizione della risposta ai farmaci apprendono da grandi progetti di screening in cui linee cellulari tumorali sono esposte a molti farmaci a diverse dosi e viene misurata la loro sopravvivenza. I ricercatori forniscono a ogni modello profili molecolari dettagliati delle linee cellulari e varie descrizioni dei farmaci, poi gli chiedono di prevedere misure di sintesi standard di quanto ciascun farmaco rallenti la crescita cellulare. Alcuni approcci addestrano un modello per ogni farmaco, mentre altri addestrano un unico modello su molti farmaci nella speranza che possa anche stimare le risposte per nuovi farmaci. Sulla carta, questi metodi spesso riportano numeri di accuratezza impressionanti, suggerendo che il trattamento oncologico personalizzato potrebbe essere a portata di mano.
Insidie nascoste nelle valutazioni attuali
Gli autori mostrano che questi risultati ottimistici spesso dipendono da come i dati vengono divisi e valutati, non da una reale comprensione della biologia del cancro. Se la stessa linea cellulare o lo stesso farmaco compaiono sia nel set di addestramento sia in quello di test, il modello può semplicemente memorizzare comportamenti tipici invece di imparare schemi più profondi. Poiché diversi farmaci agiscono in intervalli di dose molto diversi, un modello che memorizza solo la risposta media per farmaco può già spiegare gran parte della variazione nei dati. Questo crea un’illusione statistica in cui l’accuratezza globale sembra alta, anche se il modello non riesce a distinguere quali specifiche linee cellulari sono più o meno sensibili a un dato farmaco.
In cosa DrEval è diverso
DrEval è un framework di benchmarking aperto che standardizza il modo in cui i modelli di risposta ai farmaci vengono testati. Fornisce dataset armonizzati, pulizia accurata dei dati e diversi scenari di test realistici che rispecchiano obiettivi comuni: prevedere risposte per nuovi pazienti (nuove linee cellulari), per nuovi tipi di cancro (nuori tessuti) o per farmaci completamente nuovi. Include anche metodi baseline semplici, come un predittore che usa solo gli effetti medi di ciascun farmaco e di ciascuna linea cellulare, e modelli basati su alberi che sono molto più semplici da addestrare rispetto alle reti neurali profonde. DrEval esegue tutti i modelli sotto lo stesso schema di cross-validation e tuning, quindi riporta i risultati con metriche che rimuovono l’influenza fuorviante degli effetti medi di farmaco e linea cellulare. 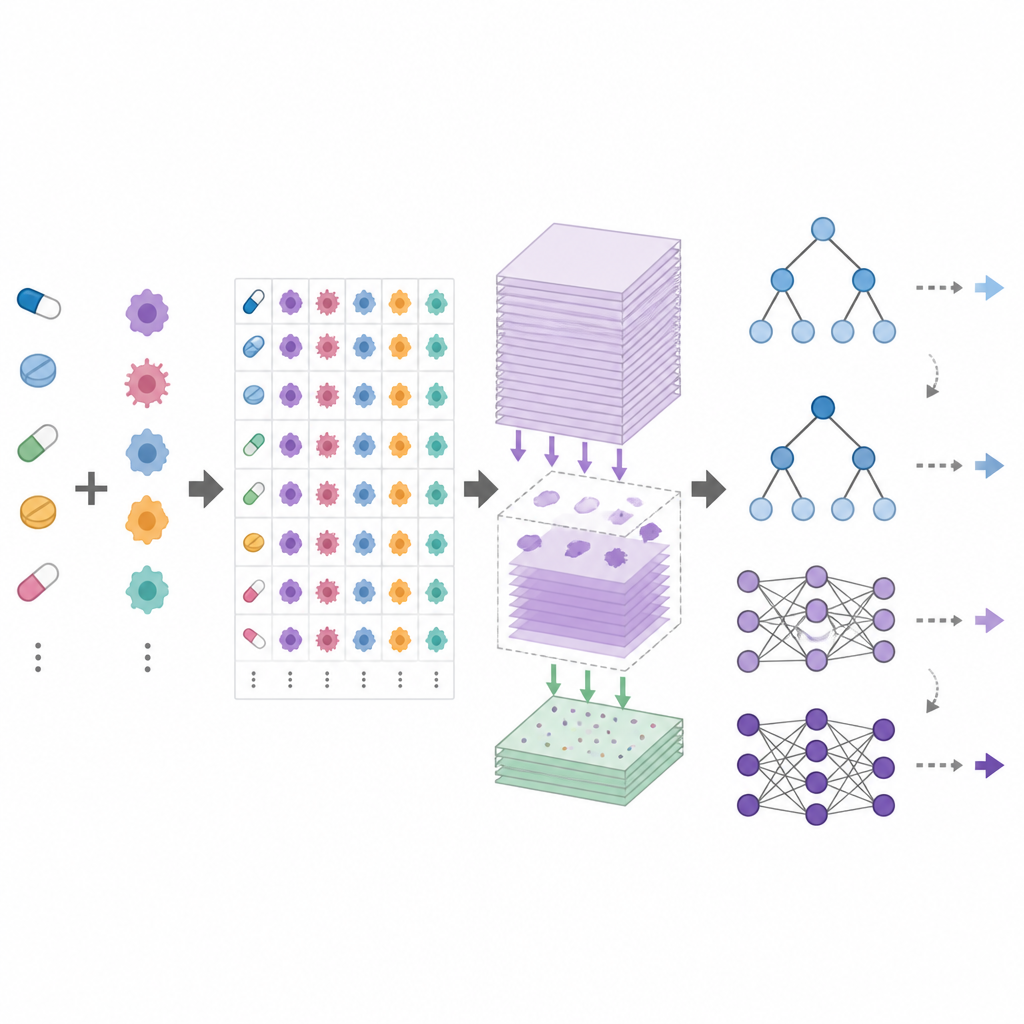
Cosa rivelano i test sui modelli attuali
Quando gli autori hanno fatto passare una vasta gamma di modelli moderni attraverso DrEval, hanno scoperto che molti superavano a malapena il predittore ingenuo che usa solo il comportamento medio di farmaci e linee cellulari. Negli scenari più rilevanti per i pazienti, in cui i modelli devono gestire linee cellulari mai viste prima, ensemble basati su alberi opportunamente ottimizzati come le random forest hanno funzionato tanto bene o meglio di reti profonde complesse. Tutti i metodi hanno fallito quando è stato chiesto di prevedere l’effetto di farmaci non presenti nei dati di addestramento, e le prestazioni sono calate bruscamente passando da uno studio di screening a un altro o dalle linee cellulari a campioni più realistici provenienti da pazienti. Esperimenti di “ablation” accurati hanno mostrato che la maggior parte del segnale utile proviene da misurazioni di base dell’attività genica, mentre strati di dati aggiuntivi e codifiche sofisticate dei farmaci spesso aggiungono poco.
Perché questo è importante per il futuro della cura del cancro
Il messaggio principale dello studio è che la predizione affidabile della risposta ai farmaci oncologici resta un problema aperto. Molte storie di successo precedenti erano gonfiate da valutazioni distorte piuttosto che da reale potere predittivo. Rendendo visibili questi problemi e fornendo un banco di prova condiviso e riproducibile, DrEval aiuta il campo a concentrarsi su metodi che imparino davvero come i tumori rispondono ai trattamenti invece di sfruttare scorciatoie nei dati. Per i pazienti, questo significa che i modelli computazionali non sono ancora pronti per guidare le scelte terapeutiche di routine, ma la strada verso strumenti affidabili è più chiara: dati migliori, test più rigorosi e confronti equi tra modelli semplici e complessi.
Citazione: Bernett, J., Iversen, P., Picciani, M. et al. Critical evaluation of drug response prediction models with DrEval. Nat Commun 17, 4238 (2026). https://doi.org/10.1038/s41467-026-72903-w
Parole chiave: predizione della risposta ai farmaci, linee cellulari tumorali, apprendimento automatico, benchmarking, valutazione dei modelli