Clear Sky Science · pl
Krytyczna ocena modeli przewidywania odpowiedzi na leki z DrEval
Dlaczego ważne są lepsze testy leków przeciwnowotworowych
Kiedy lekarze wybierają leki przeciwnowotworowe, często opierają się na szerokich kategoriach, takich jak typ guza, oraz na kilku markerach genetycznych. W ciągu ostatniej dekady badacze zaczęli testować setki leków na setkach hodowanych w laboratorium linii komórkowych nowotworów, jednocześnie mierząc profile genetyczne i inne cechy molekularne tych linii. Wiele modeli komputerowych twierdzi, że potrafi przewidzieć, które leki zadziałają na podstawie tych danych. Niniejszy artykuł przygląda się tym twierdzeniom krytycznie i przedstawia DrEval — nowe narzędzie ewaluacyjne, które sprawdza, jak dobrze takie modele radzą sobie w sytuacjach przypominających rzeczywiste decyzje medyczne. 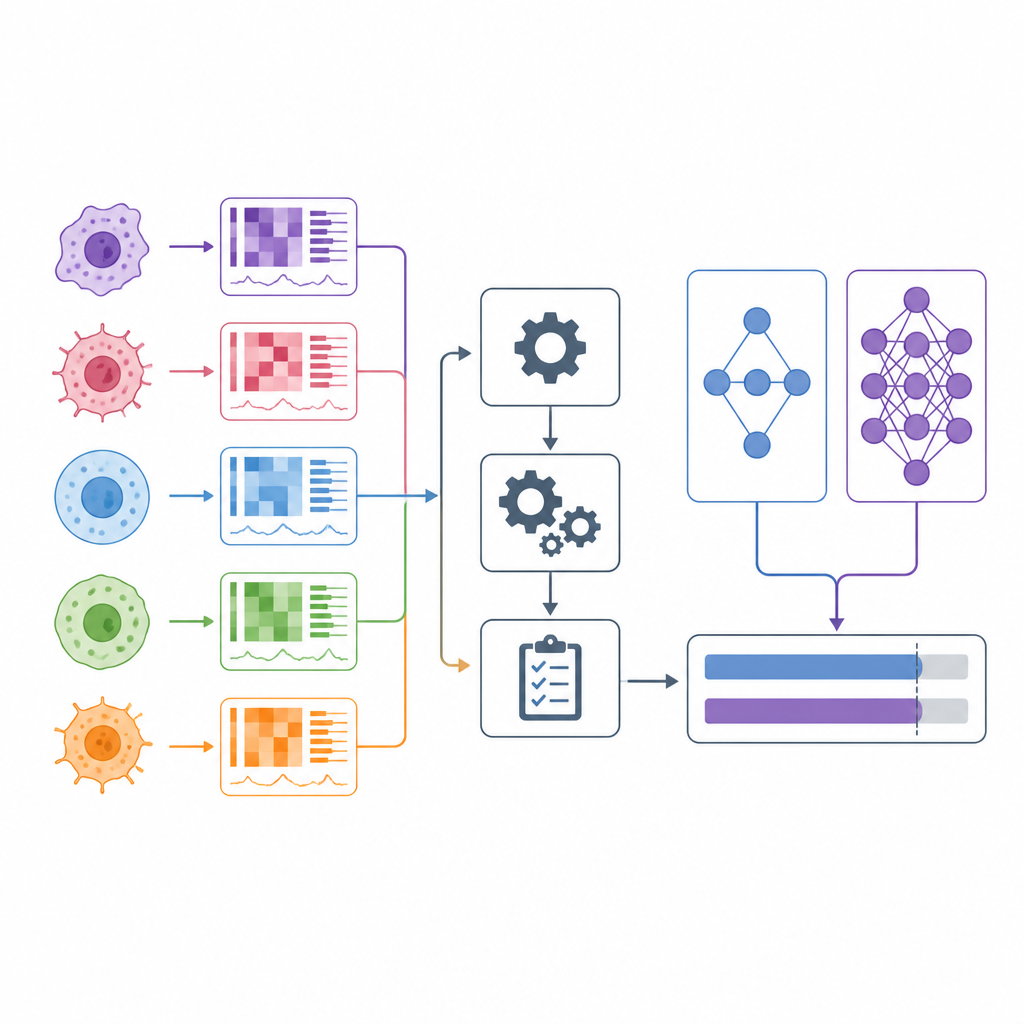
Jak komputery próbują przewidzieć skuteczność leku
Modele przewidywania odpowiedzi na leki uczą się na dużych projektach przesiewowych, gdzie linie komórkowe nowotworów są eksponowane na wiele leków w różnych dawkach, a następnie mierzy się ich przeżywalność. Badacze dostarczają modelom szczegółowe profile molekularne linii komórkowych oraz różne opisy leków, a zadaniem modelu jest przewidzenie standardowych miar streszczeniowych, określających, jak silnie dany lek hamuje wzrost komórek. Niektóre podejścia trenują osobny model dla każdego leku, inne trenują pojedynczy model na wielu lekach z nadzieją, że będzie potrafił oszacować odpowiedzi także dla nowych substancji. Na papierze metody te często raportują imponujące wyniki dokładności, co sugeruje, że spersonalizowane leczenie nowotworów może być w zasięgu ręki.
Ukryte pułapki we współczesnych ocenach
Autorzy pokazują, że optymistyczne rezultaty często wynikają z tego, jak dane są dzielone i oceniane, a nie z rzeczywistego zrozumienia biologii raka. Jeśli ta sama linia komórkowa lub lek pojawia się zarówno w zestawie treningowym, jak i testowym, model może po prostu zapamiętywać typowe zachowanie zamiast uczyć się głębszych wzorców. Ponieważ różne leki działają w bardzo różnych zakresach dawek, model, który jedynie zapamiętuje średnią odpowiedź dla danego leku, potrafi już wyjaśnić dużą część zmienności w danych. Tworzy to statystyczną iluzję wysokiej globalnej dokładności, nawet jeśli model nie potrafi rozróżnić, które konkretne linie komórkowe są bardziej lub mniej wrażliwe na dany lek.
Czym DrEval różni się od innych podejść
DrEval to otwarte ramy benchmarkingowe, które standaryzują sposób testowania modeli przewidywania odpowiedzi na leki. Dostarcza ujednolicone zestawy danych, staranne czyszczenie danych oraz kilka realistycznych scenariuszy testowych odpowiadających typowym celom: przewidywaniu odpowiedzi dla nowych pacjentów (nowe linie komórkowe), dla nowych typów nowotworów (nowe tkanki) lub dla zupełnie nowych leków. Zawiera też proste metody bazowe, takie jak predyktor wykorzystujący jedynie średnie efekty każdego leku i linii komórkowej, oraz modele drzewiaste, które są znacznie łatwiejsze do wytrenowania niż głębokie sieci neuronowe. DrEval uruchamia wszystkie modele w tym samym schemacie walidacji krzyżowej i strojenia, a następnie raportuje wyniki za pomocą miar, które usuwają mylący wpływ średnich efektów leku i linii komórkowej. 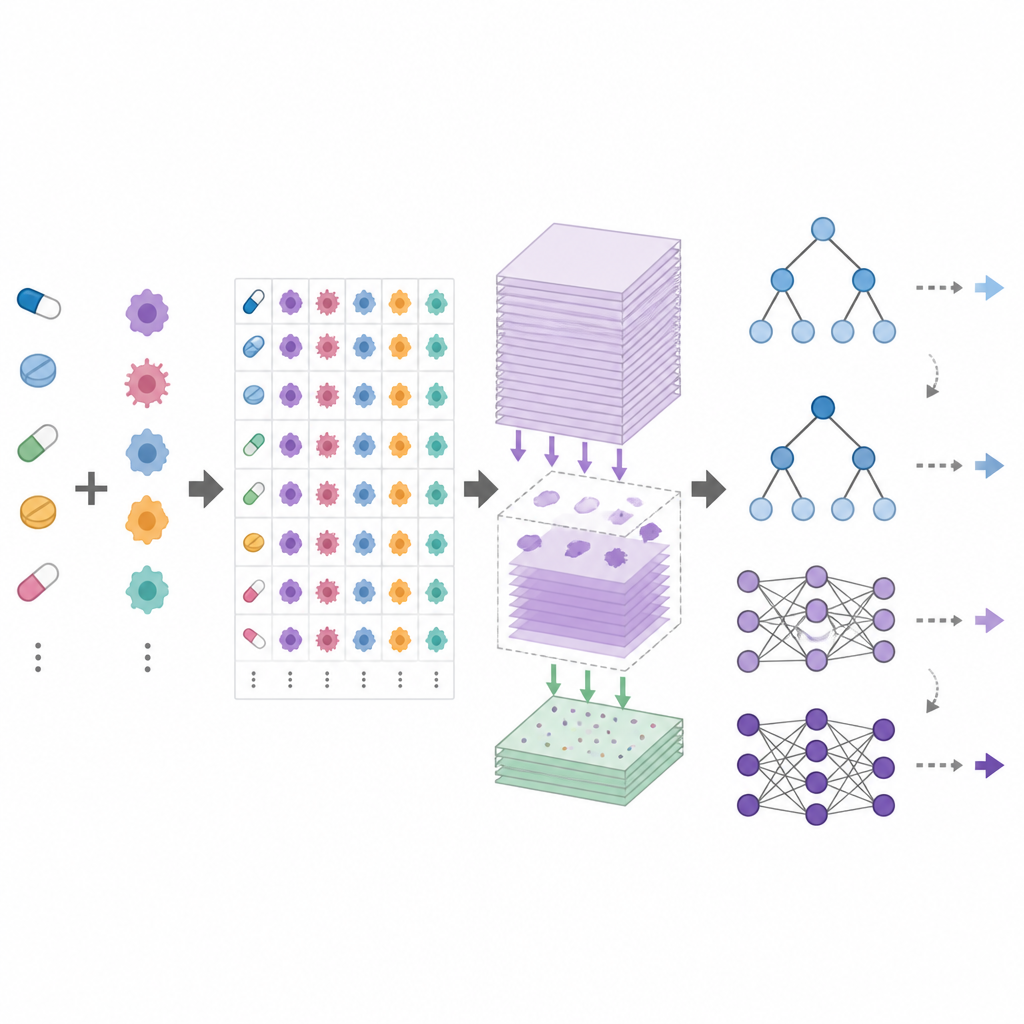
Co testy ujawniają o współczesnych modelach
Gdy autorzy przetestowali szeroką paletę nowoczesnych modeli za pomocą DrEval, odkryli, że wiele z nich ledwie wyprzedza naiwny predyktor korzystający tylko ze średniego zachowania leku i linii komórkowej. W ustawieniach najbardziej istotnych dla pacjentów, gdzie modele muszą radzić sobie z liniami komórkowymi, których nigdy wcześniej nie widziały, dostrojone zespoły drzewiaste, takie jak lasy losowe, wypadały równie dobrze lub lepiej niż skomplikowane sieci głębokie. Wszystkie metody zawodziły przy próbie przewidzenia działania leków, które nie były częścią danych treningowych, a wydajność spadała gwałtownie przy przenoszeniu z jednego badania przesiewowego do drugiego lub ze linii komórkowych do bardziej realistycznych próbek pacjentów. Dokładne eksperymenty „ablacyjne” wykazały, że większość użytecznego sygnału pochodzi z podstawowych pomiarów aktywności genów, podczas gdy dodatkowe warstwy danych i zaawansowane reprezentacje leków często wnoszą niewiele.
Dlaczego to ma znaczenie dla przyszłego leczenia nowotworów
Główne przesłanie badania jest takie, że wiarygodne przewidywanie odpowiedzi na leki przeciwnowotworowe pozostaje nierozwiązanym problemem. Wiele wcześniejszych doniesień o sukcesie było zawyżonych przez stronnicze oceny, a nie przez prawdziwą moc predykcyjną. Dzięki ujawnieniu tych problemów i udostępnieniu wspólnego, powtarzalnego środowiska testowego, DrEval pomaga polu skupić się na metodach, które rzeczywiście uczą się, jak nowotwory reagują na leczenie, zamiast wykorzystywać skróty w danych. Dla pacjentów oznacza to, że modele komputerowe nie są jeszcze gotowe do rutynowego kierowania wyborami leków, ale droga do wiarygodnych narzędzi jest jaśniejsza: lepsze dane, surowsze testy i uczciwe porównania między prostymi a złożonymi modelami.
Cytowanie: Bernett, J., Iversen, P., Picciani, M. et al. Critical evaluation of drug response prediction models with DrEval. Nat Commun 17, 4238 (2026). https://doi.org/10.1038/s41467-026-72903-w
Słowa kluczowe: przewidywanie odpowiedzi na leki, linie komórkowe nowotworów, uczenie maszynowe, benchmarking, ocena modeli