Clear Sky Science · fr
Évaluation critique des modèles de prédiction de la réponse aux médicaments avec DrEval
Pourquoi des tests plus pertinents pour les médicaments contre le cancer sont importants
Lorsque les médecins choisissent des traitements anticancéreux, ils s’appuient souvent sur de larges catégories comme le type de tumeur et quelques marqueurs génétiques. Au cours de la dernière décennie, les chercheurs ont commencé à tester des centaines de médicaments sur des centaines de lignées cellulaires cancéreuses cultivées en laboratoire, tout en mesurant les gènes et d’autres caractéristiques moléculaires de chaque lignée. De nombreux modèles informatiques prétendent prédire quels médicaments seront efficaces à partir de ces données. Cet article examine ces prétentions de près et présente DrEval, une nouvelle boîte à outils d’évaluation qui teste la performance réelle de ces modèles dans des situations qui ressemblent à des décisions médicales réelles. 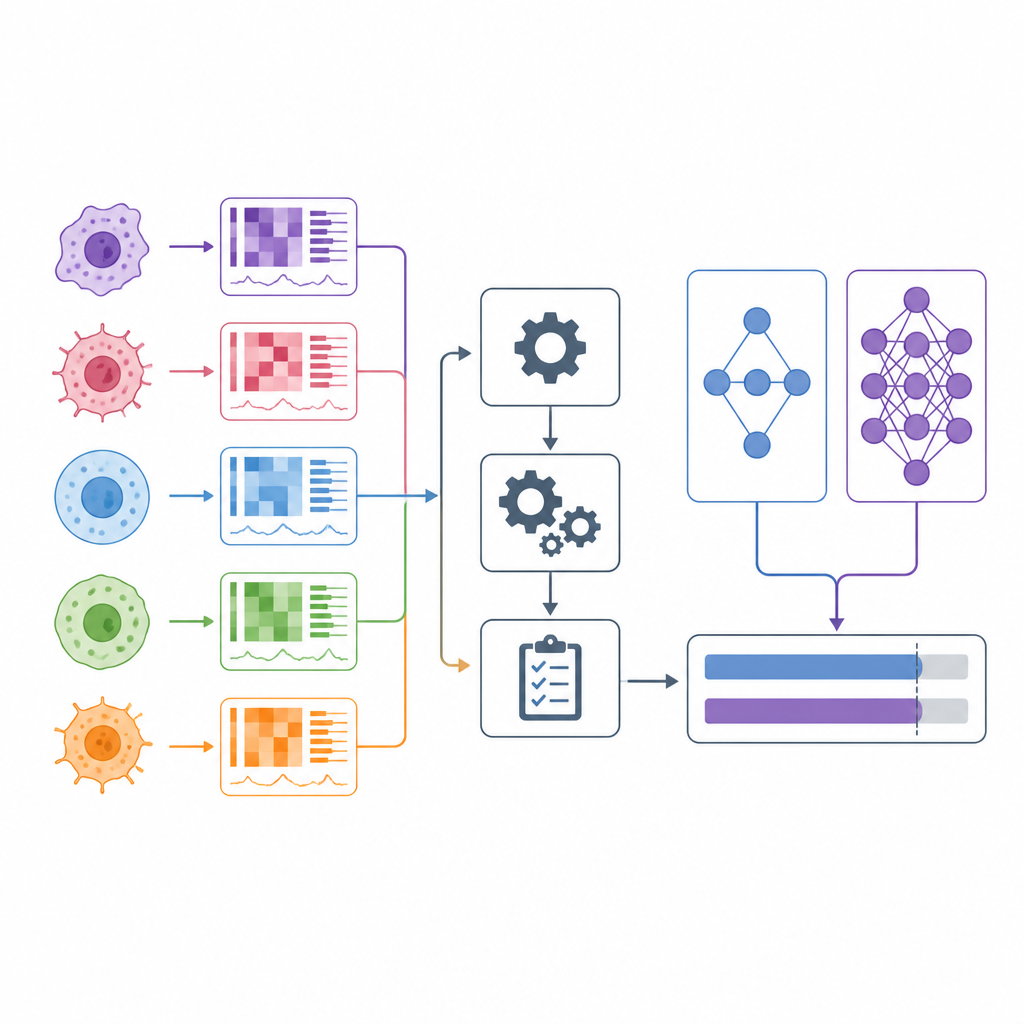
Comment les ordinateurs tentent de deviner le succès d’un médicament
Les modèles de prédiction de la réponse aux médicaments s’entraînent sur de grands projets de criblage où des lignées cellulaires cancéreuses sont exposées à de nombreux médicaments à différentes doses et leur survie est mesurée. Les chercheurs fournissent à chaque modèle des profils moléculaires détaillés des lignées et diverses descriptions des médicaments, puis lui demandent de prédire des mesures résumées standard de l’intensité avec laquelle chaque médicament ralentit la croissance cellulaire. Certaines approches entraînent un modèle par médicament, tandis que d’autres entraînent un modèle unique sur de nombreux médicaments en espérant qu’il puisse même estimer les réponses pour de nouveaux traitements. Sur le papier, ces méthodes affichent souvent des chiffres de précision impressionnants, suggérant que la médecine personnalisée contre le cancer pourrait être à portée de main.
Pièges cachés dans les évaluations actuelles
Les auteurs montrent que ces résultats optimistes proviennent souvent de la façon dont les données sont réparties et évaluées, et non d’une véritable compréhension de la biologie du cancer. Si la même lignée cellulaire ou le même médicament apparaît à la fois dans les jeux d’entraînement et de test, le modèle peut simplement mémoriser un comportement typique au lieu d’apprendre des motifs plus profonds. Parce que différents médicaments agissent à des plages de dose très différentes, un modèle qui se contente de mémoriser la réponse moyenne par médicament peut déjà expliquer une grande partie de la variation des données. Cela crée une illusion statistique où la précision globale semble élevée, alors que le modèle n’arrive pas à distinguer quelles lignées cellulaires sont réellement plus ou moins sensibles à un médicament donné.
Ce que fait différemment DrEval
DrEval est un cadre ouvert d’évaluation comparative qui standardise la manière dont les modèles de réponse aux médicaments sont testés. Il fournit des ensembles de données harmonisés, un nettoyage soigné des données et plusieurs scénarios de test réalistes qui reflètent des objectifs courants : prédire les réponses pour de nouveaux patients (nouvelles lignées cellulaires), pour de nouveaux types de cancer (nouveaux tissus) ou pour des médicaments entièrement nouveaux. Il inclut également des méthodes de référence simples, comme un prédicteur utilisant seulement les effets moyens de chaque médicament et de chaque lignée, ainsi que des modèles à base d’arbres qui sont beaucoup plus faciles à entraîner que les réseaux neuronaux profonds. DrEval exécute tous les modèles selon le même schéma de validation croisée et d’ajustement, puis rapporte des résultats avec des métriques qui retirent l’influence trompeuse des effets moyens des médicaments et des lignées cellulaires. 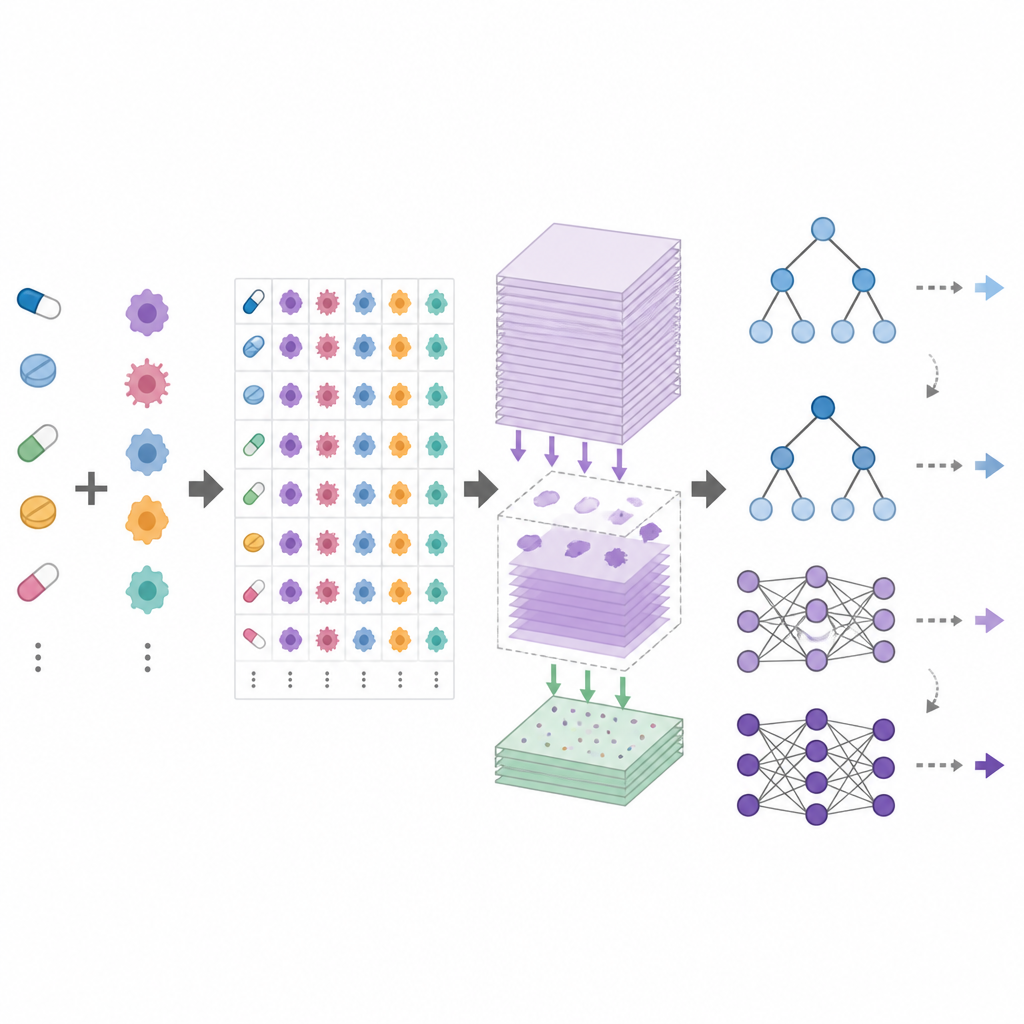
Ce que les tests révèlent sur les modèles actuels
Lorsque les auteurs ont soumis une large gamme de modèles modernes à DrEval, ils ont constaté que beaucoup dépassaient à peine le prédicteur naïf qui n’utilise que le comportement moyen des médicaments et des lignées cellulaires. Dans les contextes les plus pertinents pour les patients, où les modèles doivent gérer des lignées qu’ils n’ont jamais vues, des ensembles d’arbres optimisés comme les forêts aléatoires ont performé aussi bien ou mieux que des réseaux profonds complexes. Toutes les méthodes ont échoué lorsqu’on leur a demandé de prédire l’effet de médicaments absents des données d’entraînement, et les performances se sont effondrées lors du passage d’une étude de criblage à une autre ou du passage des lignées cellulaires à des échantillons plus réalistes issus de patients. Des expériences d’« ablation » rigoureuses ont montré que la majeure partie du signal utile provient de mesures basiques de l’activité génique, tandis que des couches de données additionnelles et des encodages sophistiqués des médicaments apportent souvent peu.
Pourquoi cela compte pour l’avenir des traitements contre le cancer
Le message principal de l’étude est que la prédiction fiable de la réponse aux médicaments en oncologie reste un problème non résolu. De nombreuses histoires de succès antérieures ont été exagérées par des évaluations biaisées plutôt que par un pouvoir prédictif réel. En rendant ces problèmes visibles et en fournissant un banc d’essai partagé et reproductible, DrEval aide le domaine à se concentrer sur des méthodes qui apprennent véritablement comment les cancers répondent aux traitements au lieu d’exploiter des raccourcis dans les données. Pour les patients, cela signifie que les modèles informatiques ne sont pas encore prêts à guider les choix de médicaments en routine, mais la voie vers des outils fiables est plus claire : de meilleures données, des tests plus stricts et des comparaisons équitables entre modèles simples et complexes.
Citation: Bernett, J., Iversen, P., Picciani, M. et al. Critical evaluation of drug response prediction models with DrEval. Nat Commun 17, 4238 (2026). https://doi.org/10.1038/s41467-026-72903-w
Mots-clés: prédiction de la réponse aux médicaments, lignées cellulaires cancéreuses, apprentissage automatique, évaluation comparative, évaluation des modèles