Clear Sky Science · nl
Kritische evaluatie van modellen voor geneesmiddelrespons met DrEval
Waarom slimmer testen van kankergeneesmiddelen ertoe doet
Wanneer artsen kankerbehandelingen kiezen, vertrouwen ze vaak op brede categoriën zoals tumortype en een handvol genetische markers. In het afgelopen decennium zijn onderzoekers begonnen met het testen van honderden geneesmiddelen op honderden in het laboratorium gekweekte kankercellijnen, terwijl ze tevens de genen en andere moleculaire kenmerken van elke cellijn meten. Veel computermodellen beweren te kunnen voorspellen welke geneesmiddelen zullen werken op basis van deze data. Dit artikel bekijkt die beweringen kritisch en introduceert DrEval, een nieuw evaluatietoolkit die test hoe goed zulke modellen werkelijk presteren in situaties die lijken op echte medische beslissingen. 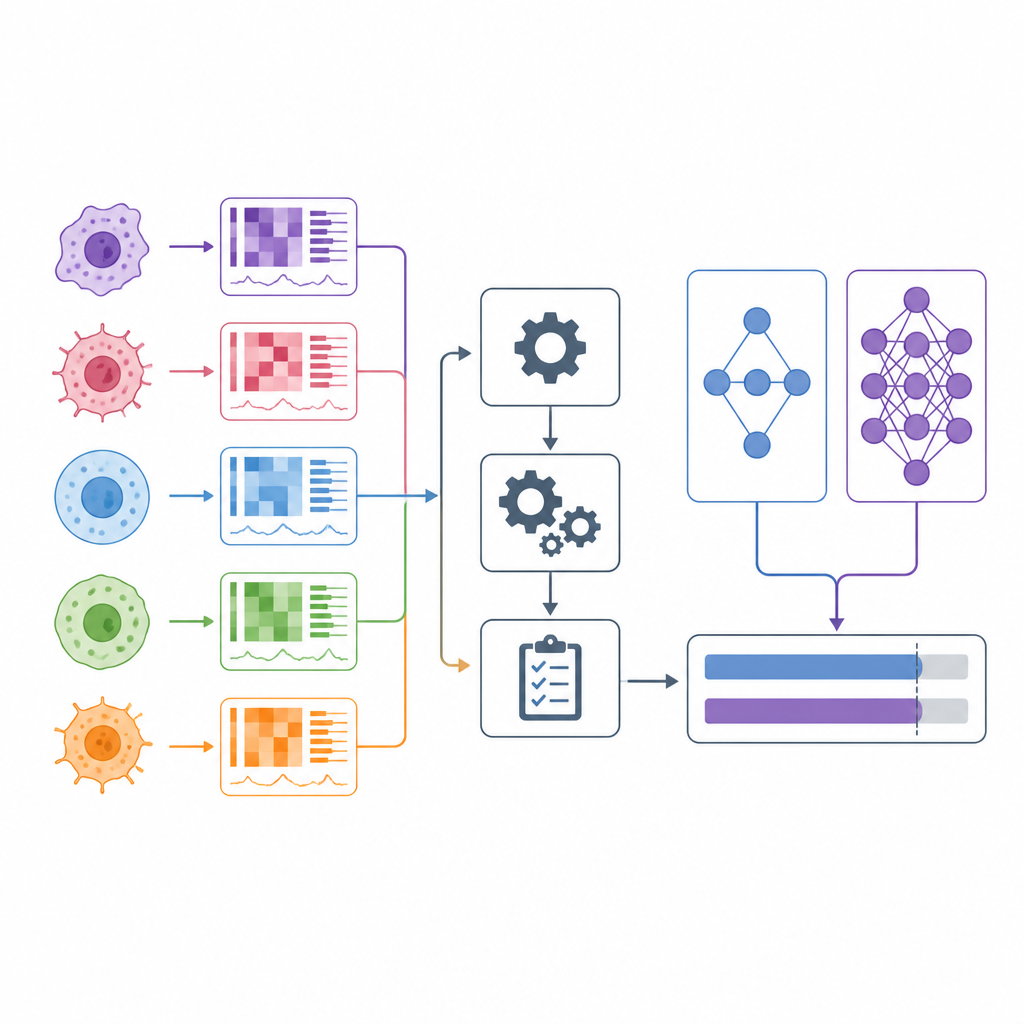
Hoe computers proberen geneesmiddelsucces te raden
Modellen voor het voorspellen van geneesmiddelrespons leren van grote screeningsprojecten waarin kankercellijnen aan veel geneesmiddelen bij verschillende doseringen worden blootgesteld en hun overleving wordt gemeten. Onderzoekers voeren elk model gedetailleerde moleculaire profielen van de cellijnen en verschillende beschrijvingen van de geneesmiddelen aan, en vragen het model vervolgens om standaard samenvattende maten te voorspellen van hoe sterk elk geneesmiddel de celgroei remt. Sommige benaderingen trainen één model per geneesmiddel, terwijl andere één enkel model trainen over veel geneesmiddelen in de hoop dat het zelfs reacties voor nieuwe middelen kan inschatten. Op papier rapporteren deze methoden vaak indrukwekkende nauwkeurigheidscijfers, wat suggereert dat gepersonaliseerde kankerbehandeling binnen handbereik zou kunnen zijn.
Verborgen valkuilen in huidige evaluaties
De auteurs tonen aan dat deze optimistische resultaten vaak voortkomen uit de manier waarop de data worden gesplitst en beoordeeld, en niet uit echte inzichten in de kankerbiologie. Als dezelfde cellijn of hetzelfde geneesmiddel zowel in trainings- als in testsets voorkomt, kan het model simpelweg typisch gedrag memoriseren in plaats van diepere patronen te leren. Omdat verschillende geneesmiddelen werkzaam zijn bij zeer uiteenlopende dosisbereiken, kan een model dat alleen het gemiddelde respons per geneesmiddel memoriseert al veel van de variatie in de data verklaren. Dit creëert een statistische illusie waarbij de globale nauwkeurigheid hoog lijkt, terwijl het model er niet in slaagt te onderscheiden welke specifieke cellijnen gevoeliger of minder gevoelig zijn voor een bepaald geneesmiddel.
Wat DrEval anders doet
DrEval is een open benchmarkingframework dat standaardiseert hoe modellen voor geneesmiddelrespons worden getest. Het biedt geharmoniseerde datasets, zorgvuldige datareiniging en verschillende realistische testscenario’s die gangbare doelen weerspiegelen: het voorspellen van reacties voor nieuwe patiënten (nieuwe cellijnen), voor nieuwe kankertypes (nieuwe weefsels) of voor volledig nieuwe geneesmiddelen. Het bevat ook eenvoudige basismethoden, zoals een voorspeller die alleen de gemiddelde effecten van elk geneesmiddel en elke cellijn gebruikt, en boomgebaseerde modellen die veel makkelijker te trainen zijn dan diepe neurale netwerken. DrEval voert alle modellen uit onder hetzelfde cross‑validation‑ en afstemmingsschema en rapporteert vervolgens resultaten met metriek die de misleidende invloed van gemiddelde geneesmiddel‑ en cellijn‑effecten wegneemt. 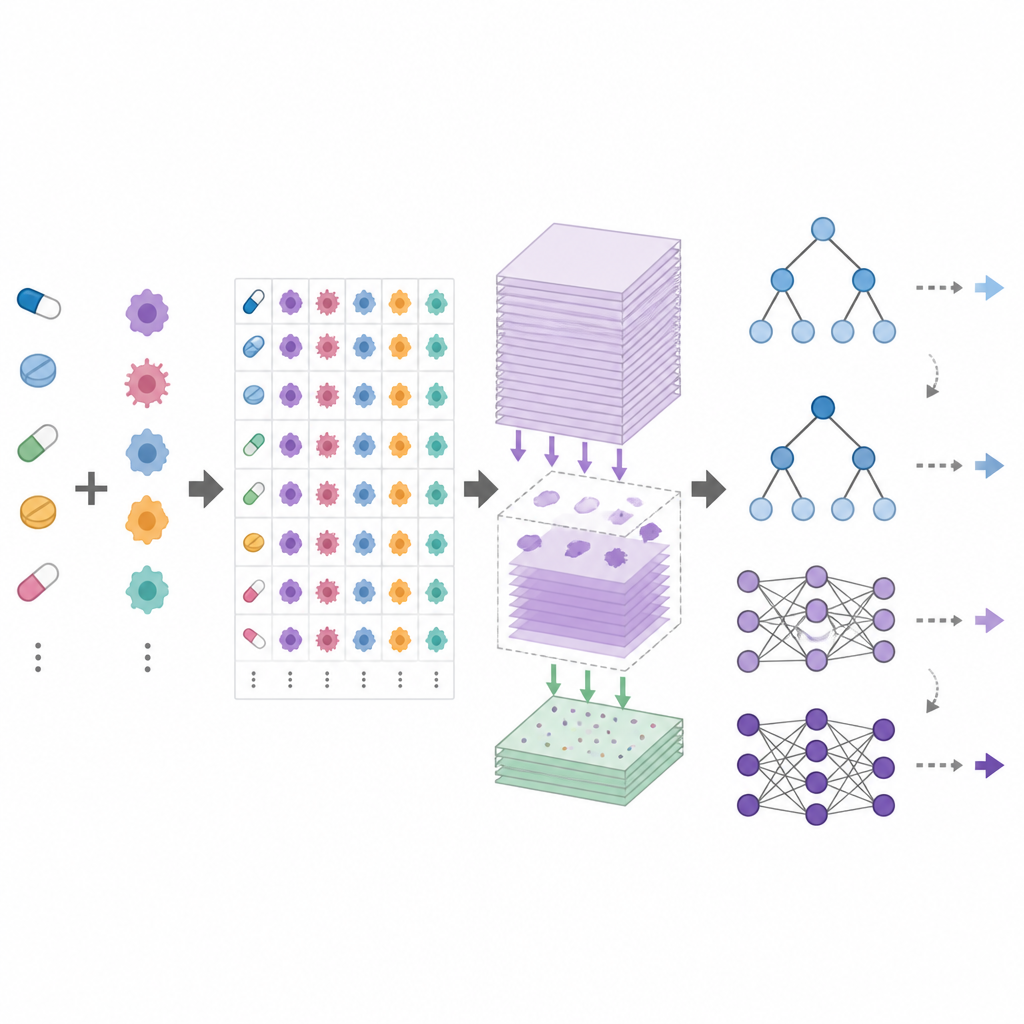
Wat de tests onthullen over de modellen van vandaag
Toen de auteurs een brede reeks moderne modellen door DrEval lieten lopen, vonden ze dat velen nauwelijks beter presteerden dan de naïeve voorspeller die alleen gemiddelde gedragspatronen van geneesmiddelen en cellijnen gebruikt. In scenario’s die het meest relevant zijn voor patiënten, waar modellen cellijnen moeten verwerken die ze nooit eerder hebben gezien, presteerden goed afgestemde boomensembles zoals random forests even goed of beter dan complexe diepe netwerken. Alle methoden faalden wanneer ze gevraagd werden het effect van geneesmiddelen te voorspellen die geen deel uitmaakten van hun trainingsdata, en de prestaties daalden sterk bij overschakeling van de ene screeningsstudie naar de andere of van cellijnen naar meer realistische monsters van patiënten. Zorgvuldige “ablaties” lieten zien dat het meeste nuttige signaal afkomstig is van basale genactiviteitsmetingen, terwijl extra datalagen en geavanceerde geneesmiddelcoderingen vaak weinig toevoegen.
Waarom dit belangrijk is voor toekomstige kankerbehandeling
De hoofdboodschap van de studie is dat betrouwbare voorspelling van kanker‑geneesmiddelrespons nog steeds een onopgelost probleem is. Veel eerdere succesverhalen waren opgeblazen door bevooroordeelde evaluatie in plaats van echte voorspellende kracht. Door deze problemen zichtbaar te maken en een gedeelde, reproduceerbare testomgeving te bieden, helpt DrEval het veld zich te richten op methoden die daadwerkelijk leren hoe kankers reageren op behandeling in plaats van shortcuts in de data te benutten. Voor patiënten betekent dit dat computermodellen nog niet klaar zijn om routinematig behandelingskeuzes te sturen, maar het pad naar betrouwbare hulpmiddelen is duidelijker: betere data, strengere testen en eerlijke vergelijkingen tussen eenvoudige en complexe modellen.
Bronvermelding: Bernett, J., Iversen, P., Picciani, M. et al. Critical evaluation of drug response prediction models with DrEval. Nat Commun 17, 4238 (2026). https://doi.org/10.1038/s41467-026-72903-w
Trefwoorden: voorspelling van geneesmiddelrespons, kankercellijnen, machine learning, benchmarking, modelevaluatie