Clear Sky Science · ja
DrEvalによる薬物反応予測モデルの批判的評価
なぜより賢いがん薬診断が重要か
医師ががん治療薬を選ぶ際、腫瘍の種類や限られた遺伝マーカーのような大まかな分類に頼ることが多い。過去十年で、研究者は何百種類もの薬を何百の培養がん細胞株に対して試験し、それぞれの細胞株の遺伝子やその他の分子特徴も測定するようになった。多くの計算モデルはこれらのデータに基づいてどの薬が効くかを予測できると主張している。本稿はそうした主張を厳しく検証し、医療判断に近い状況でモデルがどれほど実際に機能するかを試す新しい評価ツールキットDrEvalを紹介する。 
コンピュータは薬の成功をどう推定するか
薬物反応予測モデルは、多くの薬を異なる濃度でがん細胞株に曝露し生存率を測定する大規模スクリーニングプロジェクトから学習する。研究者は各モデルに細胞株の詳細な分子プロファイルや薬の記述を与え、各薬がどの程度細胞増殖を抑えるかの標準的な要約指標を予測させる。ある手法は薬ごとにモデルを訓練し、別の手法は多数の薬にまたがる単一モデルを訓練して新薬への推定も可能にしようとする。紙面上では、これらの方法はしばしば印象的な精度を報告し、個別化がん治療が手の届くところにあるかのように示される。
現在の評価に潜む落とし穴
著者らは、こうした楽観的な結果の多くがデータの分割や評価方法に由来し、がん生物学への真の洞察から来ているわけではないことを示す。訓練データとテストデータの両方に同じ細胞株や薬が含まれると、モデルは深いパターンを学ぶ代わりに典型的な挙動を丸暗記してしまう可能性がある。薬ごとに有効な濃度範囲が大きく異なるため、薬ごとの平均反応だけを記憶するモデルでもデータ中の変動の大部分を説明できてしまう。これにより、全体的な精度は高く見えても、特定の薬に対してどの細胞株がより感受性が高いかを識別できないという統計的な錯覚が生じる。
DrEvalが異なる点
DrEvalは薬物反応モデルのテスト方法を標準化するオープンなベンチマーキングフレームワークである。統一されたデータセット、丁寧なデータクリーニング、および次のような現実的なテストシナリオを提供する:新しい患者(未見の細胞株)の反応予測、新しいがん種(未見の組織)の反応予測、あるいは全く新しい薬の反応予測。さらに、薬および細胞株ごとの平均効果のみを用いる単純な予測器や、深層ニューラルネットワークより訓練が容易なツリーベースのモデルなどのシンプルなベースラインも含む。DrEvalはすべてのモデルを同一のクロスバリデーションとチューニング手順で実行し、平均的な薬および細胞株効果の誤った影響を除去する指標で結果を報告する。 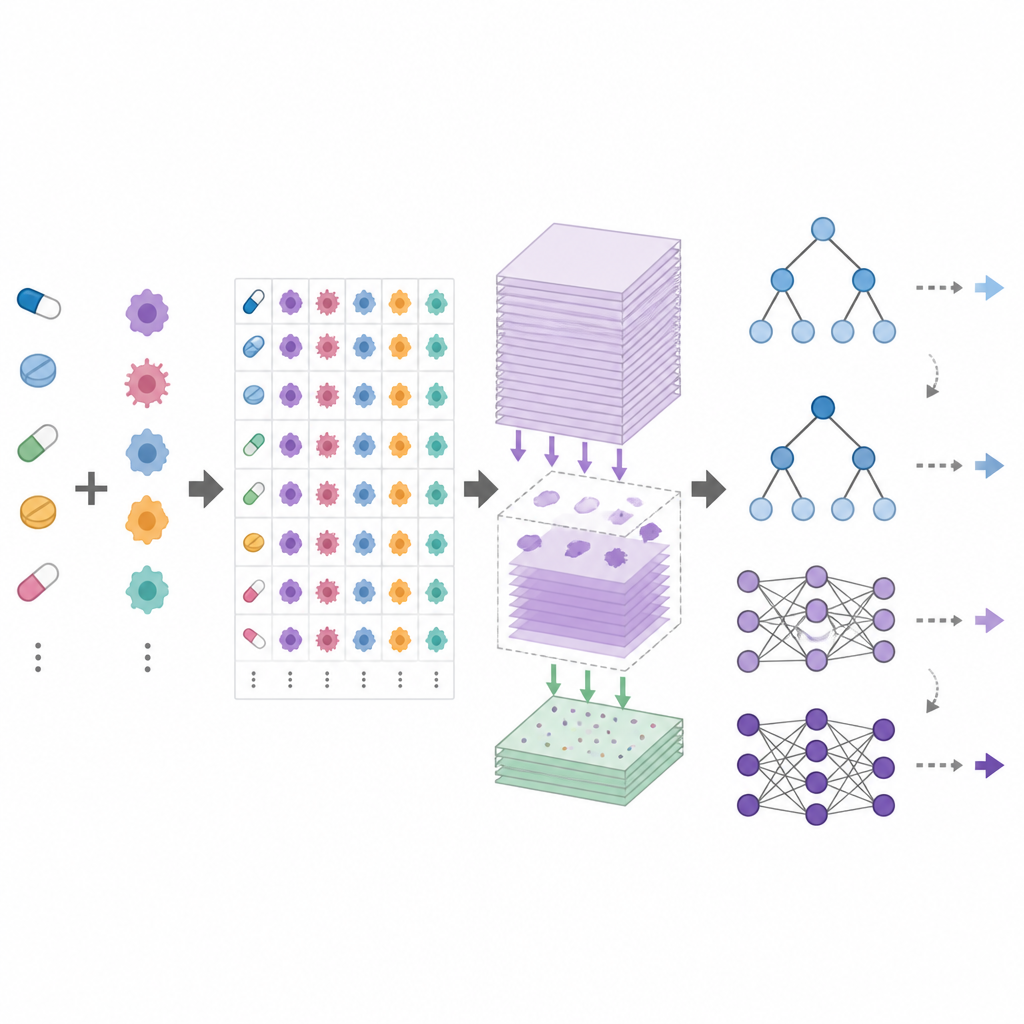
今日のモデルについてテストが明らかにしたこと
著者らが幅広い最新モデルをDrEvalで評価したところ、多くは薬と細胞株の平均挙動のみを使う単純な予測器をかろうじて上回る程度であった。患者にとって最も関連性が高い状況、すなわちモデルがこれまで見たことのない細胞株を扱わねばならない設定では、ランダムフォレストのような調整済みのツリーベースアンサンブルが複雑な深層ネットワークと同等かそれ以上の性能を示した。すべての手法は訓練データに含まれていない薬の効果を予測することに失敗し、異なるスクリーニング研究間や細胞株から患者由来のより現実的なサンプルへ移ると性能が急落した。綿密な“アブレーション”実験により、有用な信号の大部分は基本的な遺伝子発現測定から来ており、追加のデータ層や複雑な薬のエンコーディングはしばしばほとんど寄与しないことが示された。
将来のがん治療にとっての意義
本研究の主たるメッセージは、がん薬反応の信頼できる予測は依然として未解決の問題であるということだ。以前の多くの成功事例は真の予測力ではなくバイアスのある評価によって過大に評価されていた。これらの問題を可視化し、共有可能で再現性のあるテストベッドを提供することで、DrEvalはデータの抜け穴を突く手法ではなく、実際にがんの治療反応を学習する方法に研究の焦点を当てる手助けをする。患者にとっては、計算モデルが日常的な薬選択を導くにはまだ準備が整っていないことを意味するが、より良いデータ、厳格なテスト、単純なモデルと複雑なモデルの公正な比較という道筋によって、信頼できるツールへの道はより明確になった。
引用: Bernett, J., Iversen, P., Picciani, M. et al. Critical evaluation of drug response prediction models with DrEval. Nat Commun 17, 4238 (2026). https://doi.org/10.1038/s41467-026-72903-w
キーワード: 薬物反応予測, がん細胞株, 機械学習, ベンチマーキング, モデル評価