Clear Sky Science · de
Kritische Bewertung von Vorhersagemodellen für Medikamentenwirkung mit DrEval
Warum intelligentere Tests für Krebsmedikamente wichtig sind
Wenn Ärztinnen und Ärzte Krebsmedikamente auswählen, stützen sie sich häufig auf breite Kategorien wie Tumortyp und einige genetische Marker. In den letzten zehn Jahren begannen Forschende damit, Hunderte von Medikamenten an hunderten im Labor gezüchteten Krebszelllinien zu testen und gleichzeitig die Gene sowie andere molekulare Merkmale jeder Zelllinie zu messen. Viele Computermodelle behaupten, daraus vorhersagen zu können, welche Medikamente wirken. Dieser Artikel prüft diese Ansprüche kritisch und stellt DrEval vor, ein neues Evaluierungswerkzeug, das testet, wie gut solche Modelle in Situationen funktionieren, die echten medizinischen Entscheidungen ähneln. 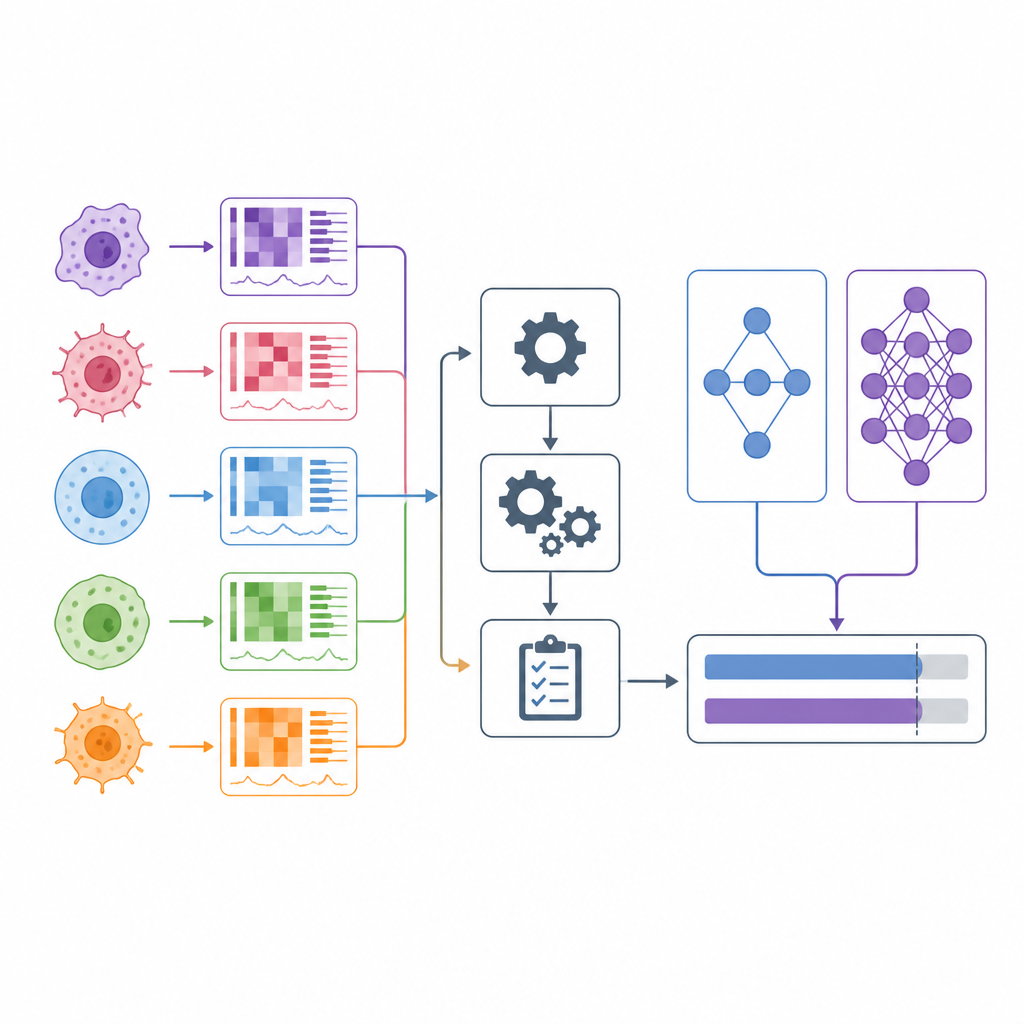
Wie Computer versuchen, den Erfolg von Medikamenten vorherzusagen
Modelle zur Vorhersage von Medikamentenwirkung lernen aus großen Screening-Projekten, in denen Krebszelllinien vielen Medikamenten in unterschiedlichen Dosen ausgesetzt werden und ihr Überleben gemessen wird. Forschende füttern jedes Modell mit detaillierten molekularen Profilen der Zelllinien und verschiedenen Beschreibungen der Medikamente und lassen es dann Standardzusammenfassungen vorhersagen, wie stark jedes Medikament das Zellwachstum hemmt. Einige Ansätze trainieren ein Modell pro Medikament, andere trainieren ein einziges Modell über viele Medikamente hinweg in der Hoffnung, auch Antworten für neue Wirkstoffe schätzen zu können. Auf dem Papier melden diese Methoden oft beeindruckende Genauigkeitszahlen, was den Eindruck erweckt, personalisierte Krebstherapie könnte in Reichweite sein.
Versteckte Fallstricke in aktuellen Bewertungen
Die Autorinnen und Autoren zeigen, dass diese optimistischen Ergebnisse oft durch die Art der Datenaufteilung und Bewertung entstehen und nicht durch echtes Verständnis der Krebsbiologie. Wenn dieselbe Zelllinie oder dasselbe Medikament sowohl in Trainings- als auch in Testsets vorkommt, kann das Modell schlicht typische Verhaltensmuster auswendig lernen, anstatt tiefere Zusammenhänge zu erfassen. Da verschiedene Medikamente in sehr unterschiedlichen Dosisbereichen wirken, kann ein Modell, das nur den durchschnittlichen Effekt pro Medikament auswendig lernt, bereits einen Großteil der Variation in den Daten erklären. Das schafft eine statistische Illusion, bei der die globale Genauigkeit hoch erscheint, obwohl das Modell nicht unterscheiden kann, welche konkreten Zelllinien gegenüber einem bestimmten Medikament empfindlicher oder widerstandsfähiger sind.
Was DrEval anders macht
DrEval ist ein offenes Benchmarking-Framework, das standardisiert, wie Modelle zur Vorhersage von Medikamentenwirkung getestet werden. Es stellt harmonisierte Datensätze, sorgfältige Datenbereinigung und mehrere realistische Testszenarien bereit, die gängige Ziele widerspiegeln: Vorhersagen für neue Patienten (neue Zelllinien), für neue Krebsarten (neue Gewebearten) oder für völlig neue Medikamente. Es enthält auch einfache Basismethoden, etwa einen Prädiktor, der nur die durchschnittlichen Effekte jedes Medikaments und jeder Zelllinie nutzt, sowie baumbasierte Modelle, die wesentlich leichter zu trainieren sind als tiefe neuronale Netze. DrEval führt alle Modelle unter demselben Cross-Validation- und Tuning-Schema aus und berichtet Ergebnisse mit Metriken, die den irreführenden Einfluss durchschnittlicher Medikamenten- und Zelllinieneffekte entfernen. 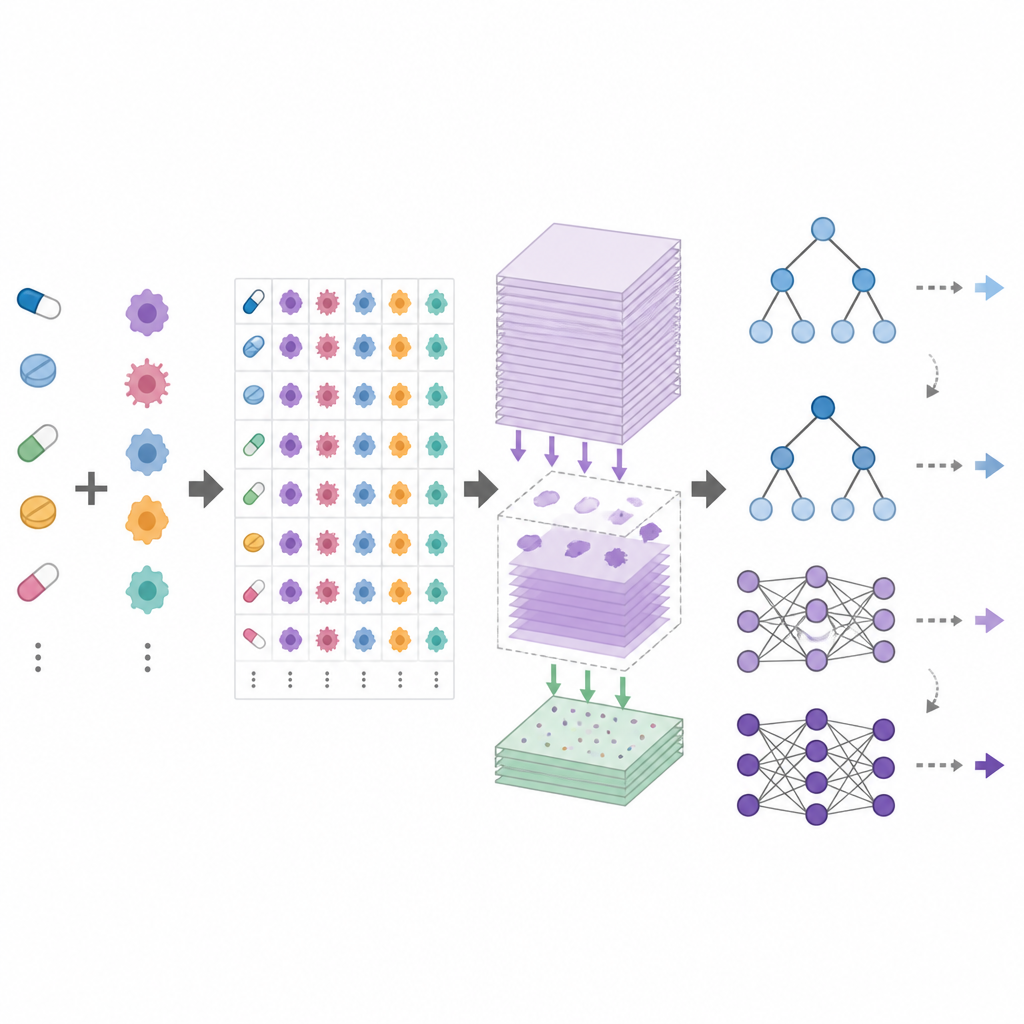
Was die Tests über heutige Modelle offenbaren
Als die Autorinnen und Autoren eine breite Palette moderner Modelle mit DrEval prüften, stellten sie fest, dass viele Modelle kaum besser abschnitten als der naive Prädiktor, der lediglich das mittlere Verhalten von Medikamenten und Zelllinien nutzt. In für Patienten relevanten Szenarien, in denen Modelle mit zuvor ungesehenen Zelllinien umgehen müssen, erzielten sorgfältig abgestimmte, baumbasierte Ensembles wie Random Forests gleich gute oder bessere Ergebnisse als komplexe tiefe Netzwerke. Alle Methoden versagten, wenn sie aufgefordert wurden, die Wirkung von Medikamenten vorherzusagen, die nicht zu ihren Trainingsdaten gehörten, und die Leistung fiel stark ab, wenn man von einer Screening-Studie zur nächsten wechselte oder von Zelllinien zu realistischeren Proben von Patientinnen und Patienten ging. Sorgfältige „Ablations“-Experimente zeigten, dass der überwiegende Teil des nützlichen Signals aus einfachen Genaktivitätsmessungen stammt, während zusätzliche Datenschichten und aufwändige Medikamentencodierungen oft wenig beitragen.
Warum das für die zukünftige Krebstherapie wichtig ist
Die Hauptbotschaft der Studie ist, dass die zuverlässige Vorhersage der Wirkung von Krebsmedikamenten weiterhin ein ungelöstes Problem bleibt. Viele frühere Erfolgsmeldungen wurden durch verzerrte Bewertungen aufgebauscht und nicht durch echte Vorhersagekraft. Indem DrEval diese Probleme sichtbar macht und eine gemeinsame, reproduzierbare Testumgebung bereitstellt, hilft es dem Feld, sich auf Methoden zu konzentrieren, die wirklich lernen, wie Krebs auf Behandlungen reagiert, anstatt Abkürzungen in den Daten auszunutzen. Für Patientinnen und Patienten bedeutet das: Computermodelle sind noch nicht bereit, routinemäßig die Medikamentenauswahl zu steuern, aber der Weg zu verlässlichen Werkzeugen ist klarer: bessere Daten, strengere Tests und faire Vergleiche zwischen einfachen und komplexen Modellen.
Zitation: Bernett, J., Iversen, P., Picciani, M. et al. Critical evaluation of drug response prediction models with DrEval. Nat Commun 17, 4238 (2026). https://doi.org/10.1038/s41467-026-72903-w
Schlüsselwörter: Vorhersage der Medikamentenwirkung, Krebszelllinien, Maschinelles Lernen, Benchmarking, Modellevaluation