Clear Sky Science · ru
Дизайн, структура и бенчмарк средств контроля безопасности для «черных ящиков»-классификаторов
Почему важны безопасные машинные решения
Все чаще машины помогают управлять автомобилями, направлять хирургические инструменты, следить за заводами и проверять критическую инфраструктуру. Все эти задачи зависят от программ, которые анализируют данные и выбирают между вариантами, например «безопасно» или «небезопасно». Когда такое суждение ошибочно, это может привести к пропущенному нарушителю, неверно интерпретированному сигналу светофора или невыявленному сбою детали. В этой статье исследуется, как окружить такое программное обеспечение для принятия решений дополнительным уровнем защиты, чтобы рискованные ответы отмечались и блокировались, а не принимались на веру.
От идеальных ответов к доверяемому поведению
Большинство исследований в области искусственного интеллекта стремятся сделать классификаторы как можно точнее, но даже лучшие системы по-прежнему ошибаются. Люди‑эксперты тоже иногда неверно оценивают ситуации, однако мы продолжаем полагаться на них, потому что они обычно знают, когда стоит попросить помощи. Авторы утверждают, что машинные механизмы принятия решений должны вести себя похожим образом. Вместо того чтобы заставлять классификатор всегда выдает метку, ему следует позволить сказать «я не уверен» и дать большой системе отреагировать безопасным образом. На практике это означает превращение непредсказуемых ошибочных ответов в контролируемые отклонения, с которыми другие части системы могут справиться — например, замедлить движение транспортного средства, запросить ввод человека или переключиться в более безопасный режим.
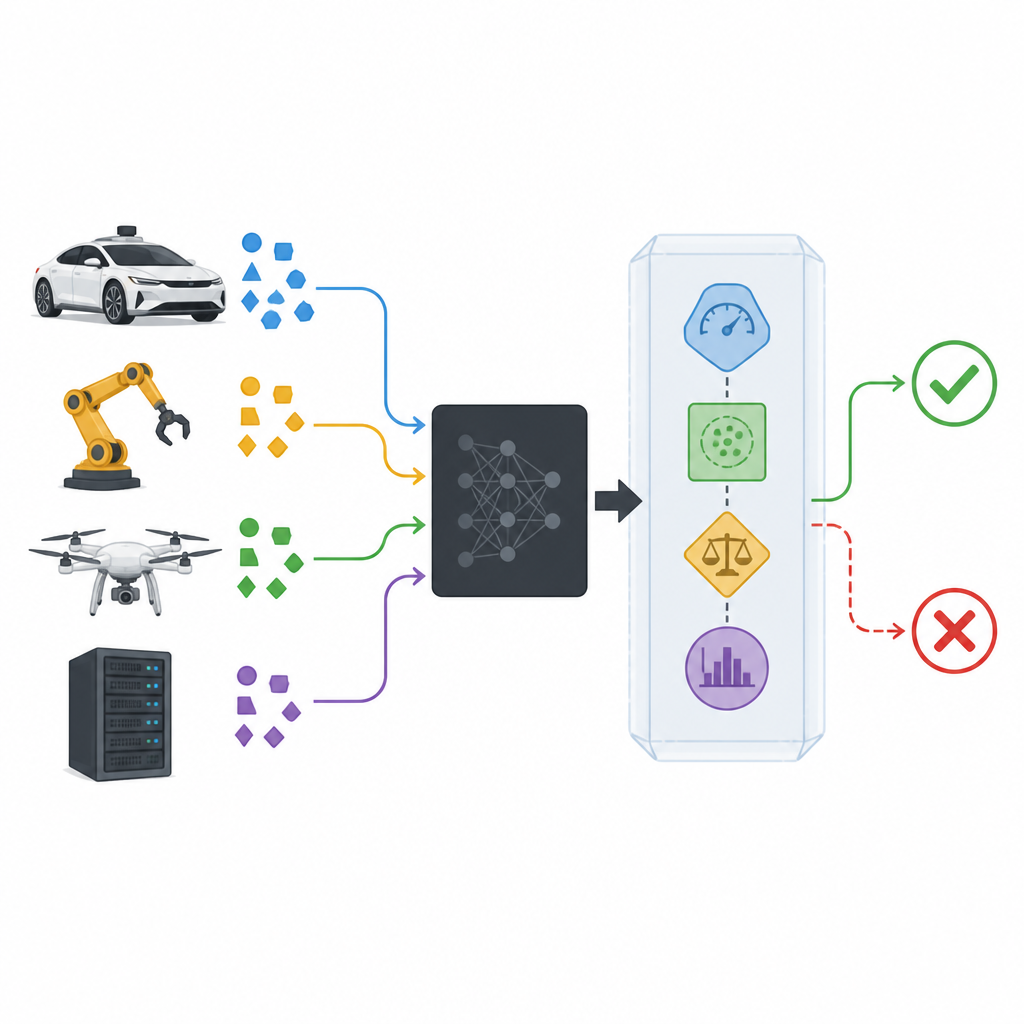
Добавление защитной оболочки вокруг моделей «черного ящика»
Современные классификаторы часто рассматриваются как «черные ящики»: они принимают данные и возвращают предсказание, а их внутренности скрыты или слишком сложны для анализа. Предложенная защитная оболочка, называемая SPROUT, располагается вокруг такого «черного ящика» без необходимости заглядывать внутрь. Она отслеживает каждый новый вход, вероятности, которые классификатор назначает возможным классам, и то, как этот вход соотносится с прошлым опытом. Исходя из этой информации, SPROUT решает, достаточно ли доверительным кажется предсказание, чтобы передать его дальше, или его следует отклонить как подозрительное. Главное — почти любой существующий классификатор для изображений или табличных данных, бинарных или многоклассовых, можно обернуть таким образом, если он способен выдавать вероятности по классам.
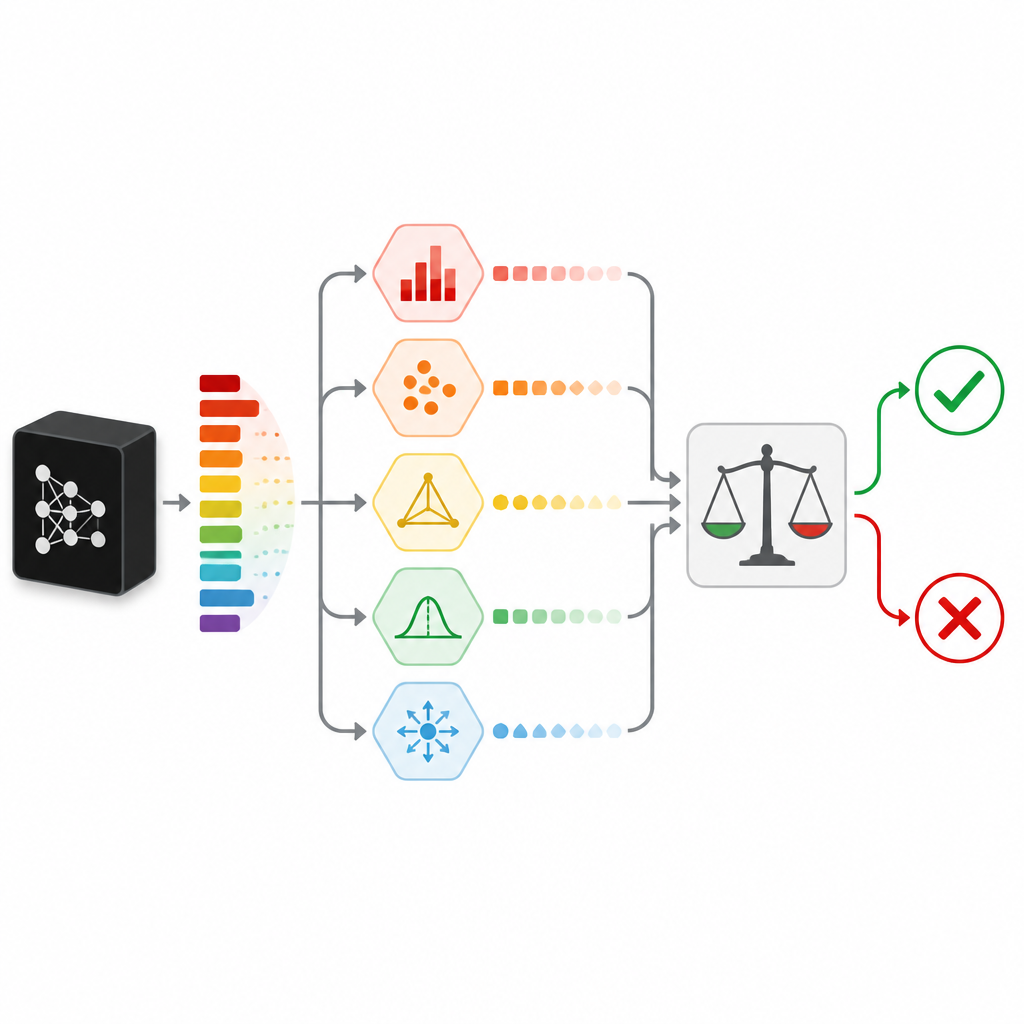
Измерение сомнений разными способами
Чтобы оценить, насколько уверенным действительно является предсказание, SPROUT не полагается на один сигнал. Вместо этого он комбинирует несколько «мер неопределенности», каждая из которых рассматривает сомнение с другого ракурса. Некоторые проверяют простые признаки, например выделяется ли одна вероятность класса или же вероятности равномерно распределены. Другие сравнивают ответ классификатора с ответами дополнительных «проверяющих» моделей, обученных на тех же данных, или с ответами, полученными для соседних точек данных в обучающем наборе. Еще одна мера пытается восстановить вход с помощью автоэнкодера и рассматривает плохую реконструкцию как признак того, что новые данные отличаются от всего, что встречалось ранее. В совокупности эти меры формируют компактную таблицу чисел, которую небольшой модель второго уровня, называемый арбитром, преобразует в простое решение — пропустить или отклонить.
Тестирование на многих наборах данных и типах моделей
Авторы провели крупное экспериментальное исследование с использованием 35 общедоступных наборов данных, охватывающих сетевые атаки, биометрическое подделывание, аппаратные отказы, датчики Интернета вещей и несколько популярных наборов изображений. Они опробовали более 20 типов классификаторов, как с учителем, так и без, и построили отдельные конфигурации SPROUT для табличных данных и изображений. В каждом случае они измеряли, как часто исходный классификатор ошибался и как часто SPROUT успевал отклонить эти ошибочные ответы до того, как они могли вырваться наружу. Для многих задач с учителем, включая некоторые задачи с изображениями, SPROUT существенно снизил остаточную ошибку. В отдельных случаях, например для логистической регрессии на наборе данных по сетевой безопасности, он отклонил каждую единственную ошибочную классификацию, превращая временами ненадежный компонент в тот, чьи выходы можно доверять, когда они не отклонены.
Баланс между безопасностью, доступностью и стоимостью
Разумеется, ловля большего числа ошибок часто означает и отклонение большего числа правильных ответов, а вычисление множества мер неопределенности добавляет временные и ресурсные накладные расходы. Исследование показывает, что SPROUT обычно делает супервизированные классификаторы примерно в четыре–пять раз медленнее и что некоторые меры дороже других. Это указывает на компромисс в дизайне: системы, критичные с точки зрения безопасности, могут принять дополнительную задержку и большее число отклонений, чтобы избежать вредных последствий, в то время как чувствительные к времени или ограниченные в ресурсах приложения могут выбрать меньший набор недорогих проверок. Авторы также выделяют, какие меры важны на практике, давая рекомендации по созданию облегченых версий при необходимости.
Что это означает для более безопасного ИИ на практике
Проще говоря, главный вывод статьи в том, что не стоит ожидать безупречных машинных решений; вместо этого нужно требовать, чтобы системы знали, когда они могут ошибаться. SPROUT предлагает практическую схему для оборачивания существующих классификаторов «черного ящика» в щит, учитывающий сомнения и отклоняющий подозрительные выводы до того, как они принесут вред. Хотя такая защита требует дополнительных вычислений и иногда приводит к потере корректных предсказаний, результаты показывают, что она может значительно снизить вероятность того, что опасная ошибка проскользнет незамеченной, делая принятие решений на основе ИИ более надежным в реальном мире.
Цитирование: Khokhar, F.A., Zoppi, T., Cennini, L. et al. Design, framework and benchmark of safety monitors for black-box classifiers. Sci Rep 16, 15626 (2026). https://doi.org/10.1038/s41598-026-45091-2
Ключевые слова: Безопасность ИИ, неопределенность, доверенный ИИ, монитор машинного обучения, фреймворк SPROUT