Clear Sky Science · it
Progettazione, framework e benchmark dei monitor di sicurezza per classificatori black-box
Perché le decisioni automatiche sicure sono importanti
Sempre più spesso le macchine aiutano a guidare automobili, orientare strumenti chirurgici, sorvegliare fabbriche e ispezionare infrastrutture critiche. Tutti questi compiti dipendono da software che osserva dati e sceglie tra opzioni, ad esempio “sicuro” o “non sicuro”. Quando quel giudizio è sbagliato, il risultato può essere un intruso non rilevato, un semaforo interpretato male o una parte guasta non individuata. Questo articolo esplora come circondare tale software decisionale con un ulteriore strato di protezione in modo che risposte rischiose vengano segnalate e bloccate invece di essere accettate ciecamente.
Dalle risposte perfette a un comportamento degno di fiducia
La maggior parte del lavoro sull’intelligenza artificiale cerca di rendere i classificatori il più accurati possibile, ma anche i sistemi migliori commettono errori. Anche gli esperti umani giudicano male certe situazioni, eppure ci affidiamo a loro perché di solito sanno quando chiedere aiuto. Gli autori sostengono che i decisori automatici dovrebbero comportarsi in modo più simile. Invece di costringere un classificatore a scegliere sempre un’etichetta, dovrebbe potergli essere permesso di dire “Non sono sicuro” e lasciare che il sistema più ampio reagisca in modo sicuro. In pratica, questo significa trasformare risposte sbagliate e imprevedibili in rifiuti controllati che altre parti del sistema possono gestire, ad esempio rallentando un veicolo, chiedendo l’intervento umano o passando a una modalità più sicura.
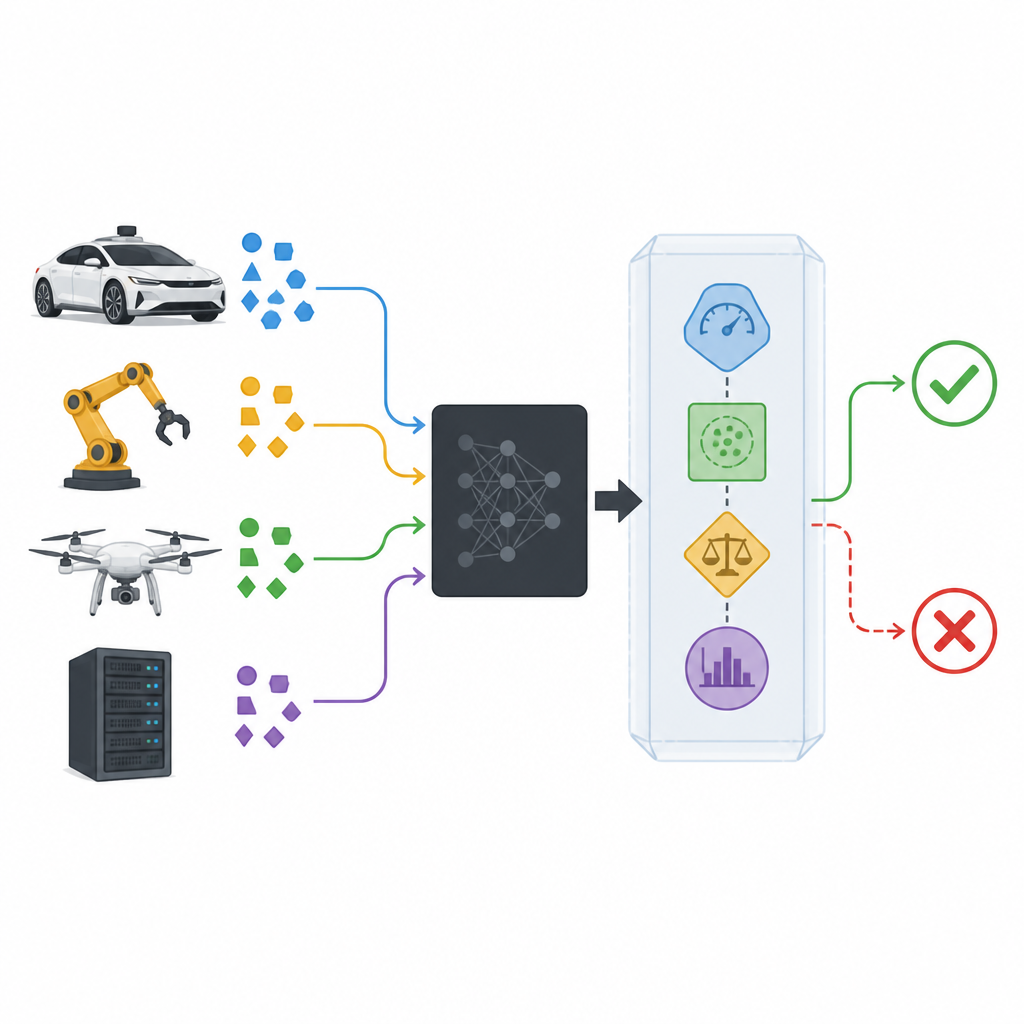
Aggiungere un wrapper di sicurezza attorno a modelli black box
I classificatori moderni sono spesso trattati come scatole nere: ricevono dati e producono una predizione, mentre il loro funzionamento interno rimane nascosto o troppo complesso da ispezionare. Il wrapper di sicurezza proposto, chiamato SPROUT, si pone attorno a tale scatola nera senza bisogno di guardare dentro. Osserva ogni nuovo input, le probabilità che il classificatore assegna alle classi possibili e come quell’input si confronta con dati passati. Da queste informazioni, SPROUT decide se una predizione sembra sufficientemente affidabile da essere trasmessa, o se dovrebbe essere rifiutata come sospetta. Il punto chiave è che quasi qualsiasi classificatore esistente, per immagini o tabelle di numeri, binario o multi-classe, può essere avvolto in questo modo purché possa fornire probabilità di classe.
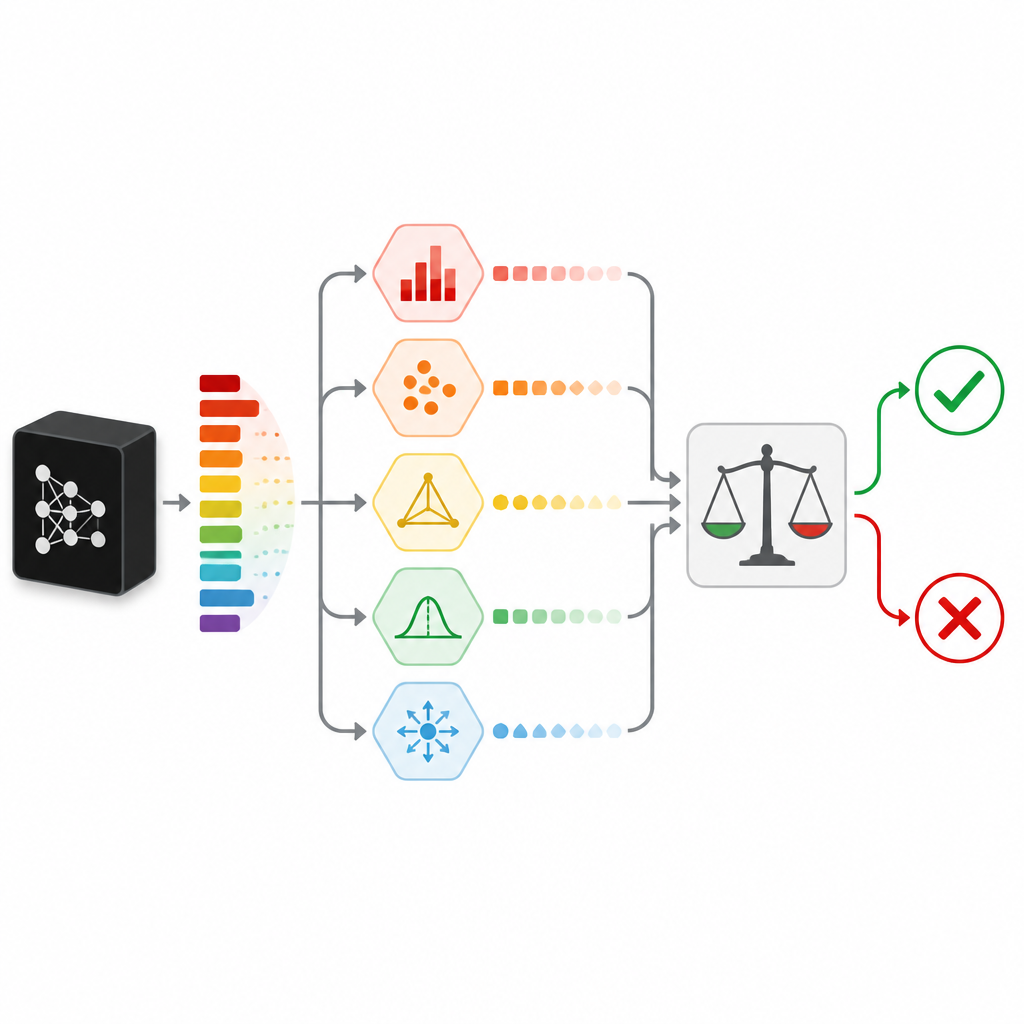
Misurare il dubbio in modi diversi
Per valutare quanto una predizione sia realmente confidente, SPROUT non si affida a un unico segnale. Invece, combina diverse “misure di incertezza” che osservano il dubbio da angolazioni diverse. Alcune controllano segni semplici, come se una probabilità di classe spicchi davvero o se le probabilità siano distribuite uniformemente. Altre confrontano la risposta del classificatore con quella di modelli “checker” addestrati sugli stessi dati, o con le risposte date a punti dati vicini nel set di addestramento. Un’altra misura tenta di ricostruire l’input usando una rete autoencoder e considera una ricostruzione scadente come un indizio che i nuovi dati sono diversi da quelli visti prima. Insieme queste misure formano una tavola compatta di numeri che un piccolo modello di secondo livello, chiamato giudicatore, converte in una semplice decisione di conservare o rifiutare.
Test su molti dataset e tipi di modelli
Gli autori hanno svolto un ampio studio sperimentale utilizzando 35 dataset pubblici, coprendo attacchi di rete, spoofing biometrici, guasti hardware, sensori Internet of Things e diversi noti set di immagini. Hanno provato più di 20 tipi di classificatori, sia supervisionati sia non supervisionati, e costruito configurazioni SPROUT separate per dati tabellari e immagini. Per ciascun caso hanno misurato quanto spesso il classificatore originale sbagliava e quante di quelle risposte sbagliate SPROUT riusciva a rifiutare prima che potessero sfuggire. Per molti compiti supervisionati, inclusi alcuni problemi su immagini, SPROUT ha ridotto drasticamente il tasso di errore residuo. In certi casi, come una regressione logistica su un dataset di sicurezza di rete, ha rifiutato ogni singola misclassificazione, trasformando un componente talvolta inaffidabile in uno le cui uscite possono essere considerate affidabili quando non vengono rifiutate.
Bilanciare sicurezza, disponibilità e costo
Naturalmente, catturare più errori spesso significa anche rifiutare più risposte corrette, e il calcolo di molte misure di incertezza aggiunge tempo e risorse. Lo studio mostra che SPROUT in genere rende i classificatori supervisionati circa quattro-cinque volte più lenti e che alcune misure sono più costose di altre. Questo suggerisce un compromesso progettuale: i sistemi critici per la sicurezza potrebbero accettare ritardi aggiuntivi e più rifiuti per evitare esiti dannosi, mentre applicazioni sensibili al tempo o con risorse limitate potrebbero scegliere un insieme più piccolo di controlli economici. Gli autori identificano anche quali misure contano di più in pratica, offrendo indicazioni su come costruire versioni più leggere quando necessario.
Che cosa significa per un’IA più sicura in pratica
In termini semplici, il messaggio principale dell’articolo è che dovremmo smettere di aspettarci decisioni automatiche perfette e invece pretendere che i nostri sistemi sappiano quando potrebbero sbagliare. SPROUT offre un progetto pratico per avvolgere i classificatori black box esistenti con uno scudo consapevole del dubbio che rifiuta uscite sospette prima che causino danni. Sebbene questa protezione comporti calcoli aggiuntivi e la perdita occasionale di predizioni valide, i risultati mostrano che può ridurre notevolmente la probabilità che un errore pericoloso passi inosservato, rendendo il processo decisionale basato su IA più affidabile nel mondo reale.
Citazione: Khokhar, F.A., Zoppi, T., Cennini, L. et al. Design, framework and benchmark of safety monitors for black-box classifiers. Sci Rep 16, 15626 (2026). https://doi.org/10.1038/s41598-026-45091-2
Parole chiave: Sicurezza dell’IA, incertezza, IA affidabile, monitor per machine learning, framework SPROUT