Clear Sky Science · ar
تصميم وإطار عمل ومعيار لمراقِبي الأمان لمصنِّفات الصناديق السوداء
لماذا تهمّ قرارات الآلات الآمنة
تتزايد مهام الآلات في قيادة السيارات، وتوجيه الأدوات الجراحية، ومراقبة المصانع، وفحص البُنى التحتية الحرِجة. جميع هذه المهام تعتمد على برمجيات تدرس بيانات وتختار بين خيارات مثل «آمن» أو «غير آمن». عندما يكون هذا الحكم خاطئًا، قد يؤدي ذلك إلى غفلة عن متسلل، أو قراءة خاطئة لإشارة مرورية، أو فشل جزء غير مكتشف. تستكشف هذه الورقة كيفية إحاطة مثل هذه برمجيات القرار بطبقة حماية إضافية بحيث تُعلَم الإجابات عالية المخاطر وتُحجَب بدلًا من الوثوق بها بلا تمحيص.
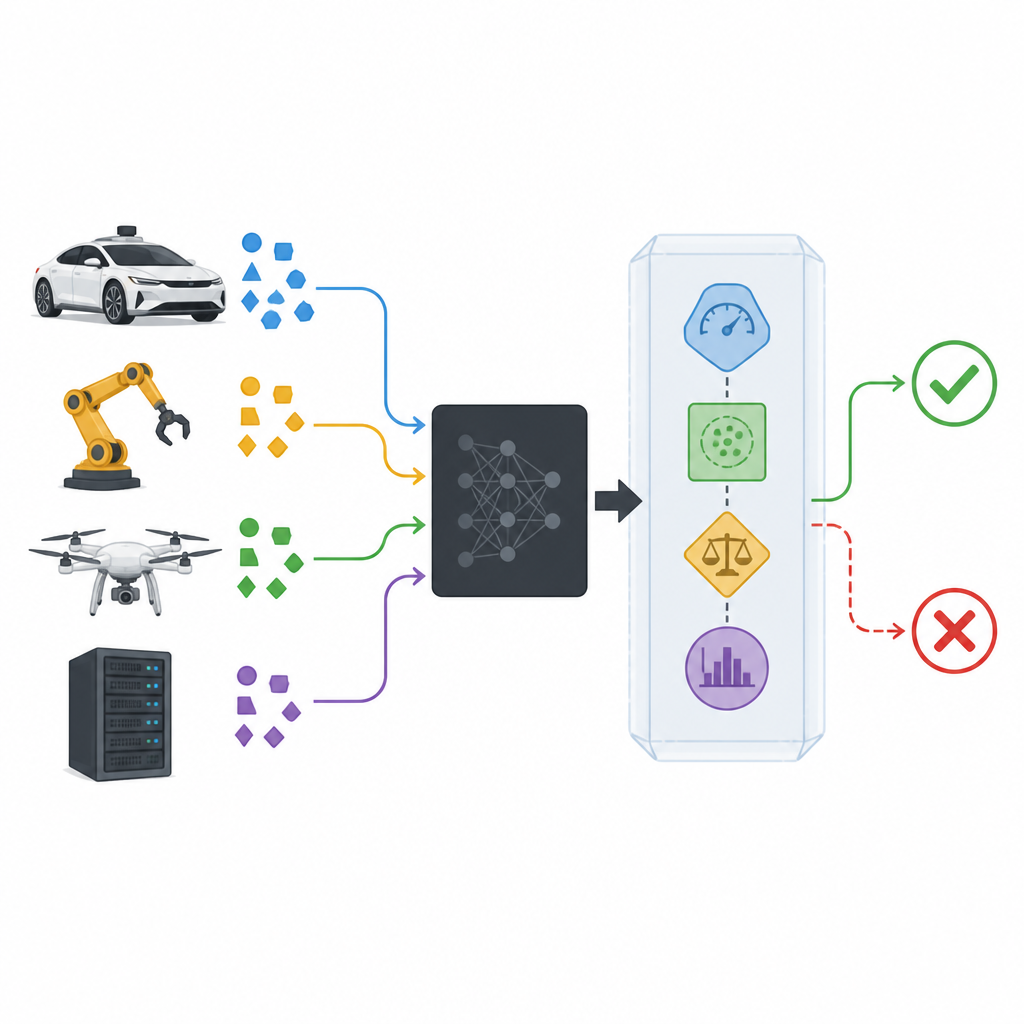
من الإجابات المثالية إلى السلوك الموثوق
تركز معظم الأعمال في الذكاء الاصطناعي على جعل المصنِّفات دقيقة قدر الإمكان، لكن حتى أفضل الأنظمة تُخطئ أحيانًا. كما أن الخبراء البشر يخطئون، ومع ذلك نعتمد عليهم لأنهم عادةً يعرفون متى يطلبون المساعدة. يجادل المؤلفون بوجوب أن تتصرف آليات اتخاذ القرار الآلية بطريقة مشابهة. بدلًا من إجبار المصنِّف على اختيار تسمية دائمًا، ينبغي أن يُسمَح له بالقول «لست متأكدًا» وترك النظام الأكبر يتفاعل بأمان. عمليًا، يعني هذا تحويل الأخطاء غير المتوقعة إلى رفضات متحكّم بها يمكن لأجزاء النظام الأخرى التعامل معها، مثل تبطيء مركبة أو طلب تدخل بشري أو التحوّل إلى وضع أكثر أمانًا.
إضافة غلاف أمان حول نماذج الصندوق الأسود
تعامل المصنِّفات الحديثة غالبًا كصناديق سوداء: تستقبل بيانات وتُعطي تنبؤًا بينما تبقى آلياتها الداخلية مخفية أو معقَّدة جدًا للفحص. يجلس غلاف الأمان المقترح، المُسمى SPROUT، حول مثل هذا الصندوق الأسود دون حاجة للاطلاع على تفصيلاته الداخلية. يراقب كل مدخل جديد، والاحتمالات التي يعطيها المصنِّف للفئات المحتملة، وكيف يقارن ذلك المدخل بالبيانات السابقة. من هذه المعطيات يقرِّر SPROUT ما إذا كان التنبؤ جديرًا بالثقة لتمريره أم يجب رفضه لوجود شبهة. النقطة الأساسية أن أي مصنِّف موجود تقريبًا، سواء للصور أو لجداول الأرقام، ثنائي أو متعدد الفئات، يمكن تغليفه بهذه الطريقة طالما أنه يمكنه إخراج احتمالات الفئات.
قياس الشك بطرق متعددة
للحكم على مدى ثقة التنبؤ فعليًا، لا يعتمد SPROUT على إشارة واحدة. بل يجمع عدة «مقاييس لعدم اليقين» ينظر كل منها إلى الشك من زاوية مختلفة. بعض المقاييس تفحص علامات بسيطة، مثل ما إذا كانت احتمالية فئة واحدة بارزة فعليًا أو ما إذا كانت الاحتمالات موزعة بشكل متساوٍ. يقارن البعض الآخر إجابة المصنِّف مع إجابات نماذج «متحققة» إضافية مدرَّبة على نفس البيانات، أو مع الإجابات المعطاة لنقاط بيانات مجاورة في مجموعة التدريب. يقيس مقياس آخر محاولة إعادة بناء المدخل عبر شبكة ترميز ذاتي (autoencoder) ويعتبر إعادة بناء ضعيفة إشارة إلى أن البيانات الجديدة قد تكون مختلفة عمَّا شوهد سابقًا. تشكل هذه المقاييس معًا جدولًا مُكثَّفًا من الأرقام يحوّله نموذج ثانوي صغير، يُدعى الحكم (adjudicator)، إلى قرار بسيط بالاحتفاظ أو الرفض.
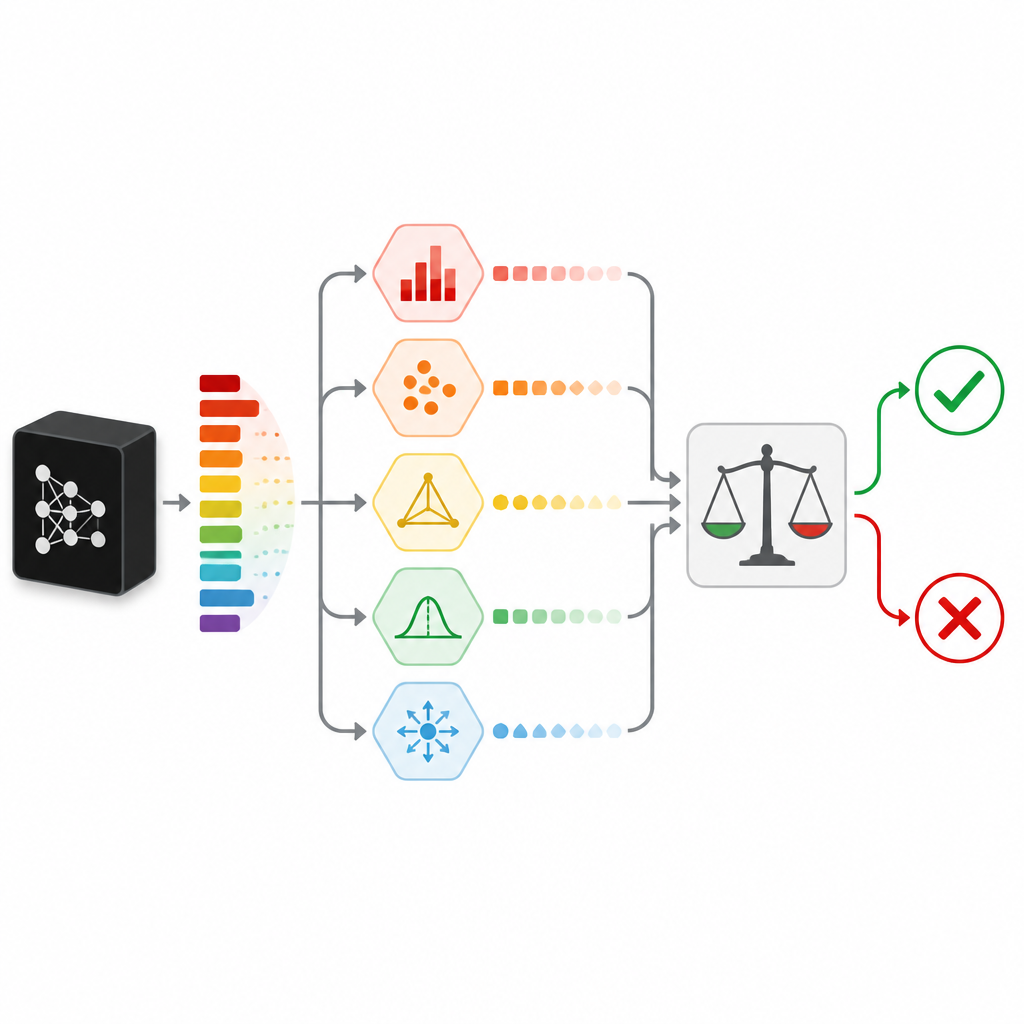
الاختبار عبر مجموعات بيانات وأنواع نماذج متعددة
أجرى المؤلفون دراسة تجريبية واسعة باستخدام 35 مجموعة بيانات متاحة للعامة، تغطي هجمات الشبكات، والتزييف البيومتري، وفشل الأجهزة، ومستشعرات إنترنت الأشياء والعديد من مجموعات الصور الشائعة. جرّبوا أكثر من 20 نوعًا من المصنِّفات، خاضعة وغير خاضعة للإشراف، وبنوا إعدادات SPROUT منفصلة للبيانات الجدولية والصور. في كل حالة، قاسوا عدد مرات خطأ المصنِّف الأصلي وعدد المرات التي نجح فيها SPROUT في رفض تلك الأخطاء قبل أن تهرب. في العديد من المهام الخاضعة للإشراف، بما في ذلك بعض مشكلات الصور، خفّض SPROUT بشكل كبير معدل الأخطاء المتبقي. في حالات معينة، مثل نموذج الانحدار اللوجستي على مجموعة بيانات أمان الشبكات، رفض كل خطأ تصنيف، محولًا مكوّنًا غير موثوق في بعض الأحيان إلى مكوّن يمكن الوثوق بمخرجاته عندما لا تُرفض.
موازنة الأمان والتوافر والتكلفة
بالطبع، كشف المزيد من الأخطاء غالبًا ما يعني رفض المزيد من الإجابات الصحيحة كذلك، وحساب عدة مقاييس لعدم اليقين يضيف وقتًا وتكاليف موارد. تُظهر الدراسة أن SPROUT يجعل المصنِّفات الخاضعة للإشراف أبطأ عادةً بمقدار أربع إلى خمس مرات وأن بعض المقاييس أكثر تكلفة من غيرها. هذا يشير إلى مقايضة تصميمية: قد تقبل الأنظمة الحرجة أمنيًا تأخيرًا إضافيًا ومزيدًا من الرفض لتجنّب النتائج الضارة، بينما قد تختار التطبيقات الحساسة للزمن أو المحدودة الموارد مجموعة أصغر من الاختبارات الرخيصة. كما يحدد المؤلفون أي المقاييس هي الأهم عمليًا، ما يقدم إرشادًا لبناء نسخ أخف عند الحاجة.
ماذا يعني هذا لأجل ذكاء اصطناعي أكثر أمانًا على أرض الواقع
بعبارات بسيطة، الرسالة الأساسية للورقة هي أنه ينبغي علينا التوقف عن توقع قرارات آلية خالية من الخطأ وبدلاً من ذلك المطالبة بأن تعلم أنظمتنا متى قد تكون مخطئة. يقدم SPROUT مخططًا عمليًا لتغليف المصنِّفات الصندوق الأسود القائمة بدرع واعٍ للشك يرفض المخرجات المشبوهة قبل أن تتسبب في ضرر. ومع أن هذه الحماية تأتي بتكاليف حسابية وخسارة عرضية لبعض التنبؤات الصحيحة، تُظهر النتائج أنها يمكن أن تقلل كثيرًا احتمالية تسريب خطأ خطير دون أن يُكتشف، مما يجعل اتخاذ القرار المعتمد على الذكاء الاصطناعي أكثر موثوقية في العالم الواقعي.
الاستشهاد: Khokhar, F.A., Zoppi, T., Cennini, L. et al. Design, framework and benchmark of safety monitors for black-box classifiers. Sci Rep 16, 15626 (2026). https://doi.org/10.1038/s41598-026-45091-2
الكلمات المفتاحية: أمان الذكاء الاصطناعي, عدم اليقين, ذكاء اصطناعي موثوق, مراقب التعلُّم الآلي, إطار عمل SPROUT