Clear Sky Science · ja
ブラックボックス分類器の安全モニターの設計、枠組み、ベンチマーク
なぜ機械の判断の安全性が重要か
機械はますます自動車の運転、手術器具の誘導、工場の監視、重要インフラの検査を支援するようになっています。これらの作業はいずれもデータを見て「安全」か「危険」かなどを選ぶソフトウェアに依存しています。その判断が誤ると、侵入者の見逃し、信号の誤読、故障部品の未検知といった事態を招く可能性があります。本論文は、そのような判断ソフトウェアの周りに追加の保護層を設け、危険な回答を盲目的に信頼するのではなくフラグを立てて差し止める方法を検討します。
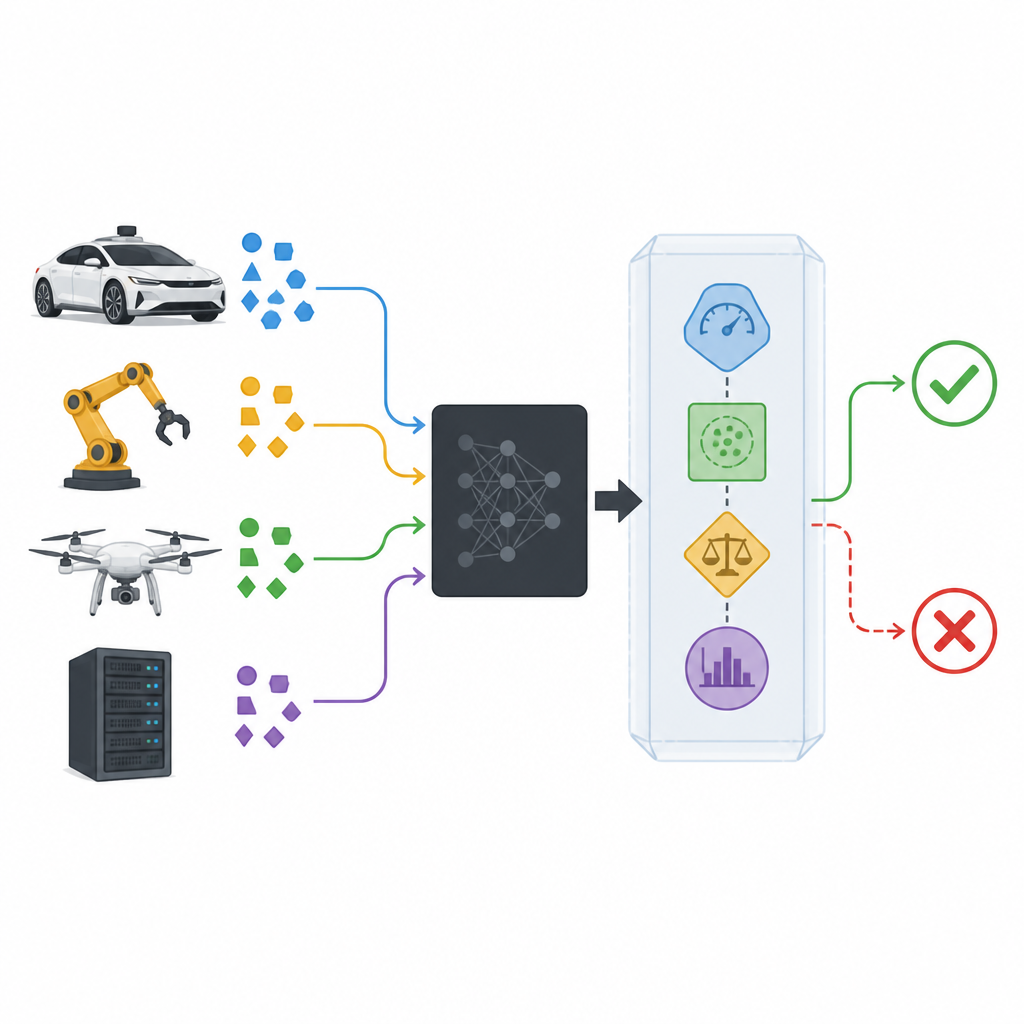
完璧な答えから信頼できる振る舞いへ
人工知能に関する多くの研究は分類器の精度向上を目指しますが、最良のシステムでも誤りを犯します。人間の専門家も状況を誤判断しますが、助けを求めるべき時を自覚しているために我々は依然として彼らを頼ります。著者らは機械の意思決定者もそのように振る舞うべきだと主張します。分類器に常にラベルを選ばせ続けるのではなく、「確信が持てない」と言えるようにして、上位のシステムが安全に対応できるようにすべきだ、ということです。実際には、予測の中の予測不能な誤答を、車両の減速、人間への入力要求、安全なモードへの切り替えなど、他のシステム部品で処理できる制御された拒否へと変えることを意味します。
ブラックボックスモデルの周りに安全ラッパーを追加する
現代の分類器は多くの場合ブラックボックスとして扱われます。データを受け取り予測を出す一方で、その内部構造は隠されているか解析が困難です。提案された安全ラッパーSPROUTは、内部を覗かなくてもそのようなブラックボックスの周りに配置できます。SPROUTは各入力、分類器が割り当てるクラス確率、そしてその入力が過去データとどのように比較されるかを観察します。これらの情報から、予測が十分に信頼できるか、疑わしく拒否すべきかを判断します。重要なのは、画像でも表形式の数値でも、二値でも多クラスでも、クラス確率を出力できる既存のほとんどの分類器をこの方法でラップできる点です。
多様な方法で疑念を測る
予測の確信度を判断するために、SPROUTは単一の信号に依存しません。代わりに、不確かさを異なる角度から見るいくつかの「不確かさ指標」を組み合わせます。ある指標は、一つのクラス確率が明確に抜きん出ているか、確率が均等に分散しているかといった単純な兆候をチェックします。別の指標は、同じデータで訓練した追加の「チェッカーモデル」の答えや、訓練セット内の近傍データに与えた答えと比較します。さらに別の指標はオートエンコーダを使って入力を再構成し、再構成が悪い場合はその新しいデータがこれまで見たものと異なる兆候と見なします。これらの指標はコンパクトな数値の表を構成し、小さな二次モデル(判定器)がそれを単純な保持か拒否かの決定に変換します。
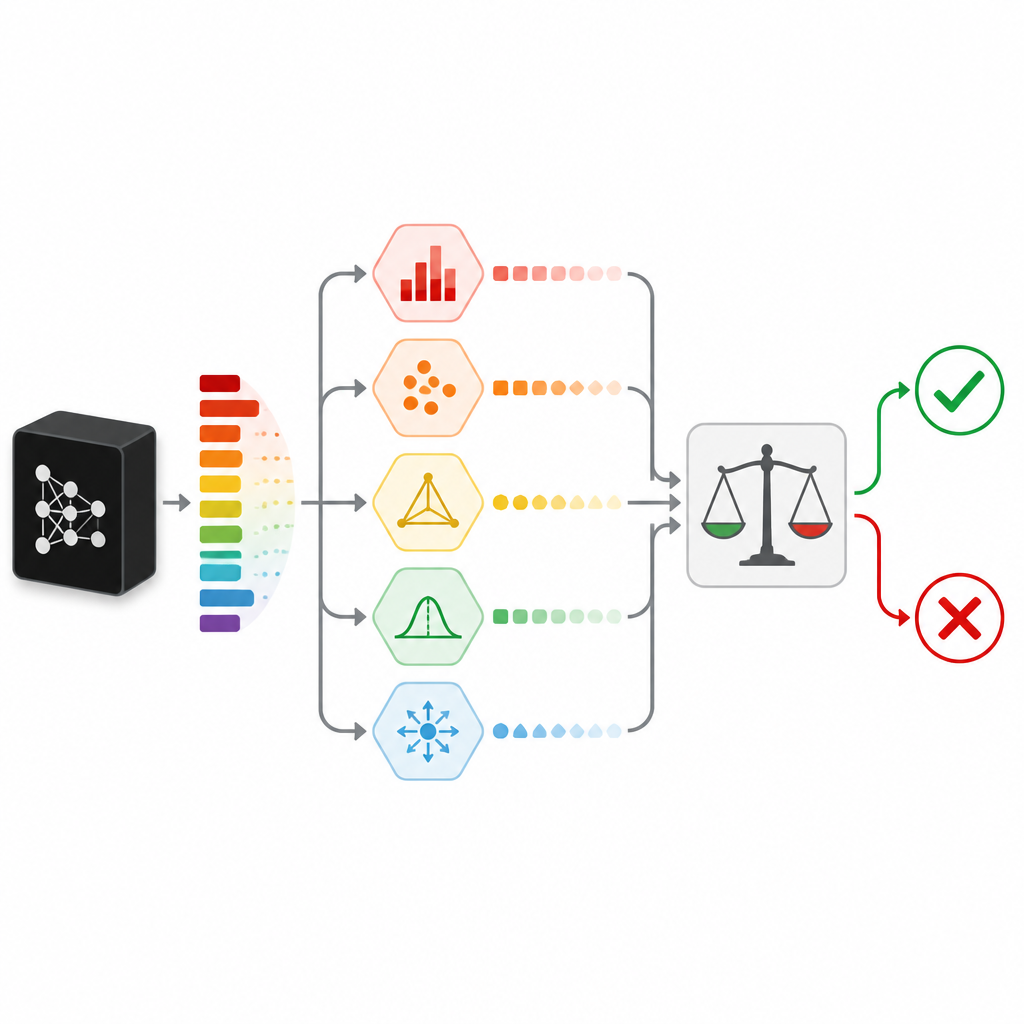
多くのデータセットとモデル種でのテスト
著者らはネットワーク攻撃、生体認証のなりすまし、ハードウェア障害、IoTセンサー、いくつかの代表的な画像セットを含む35の公開データセットを用いた大規模な実験を行いました。監視付き・非監視付きを含む20種類以上の分類器を試し、表形式データと画像それぞれに対して別個のSPROUT構成を構築しました。各ケースで、元の分類器が誤る頻度と、SPROUTがそれらの誤答を逃す前にどれだけ拒否できたかを測定しました。多くの監視付きタスク、特に一部の画像問題では、SPROUTは残存誤差率を劇的に削減しました。あるケースでは、ネットワークセキュリティのデータセット上のロジスティック回帰モデルに対して、すべての誤分類を拒否し、時に信頼できないコンポーネントを、拒否されていない出力は信頼できるものに変えました。
安全性、可用性、コストのバランス
もちろん、より多くの誤りを捉えることは正しい答えをより多く拒否することにもつながり、複数の不確かさ指標を計算することは時間と資源のオーバーヘッドを増やします。研究は、SPROUTが通常監視付き分類器を約4〜5倍遅くすること、そしていくつかの指標が他よりコストが高いことを示しています。これは設計上のトレードオフを示唆します:安全性が極めて重要なシステムは有害な結果を避けるために追加の遅延とより多くの拒否を受け入れるかもしれませんが、時間に敏感なアプリケーションや資源制約のある用途は低コストのチェックのより小さな集合を選ぶでしょう。著者らは実践で重要な指標も特定しており、必要に応じて軽量版を構築するための指針を提供します。
実践におけるより安全なAIへの含意
平たく言えば、本論文の主なメッセージは、機械の判断に完璧さを期待するのをやめ、代わりにシステムが誤る可能性を自覚することを求めるべきだ、ということです。SPROUTは既存のブラックボックス分類器を疑念に気付くシールドで包み、疑わしい出力が被害を引き起こす前に拒否するための実用的な設計図を提供します。この保護は追加の計算と時折の正当な予測の喪失を伴いますが、結果は危険な誤りが見過ごされる可能性を大幅に減らし、実世界でのAIベース意思決定の信頼性を高め得ることを示しています。
引用: Khokhar, F.A., Zoppi, T., Cennini, L. et al. Design, framework and benchmark of safety monitors for black-box classifiers. Sci Rep 16, 15626 (2026). https://doi.org/10.1038/s41598-026-45091-2
キーワード: AIの安全性, 不確かさ, 信頼できるAI, 機械学習モニタ, SPROUTフレームワーク